 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cause-of-Death Classification from Verbal Autopsy Reports
Oct 31, 2022In many lower-and-middle income countries including South Africa, data access in health facilities is restricted due to patient privacy and confidentiality policies. Further, since clinical data is unique to individual institutions and laboratories, there are insufficient data annotation standards and conventions. As a result of the scarcity of textual data, natural language processing (NLP) techniques have fared poorly in the health sector. A cause of death (COD) is often determined by a verbal autopsy (VA) report in places without reliable death registration systems. A non-clinician field worker does a VA report using a set of standardized questions as a guide to uncover symptoms of a COD. This analysis focuses on the textual part of the VA report as a case study to address the challenge of adapting NLP techniques in the health domain. We present a system that relies on two transfer learning paradigms of monolingual learning and multi-source domain adaptation to improve VA narratives for the target task of the COD classification. We use the Bidirectional Encoder Representations from Transformers (BERT) and Embeddings from Language Models (ELMo) models pre-trained on the general English and health domains to extract features from the VA narratives. Our findings suggest that this transfer learning system improves the COD classification tasks and that the narrative text contains valuable information for figuring out a COD. Our results further show that combining binary VA features and narrative text features learned via this framework boosts the classification task of COD.
Evaluating State of the Art, Forecasting Ensembles- and Meta-learning Strategies for Model Fusion
Mar 07, 2022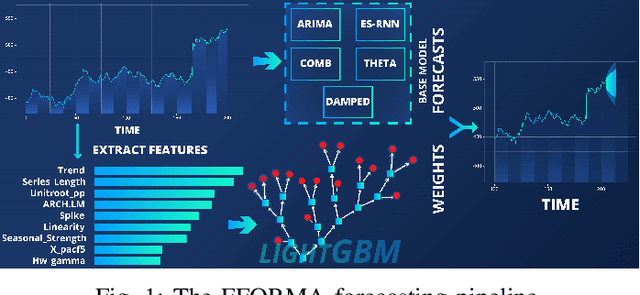



Techniques of hybridisation and ensemble learning are popular model fusion techniques for improving the predictive power of forecasting methods. With limited research that instigates combining these two promising approaches, this paper focuses on the utility of the Exponential-Smoothing-Recurrent Neural Network (ES-RNN) in the pool of base models for different ensembles. We compare against some state of the art ensembling techniques and arithmetic model averaging as a benchmark. We experiment