 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring agent objectives at different scales of a complex adaptive system
Dec 04, 2017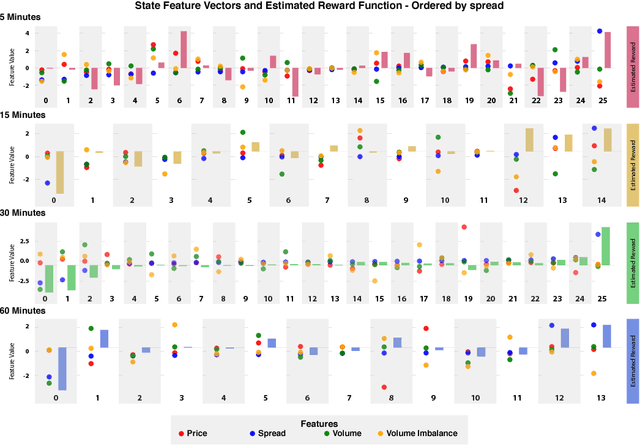
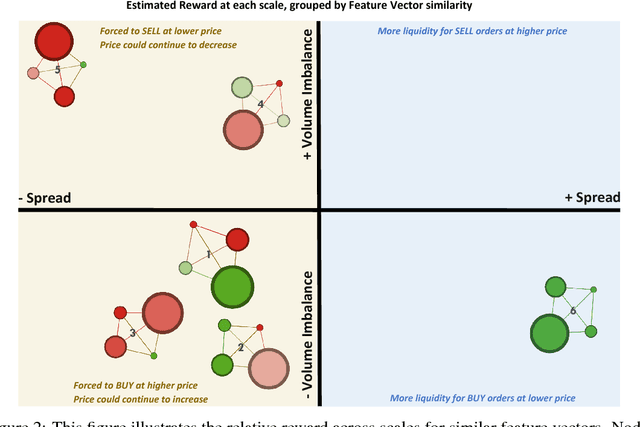
We introduce a framework to study the effective objectives at different time scales of financial market microstructure. The financial market can be regarded as a complex adaptive system, where purposeful agents collectively and simultaneously create and perceive their environment as they interact with it. It has been suggested that multiple agent classes operate in this system, with a non-trivial hierarchy of top-down and bottom-up causation classes with different effective models governing each level. We conjecture that agent classes may in fact operate at different time scales and thus act differently in response to the same perceived market state. Given scale-specific temporal state trajectories and action sequences estimated from aggregate market behaviour, we use Inverse Reinforcement Learning to compute the effective reward function for the aggregate agent class at each scale, allowing us to assess the relative attractiveness of feature vectors across different scales. Differences in reward functions for feature vectors may indicate different objectives of market participants, which could assist in finding the scale boundary for agent classes. This has implications for learning algorithms operating in this domain.
Using real-time cluster configurations of streaming asynchronous features as online state descriptors in financial markets
May 04, 2017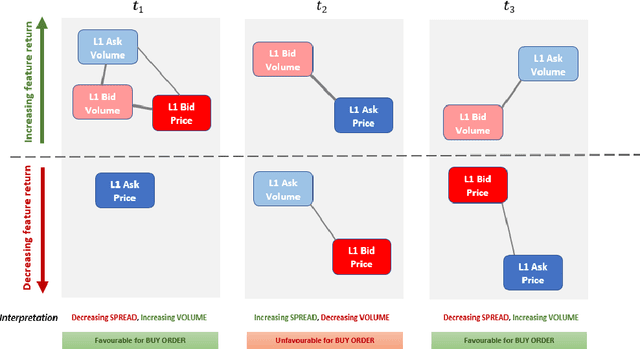
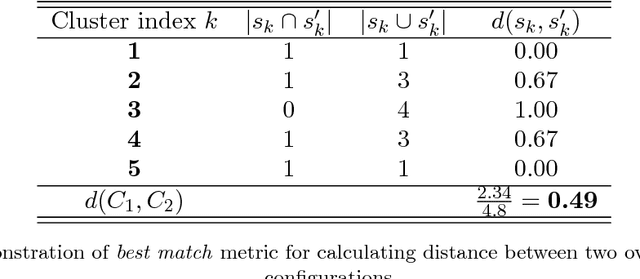
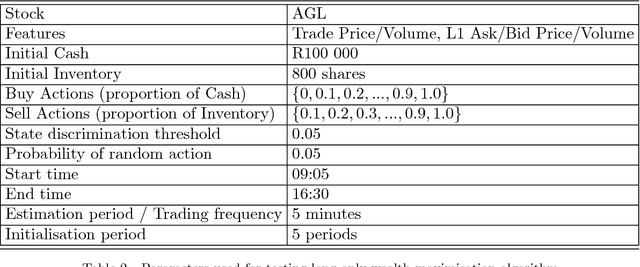
We present a scheme for online, unsupervised state discovery and detection from streaming, multi-featured, asynchronous data in high-frequency financial markets. Online feature correlations are computed using an unbiased, lossless Fourier estimator. A high-speed maximum likelihood clustering algorithm is then used to find the feature cluster configuration which best explains the structure in the correlation matrix. We conjecture that this feature configuration is a candidate descriptor for the temporal state of the system. Using a simple cluster configuration similarity metric, we are able to enumerate the state space based on prevailing feature configurations. The proposed state representation removes the need for human-driven data pre-processing for state attribute specification, allowing a learning agent to find structure in streaming data, discern changes in the system, enumerate its perceived state space and learn suitable action-selection policies.
