 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Pipeline with Low-Rank Adaptation for New Language Integration in Multilingual ASR
Jun 12, 2024This paper addresses challenges in integrating new languages into a pre-trained multilingual automatic speech recognition (mASR) system, particularly in scenarios where training data for existing languages is limited or unavailable. The proposed method employs a dual-pipeline with low-rank adaptation (LoRA). It maintains two data flow pipelines-one for existing languages and another for new languages. The primary pipeline follows the standard flow through the pre-trained parameters of mASR, while the secondary pipeline additionally utilizes language-specific parameters represented by LoRA and a separate output decoder module. Importantly, the proposed approach minimizes the performance degradation of existing languages and enables a language-agnostic operation mode, facilitated by a decoder selection strategy. We validate the effectiveness of the proposed method by extending the pre-trained Whisper model to 19 new languages from the FLEURS dataset
TransfoRNN: Capturing the Sequential Information in Self-Attention Representations for Language Modeling
Apr 04, 2021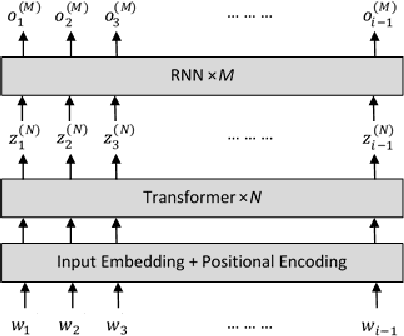
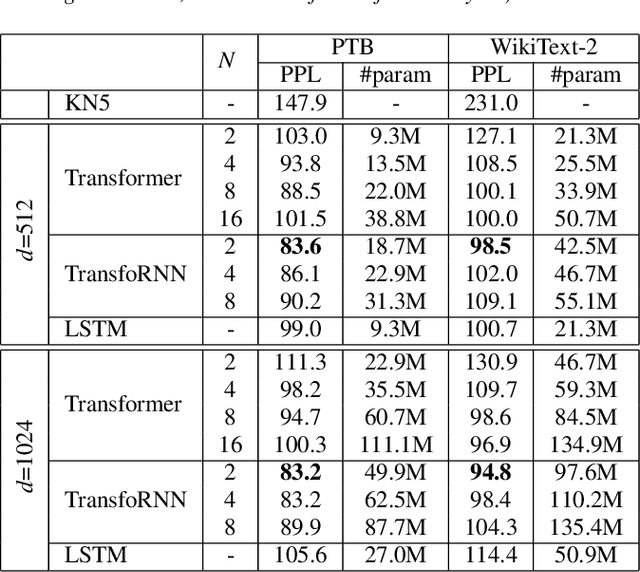
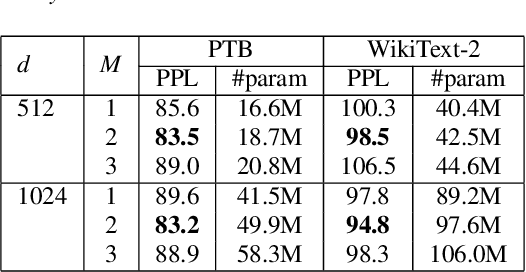
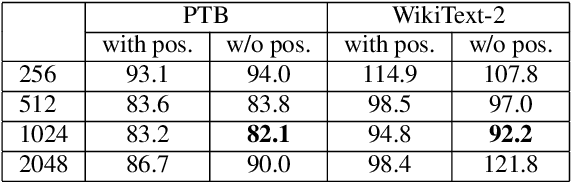
In this paper, we describe the use of recurrent neural networks to capture sequential information from the self-attention representations to improve the Transformers. Although self-attention mechanism provides a means to exploit long context, the sequential information, i.e. the arrangement of tokens, is not explicitly captured. We propose to cascade the recurrent neural networks to the Transformers, which referred to as the TransfoRNN model, to capture the sequential information. We found that the TransfoRNN models which consists of only shallow Transformers stack is suffice to give comparable, if not better, performance than a deeper Transformer model. Evaluated on the Penn Treebank and WikiText-2 corpora, the proposed TransfoRNN model has shown lower model perplexities with fewer number of model parameters. On the Penn Treebank corpus, the model perplexities were reduced up to 5.5% with the model size reduced up to 10.5%. On the WikiText-2 corpus, the model perplexity was reduced up to 2.2% with a 27.7% smaller model. Also, the TransfoRNN model was applied on the LibriSpeech speech recognition task and has shown comparable results with the Transformer models.