 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariations on the Reinforcement Learning performance of Blackjack
Aug 09, 2023Blackjack or "21" is a popular card-based game of chance and skill. The objective of the game is to win by obtaining a hand total higher than the dealer's without exceeding 21. The ideal blackjack strategy will maximize financial return in the long run while avoiding gambler's ruin. The stochastic environment and inherent reward structure of blackjack presents an appealing problem to better understand reinforcement learning agents in the presence of environment variations. Here we consider a q-learning solution for optimal play and investigate the rate of learning convergence of the algorithm as a function of deck size. A blackjack simulator allowing for universal blackjack rules is also implemented to demonstrate the extent to which a card counter perfectly using the basic strategy and hi-lo system can bring the house to bankruptcy and how environment variations impact this outcome. The novelty of our work is to place this conceptual understanding of the impact of deck size in the context of learning agent convergence.
Many learning agents interacting with an agent-based market model
Mar 25, 2023We consider the dynamics and the interactions of multiple reinforcement learning optimal execution trading agents interacting with a reactive Agent-Based Model (ABM) of a financial market in event time. The model represents a market ecology with 3-trophic levels represented by: optimal execution learning agents, minimally intelligent liquidity takers, and fast electronic liquidity providers. The optimal execution agent classes include buying and selling agents that can either use a combination of limit orders and market orders, or only trade using market orders. The reward function explicitly balances trade execution slippage against the penalty of not executing the order timeously. This work demonstrates how multiple competing learning agents impact a minimally intelligent market simulation as functions of the number of agents, the size of agents' initial orders, and the state spaces used for learning. We use phase space plots to examine the dynamics of the ABM, when various specifications of learning agents are included. Further, we examine whether the inclusion of optimal execution agents that can learn is able to produce dynamics with the same complexity as empirical data. We find that the inclusion of optimal execution agents changes the stylised facts produced by ABM to conform more with empirical data, and are a necessary inclusion for ABMs investigating market micro-structure. However, including execution agents to chartist-fundamentalist-noise ABMs is insufficient to recover the complexity observed in empirical data.
A simple learning agent interacting with an agent-based market model
Aug 22, 2022


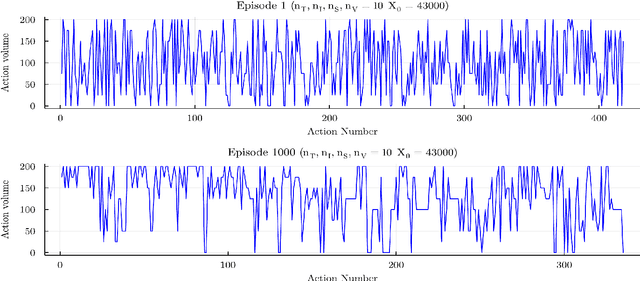
We consider the learning dynamics of a single reinforcement learning optimal execution trading agent when it interacts with an event driven agent-based financial market model. Trading takes place asynchronously through a matching engine in event time. The optimal execution agent is considered at different levels of initial order-sizes and differently sized state spaces. The resulting impact on the agent-based model and market are considered using a calibration approach that explores changes in the empirical stylised facts and price impact curves. Convergence, volume trajectory and action trace plots are used to visualise the learning dynamics. This demonstrates how an optimal execution agent learns optimal trading decisions inside a simulated reactive market framework and how this in turn generates a back-reaction that changes the simulated market through the introduction of strategic order-splitting.
Learning low-frequency temporal patterns for quantitative trading
Aug 12, 2020



We consider the viability of a modularised mechanistic online machine learning framework to learn signals in low-frequency financial time series data. The framework is proved on daily sampled closing time-series data from JSE equity markets. The input patterns are vectors of pre-processed sequences of daily, weekly and monthly or quarterly sampled feature changes. The data processing is split into a batch processed step where features are learnt using a stacked autoencoder via unsupervised learning, and then both batch and online supervised learning are carried out using these learnt features, with the output being a point prediction of measured time-series feature fluctuations. Weight initializations are implemented with restricted Boltzmann machine pre-training, and variance based initializations. Historical simulations are then run using an online feedforward neural network initialised with the weights from the batch training and validation step. The validity of results are considered under a rigorous assessment of backtest overfitting using both combinatorially symmetrical cross validation and probabilistic and deflated Sharpe ratios. Results are used to develop a view on the phenomenology of financial markets and the value of complex historical data-analysis for trading under the unstable adaptive dynamics that characterise financial markets.