Optimal client recommendation for market makers in illiquid financial products
Apr 27, 2017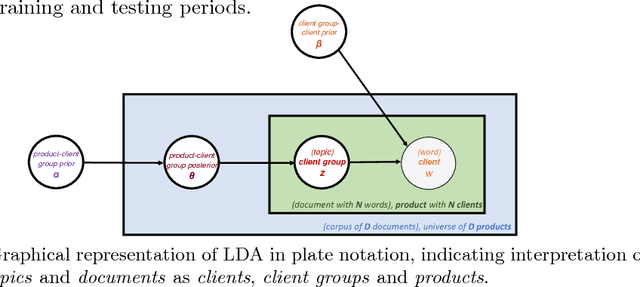
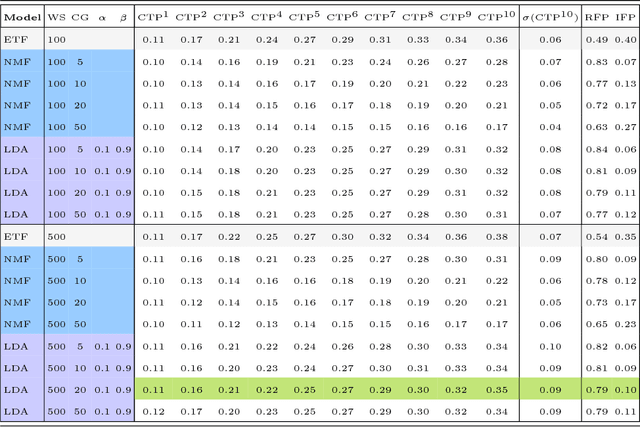
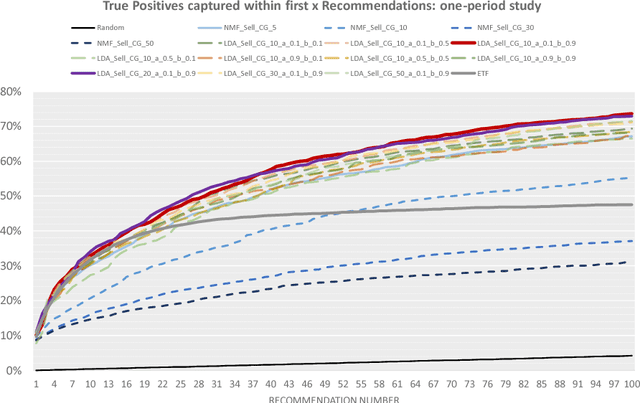
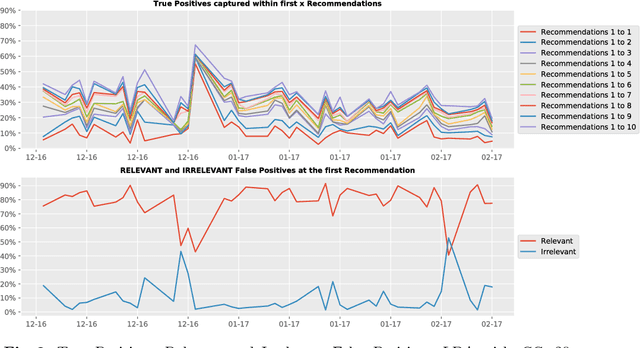
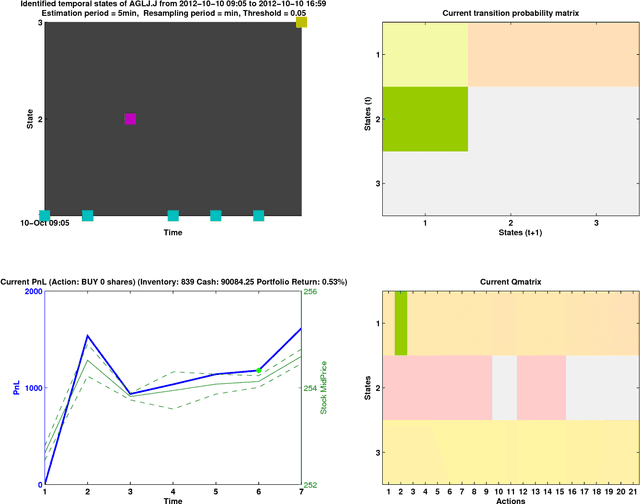
The process of liquidity provision in financial markets can result in prolonged exposure to illiquid instruments for market makers. In this case, where a proprietary position is not desired, pro-actively targeting the right client who is likely to be interested can be an effective means to offset this position, rather than relying on commensurate interest arising through natural demand. In this paper, we consider the inference of a client profile for the purpose of corporate bond recommendation, based on typical recorded information available to the market maker. Given a historical record of corporate bond transactions and bond meta-data, we use a topic-modelling analogy to develop a probabilistic technique for compiling a curated list of client recommendations for a particular bond that needs to be traded, ranked by probability of interest. We show that a model based on Latent Dirichlet Allocation offers promising performance to deliver relevant recommendations for sales traders.