with the M4 forecasting data set of 100,000 time-series, and the results show that the Feature-based Forecast Model Averaging (FFORMA), on average, is the best technique for late data fusion with the ES-RNN. However, considering the M4's Daily subset of data, stacking was the only successful ensemble at dealing with the case where all base model performances are similar. Our experimental results indicate that we attain state of the art forecasting results compared to N-BEATS as a benchmark. We conclude that model averaging is a more robust ensemble than model selection and stacking strategies. Further, the results show that gradient boosting is superior for implementing ensemble learning strategies.
Investigating Transfer Learning in Graph Neural Networks
Feb 01, 2022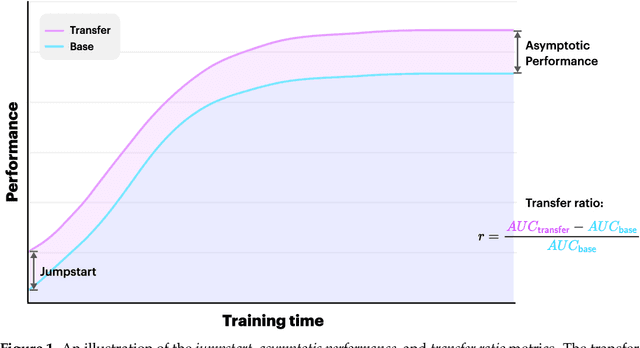
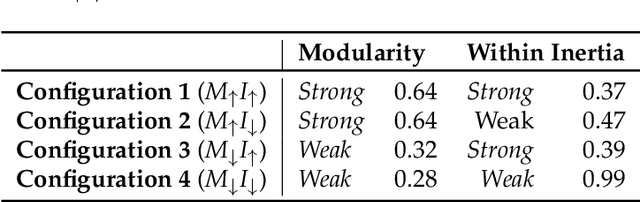
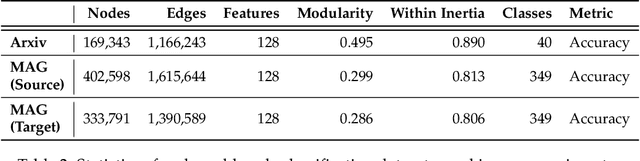
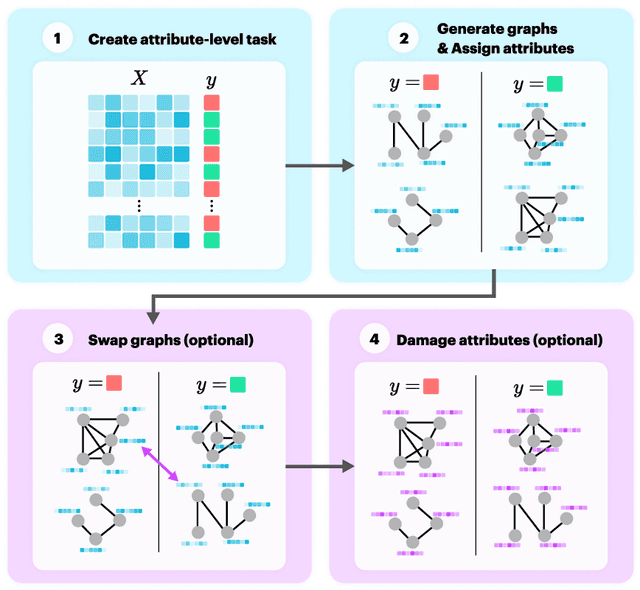
Graph neural networks (GNNs) build on the success of deep learning models by extending them for use in graph spaces. Transfer learning has proven extremely successful for traditional deep learning problems: resulting in faster training and improved performance. Despite the increasing interest in GNNs and their use cases, there is little research on their transferability. This research demonstrates that transfer learning is effective with GNNs, and describes how source tasks and the choice of GNN impact the ability to learn generalisable knowledge. We perform experiments using real-world and synthetic data within the contexts of node classification and graph classification. To this end, we also provide a general methodology for transfer learning experimentation and present a novel algorithm for generating synthetic graph classification tasks. We compare the performance of GCN, GraphSAGE and GIN across both the synthetic and real-world datasets. Our results demonstrate empirically that GNNs with inductive operations yield statistically significantly improved transfer. Further we show that similarity in community structure between source and target tasks support statistically significant improvements in transfer over and above the use of only the node attributes.
A Framework for Online Investment Algorithms
Mar 30, 2020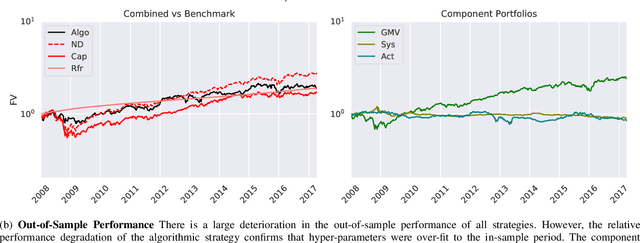

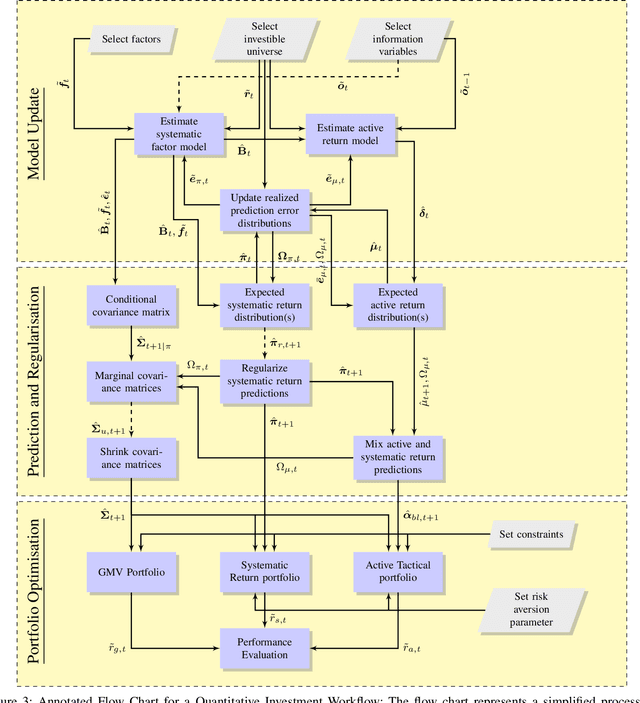