A Framework for Online Investment Algorithms
Mar 30, 2020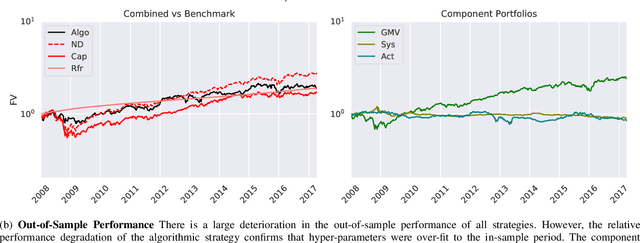

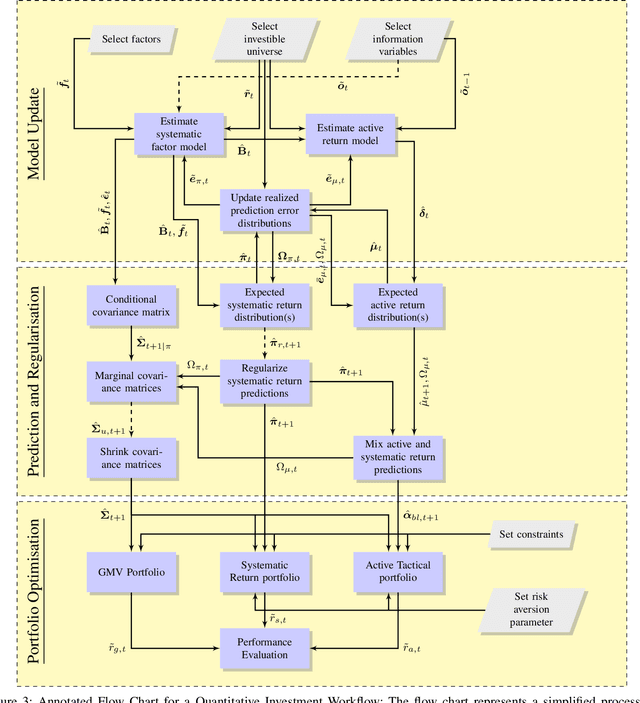
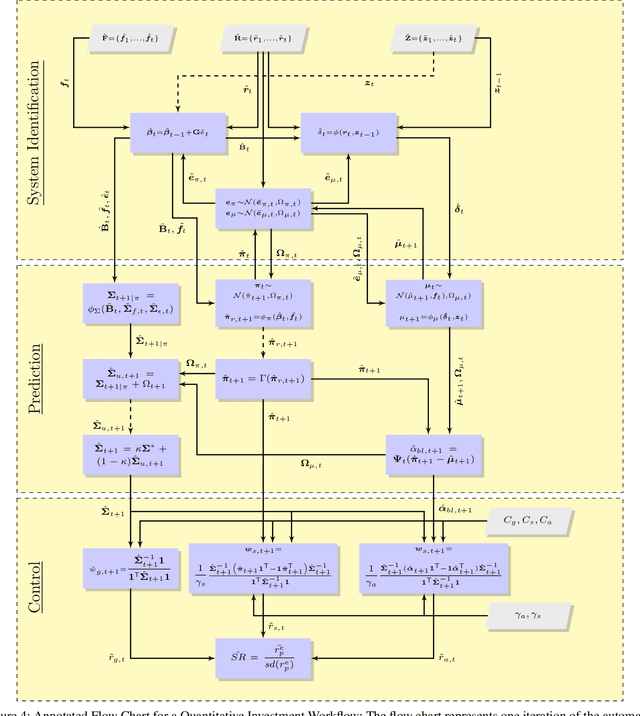
The artificial segmentation of an investment management process into a workflow with silos of offline human operators can restrict silos from collectively and adaptively pursuing a unified optimal investment goal. To meet the investor's objectives, an online algorithm can provide an explicit incremental approach that makes sequential updates as data arrives at the process level. This is in stark contrast to offline (or batch) processes that are focused on making component level decisions prior to process level integration. Here we present and report results for an integrated, and online framework for algorithmic portfolio management. This article provides a workflow that can in-turn be embedded into a process level learning framework. The workflow can be enhanced to refine signal generation and asset-class evolution and definitions. Our results confirm that we can use our framework in conjunction with resampling methods to outperform naive market capitalisation benchmarks while making clear the extent of back-test over-fitting. We consider such an online update framework to be a crucial step towards developing intelligent portfolio selection algorithms that integrate financial theory, investor views, and data analysis with process-level learning.
