 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Large Language Models in Mission-Critical IT Governance: Are We Ready Yet?
Dec 16, 2024Context. The security of critical infrastructure has been a fundamental concern since the advent of computers, and this concern has only intensified in today's cyber warfare landscape. Protecting mission-critical systems (MCSs), including essential assets like healthcare, telecommunications, and military coordination, is vital for national security. These systems require prompt and comprehensive governance to ensure their resilience, yet recent events have shown that meeting these demands is increasingly challenging. Aim. Building on prior research that demonstrated the potential of GAI, particularly Large Language Models (LLMs), in improving risk analysis tasks, we aim to explore practitioners' perspectives, specifically developers and security personnel, on using generative AI (GAI) in the governance of IT MCSs seeking to provide insights and recommendations for various stakeholders, including researchers, practitioners, and policymakers. Method. We designed a survey to collect practical experiences, concerns, and expectations of practitioners who develop and implement security solutions in the context of MCSs. Analyzing this data will help identify key trends, challenges, and opportunities for introducing GAIs in this niche domain. Conclusions and Future Works. Our findings highlight that the safe use of LLMs in MCS governance requires interdisciplinary collaboration. Researchers should focus on designing regulation-oriented models and focus on accountability; practitioners emphasize data protection and transparency, while policymakers must establish a unified AI framework with global benchmarks to ensure ethical and secure LLMs-based MCS governance.
Beyond Words: On Large Language Models Actionability in Mission-Critical Risk Analysis
Jun 11, 2024



Context. Risk analysis assesses potential risks in specific scenarios. Risk analysis principles are context-less; the same methodology can be applied to a risk connected to health and information technology security. Risk analysis requires a vast knowledge of national and international regulations and standards and is time and effort-intensive. A large language model can quickly summarize information in less time than a human and can be fine-tuned to specific tasks. Aim. Our empirical study aims to investigate the effectiveness of Retrieval-Augmented Generation and fine-tuned LLM in Risk analysis. To our knowledge, no prior study has explored its capabilities in risk analysis. Method. We manually curated \totalscenarios unique scenarios leading to \totalsamples representative samples from over 50 mission-critical analyses archived by the industrial context team in the last five years. We compared the base GPT-3.5 and GPT-4 models versus their Retrieval-Augmented Generation and fine-tuned counterparts. We employ two human experts as competitors of the models and three other three human experts to review the models and the former human expert's analysis. The reviewers analyzed 5,000 scenario analyses. Results and Conclusions. HEs demonstrated higher accuracy, but LLMs are quicker and more actionable. Moreover, our findings show that RAG-assisted LLMs have the lowest hallucination rates, effectively uncovering hidden risks and complementing human expertise. Thus, the choice of model depends on specific needs, with FTMs for accuracy, RAG for hidden risks discovery, and base models for comprehensiveness and actionability. Therefore, experts can leverage LLMs for an effective complementing companion in risk analysis within a condensed timeframe. They can also save costs by averting unnecessary expenses associated with implementing unwarranted countermeasures.
Leveraging Large Language Models for Preliminary Security Risk Analysis: A Mission-Critical Case Study
Mar 23, 2024
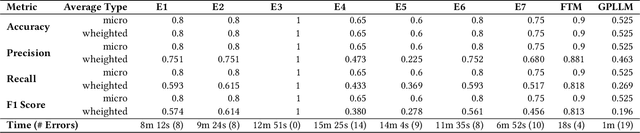
Preliminary security risk analysis (PSRA) provides a quick approach to identify, evaluate and propose remeditation to potential risks in specific scenarios. The extensive expertise required for an effective PSRA and the substantial ammount of textual-related tasks hinder quick assessments in mission-critical contexts, where timely and prompt actions are essential. The speed and accuracy of human experts in PSRA significantly impact response time. A large language model can quickly summarise information in less time than a human. To our knowledge, no prior study has explored the capabilities of fine-tuned models (FTM) in PSRA. Our case study investigates the proficiency of FTM to assist practitioners in PSRA. We manually curated 141 representative samples from over 50 mission-critical analyses archived by the industrial context team in the last five years.We compared the proficiency of the FTM versus seven human experts. Within the industrial context, our approach has proven successful in reducing errors in PSRA, hastening security risk detection, and minimizing false positives and negatives. This translates to cost savings for the company by averting unnecessary expenses associated with implementing unwarranted countermeasures. Therefore, experts can focus on more comprehensive risk analysis, leveraging LLMs for an effective preliminary assessment within a condensed timeframe.