 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Cause-of-Death Classification from Verbal Autopsy Reports
Oct 31, 2022In many lower-and-middle income countries including South Africa, data access in health facilities is restricted due to patient privacy and confidentiality policies. Further, since clinical data is unique to individual institutions and laboratories, there are insufficient data annotation standards and conventions. As a result of the scarcity of textual data, natural language processing (NLP) techniques have fared poorly in the health sector. A cause of death (COD) is often determined by a verbal autopsy (VA) report in places without reliable death registration systems. A non-clinician field worker does a VA report using a set of standardized questions as a guide to uncover symptoms of a COD. This analysis focuses on the textual part of the VA report as a case study to address the challenge of adapting NLP techniques in the health domain. We present a system that relies on two transfer learning paradigms of monolingual learning and multi-source domain adaptation to improve VA narratives for the target task of the COD classification. We use the Bidirectional Encoder Representations from Transformers (BERT) and Embeddings from Language Models (ELMo) models pre-trained on the general English and health domains to extract features from the VA narratives. Our findings suggest that this transfer learning system improves the COD classification tasks and that the narrative text contains valuable information for figuring out a COD. Our results further show that combining binary VA features and narrative text features learned via this framework boosts the classification task of COD.
Using Machine Learning to Fuse Verbal Autopsy Narratives and Binary Features in the Analysis of Deaths from Hyperglycaemia
Apr 26, 2022
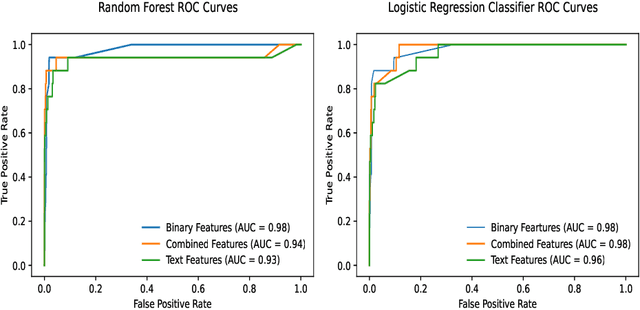
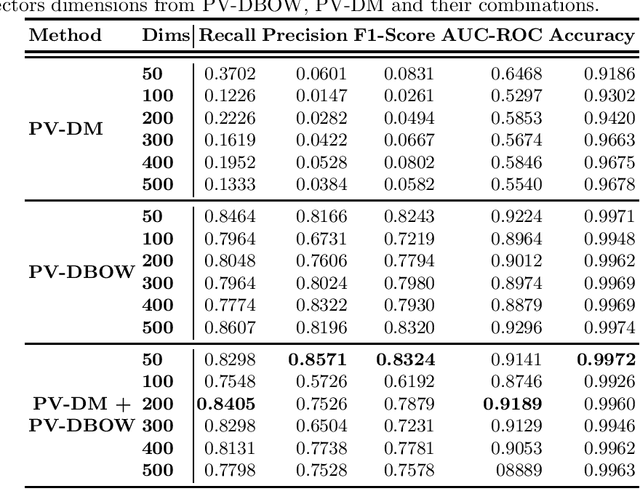
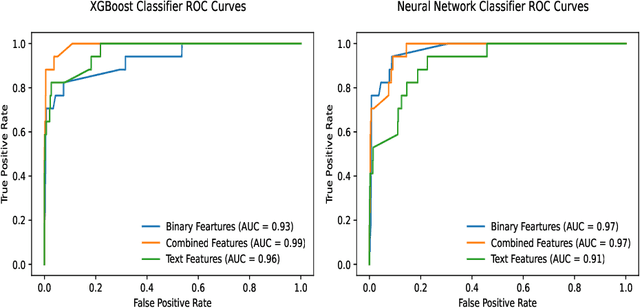
Lower-and-middle income countries are faced with challenges arising from a lack of data on cause of death (COD), which can limit decisions on population health and disease management. A verbal autopsy(VA) can provide information about a COD in areas without robust death registration systems. A VA consists of structured data, combining numeric and binary features, and unstructured data as part of an open-ended narrative text. This study assesses the performance of various machine learning approaches when analyzing both the structured and unstructured components of the VA report. The algorithms were trained and tested via cross-validation in the three settings of binary features, text features and a combination of binary and text features derived from VA reports from rural South Africa. The results obtained indicate narrative text features contain valuable information for determining COD and that a combination of binary and text features improves the automated COD classification task. Keywords: Diabetes Mellitus, Verbal Autopsy, Cause of Death, Machine Learning, Natural Language Processing