Agglomerative Fast Super-Paramagnetic Clustering
Aug 07, 2019
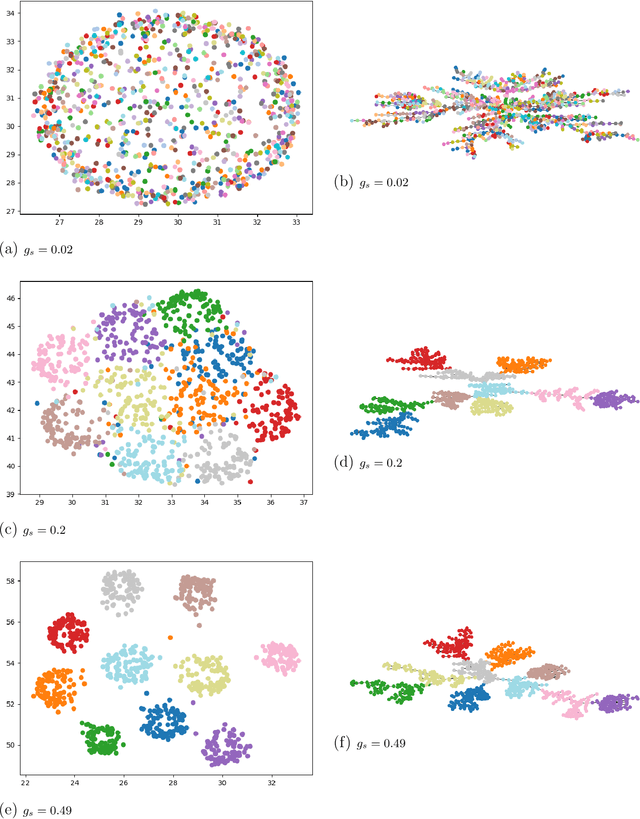
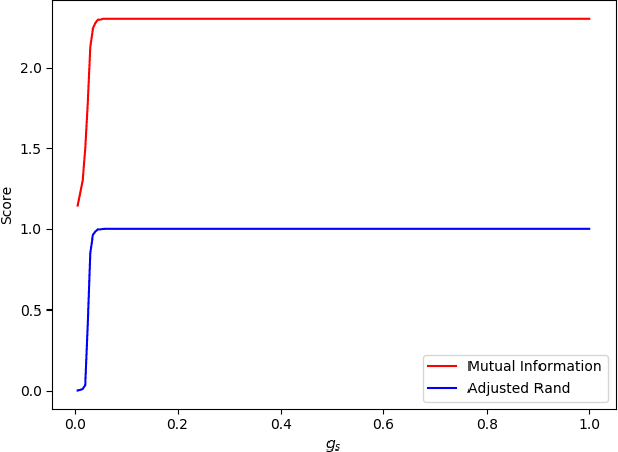
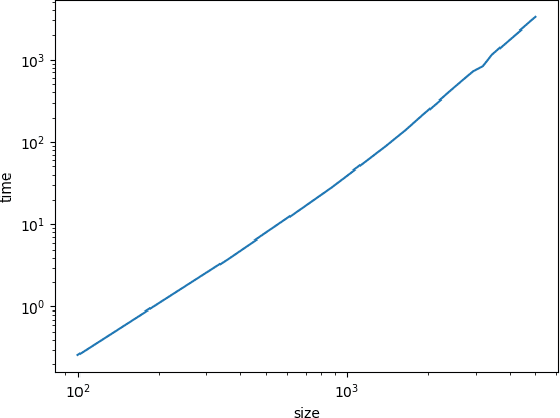
We consider the problem of fast time-series data clustering. Building on previous work modeling the correlation-based Hamiltonian of spin variables we present a fast non-expensive agglomerative algorithm. The method is tested on synthetic correlated time-series and noisy synthetic data-sets with built-in cluster structure to demonstrate that the algorithm produces meaningful non-trivial results. We argue that ASPC can reduce compute time costs and resource usage cost for large scale clustering while being serialized and hence has no obvious parallelization requirement. The algorithm can be an effective choice for state-detection for online learning in a fast non-linear data environment because the algorithm requires no prior information about the number of clusters.