Statistical Inference, Learning and Models in Big Data
Jan 28, 2016
The need for new methods to deal with big data is a common theme in most scientific fields, although its definition tends to vary with the context. Statistical ideas are an essential part of this, and as a partial response, a thematic program on statistical inference, learning, and models in big data was held in 2015 in Canada, under the general direction of the Canadian Statistical Sciences Institute, with major funding from, and most activities located at, the Fields Institute for Research in Mathematical Sciences. This paper gives an overview of the topics covered, describing challenges and strategies that seem common to many different areas of application, and including some examples of applications to make these challenges and strategies more concrete.
* Thematic Program on Statistical Inference, Learning, and Models for Big Data, Fields Institute; 23 pages, 2 figures
High-speed detection of emergent market clustering via an unsupervised parallel genetic algorithm
Aug 02, 2015
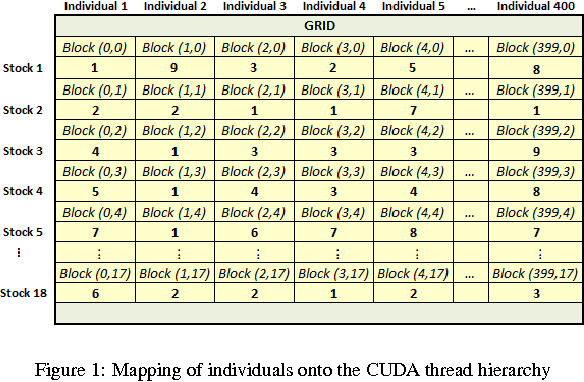
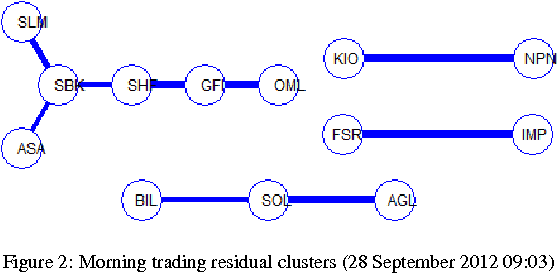
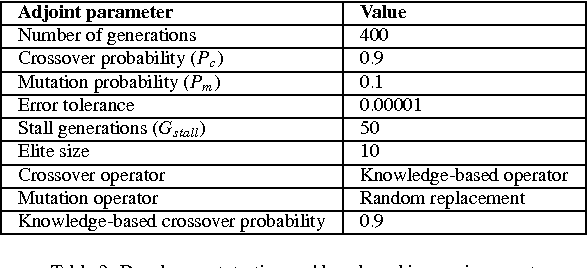
We implement a master-slave parallel genetic algorithm (PGA) with a bespoke log-likelihood fitness function to identify emergent clusters within price evolutions. We use graphics processing units (GPUs) to implement a PGA and visualise the results using disjoint minimal spanning trees (MSTs). We demonstrate that our GPU PGA, implemented on a commercially available general purpose GPU, is able to recover stock clusters in sub-second speed, based on a subset of stocks in the South African market. This represents a pragmatic choice for low-cost, scalable parallel computing and is significantly faster than a prototype serial implementation in an optimised C-based fourth-generation programming language, although the results are not directly comparable due to compiler differences. Combined with fast online intraday correlation matrix estimation from high frequency data for cluster identification, the proposed implementation offers cost-effective, near-real-time risk assessment for financial practitioners.
* 10 pages, 5 figures, 4 tables, More thorough discussion of implementation