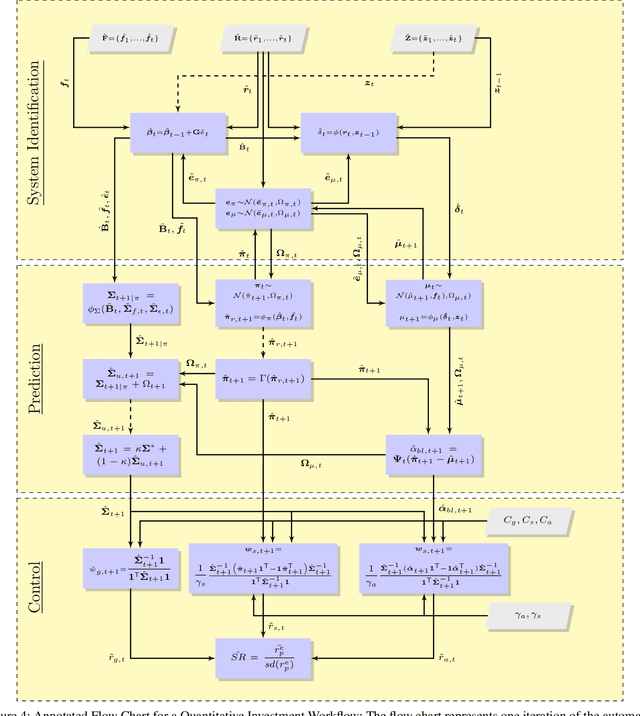
The artificial segmentation of an investment management process into a workflow with silos of offline human operators can restrict silos from collectively and adaptively pursuing a unified optimal investment goal. To meet the investor's objectives, an online algorithm can provide an explicit incremental approach that makes sequential updates as data arrives at the process level. This is in stark contrast to offline (or batch) processes that are focused on making component level decisions prior to process level integration. Here we present and report results for an integrated, and online framework for algorithmic portfolio management. This article provides a workflow that can in-turn be embedded into a process level learning framework. The workflow can be enhanced to refine signal generation and asset-class evolution and definitions. Our results confirm that we can use our framework in conjunction with resampling methods to outperform naive market capitalisation benchmarks while making clear the extent of back-test over-fitting. We consider such an online update framework to be a crucial step towards developing intelligent portfolio selection algorithms that integrate financial theory, investor views, and data analysis with process-level learning.
Inter- and Intra-domain Knowledge Transfer for Related Tasks in Deep Character Recognition
Jan 02, 2020
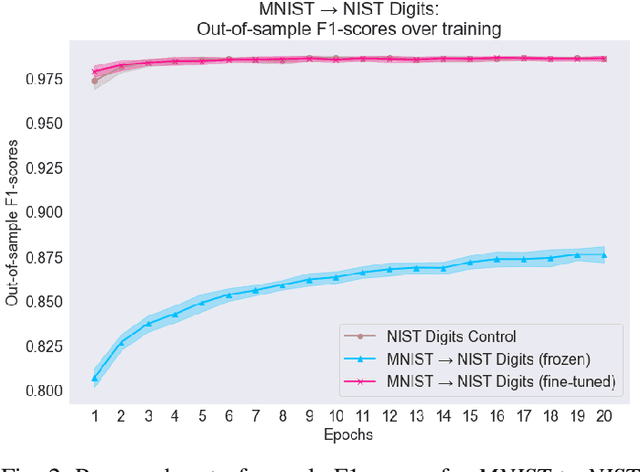


Pre-training a deep neural network on the ImageNet dataset is a common practice for training deep learning models, and generally yields improved performance and faster training times. The technique of pre-training on one task and then retraining on a new one is called transfer learning. In this paper we analyse the effectiveness of using deep transfer learning for character recognition tasks. We perform three sets of experiments with varying levels of similarity between source and target tasks to investigate the behaviour of different types of knowledge transfer. We transfer both parameters and features and analyse their behaviour. Our results demonstrate that no significant advantage is gained by using a transfer learning approach over a traditional machine learning approach for our character recognition tasks. This suggests that using transfer learning does not necessarily presuppose a better performing model in all cases.