Learning the population dynamics of technical trading strategies
Mar 06, 2019



We use an adversarial expert based online learning algorithm to learn the optimal parameters required to maximise wealth trading zero-cost portfolio strategies. The learning algorithm is used to determine the relative population dynamics of technical trading strategies that can survive historical back-testing as well as form an overall aggregated portfolio trading strategy from the set of underlying trading strategies implemented on daily and intraday Johannesburg Stock Exchange data. The resulting population time-series are investigated using unsupervised learning for dimensionality reduction and visualisation. A key contribution is that the overall aggregated trading strategies are tested for statistical arbitrage using a novel hypothesis test proposed by Jarrow et al. on both daily sampled and intraday time-scales. The (low frequency) daily sampled strategies fail the arbitrage tests after costs, while the (high frequency) intraday sampled strategies are not falsified as statistical arbitrages after costs. The estimates of trading strategy success, cost of trading and slippage are considered along with an offline benchmark portfolio algorithm for performance comparison. The work aims to explore and better understand the interplay between different technical trading strategies from a data-informed perspective.
High-speed detection of emergent market clustering via an unsupervised parallel genetic algorithm
Aug 02, 2015
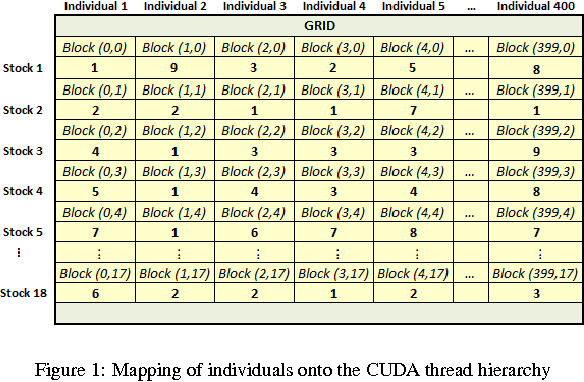
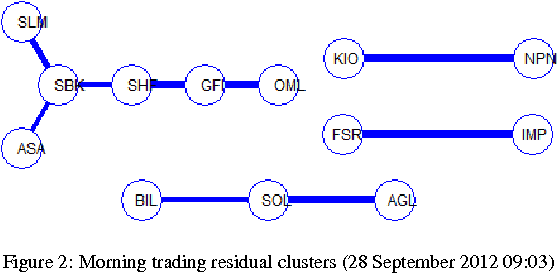
We implement a master-slave parallel genetic algorithm (PGA) with a bespoke log-likelihood fitness function to identify emergent clusters within price evolutions. We use graphics processing units (GPUs) to implement a PGA and visualise the results using disjoint minimal spanning trees (MSTs). We demonstrate that our GPU PGA, implemented on a commercially available general purpose GPU, is able to recover stock clusters in sub-second speed, based on a subset of stocks in the South African market. This represents a pragmatic choice for low-cost, scalable parallel computing and is significantly faster than a prototype serial implementation in an optimised C-based fourth-generation programming language, although the results are not directly comparable due to compiler differences. Combined with fast online intraday correlation matrix estimation from high frequency data for cluster identification, the proposed implementation offers cost-effective, near-real-time risk assessment for financial practitioners.
* 10 pages, 5 figures, 4 tables, More thorough discussion of implementation