 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Space Transfer Learning for analyzing multi-site fMRI data
Oct 24, 2020
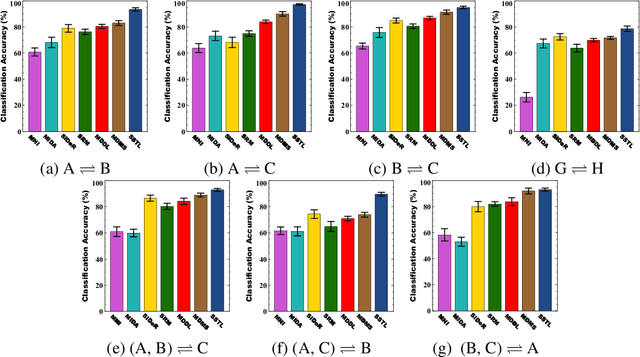
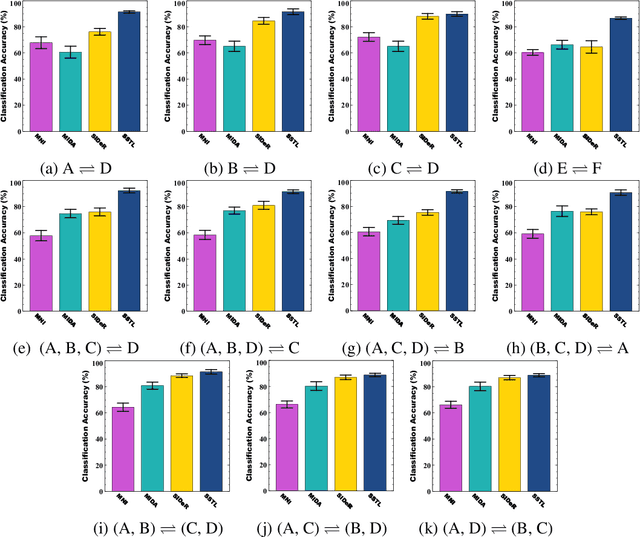
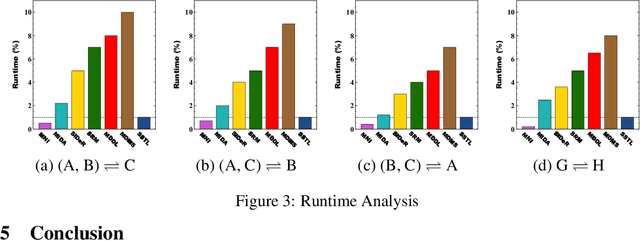
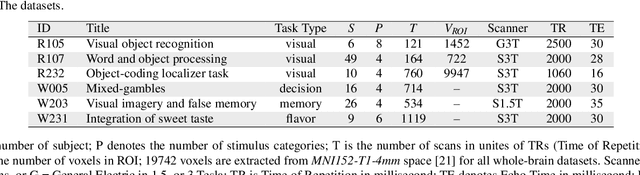
Multi-voxel pattern analysis (MVPA) learns predictive models from task-based functional magnetic resonance imaging (fMRI) data, for distinguishing when subjects are performing different cognitive tasks -- e.g., watching movies or making decisions. MVPA works best with a well-designed feature set and an adequate sample size. However, most fMRI datasets are noisy, high-dimensional, expensive to collect, and with small sample sizes. Further, training a robust, generalized predictive model that can analyze homogeneous cognitive tasks provided by multi-site fMRI datasets has additional challenges. This paper proposes the Shared Space Transfer Learning (SSTL) as a novel transfer learning (TL) approach that can functionally align homogeneous multi-site fMRI datasets, and so improve the prediction performance in every site. SSTL first extracts a set of common features for all subjects in each site. It then uses TL to map these site-specific features to a site-independent shared space in order to improve the performance of the MVPA. SSTL uses a scalable optimization procedure that works effectively for high-dimensional fMRI datasets. The optimization procedure extracts the common features for each site by using a single-iteration algorithm and maps these site-specific common features to the site-independent shared space. We evaluate the effectiveness of the proposed method for transferring between various cognitive tasks. Our comprehensive experiments validate that SSTL achieves superior performance to other state-of-the-art analysis techniques.
Deep Representational Similarity Learning for analyzing neural signatures in task-based fMRI dataset
Sep 28, 2020

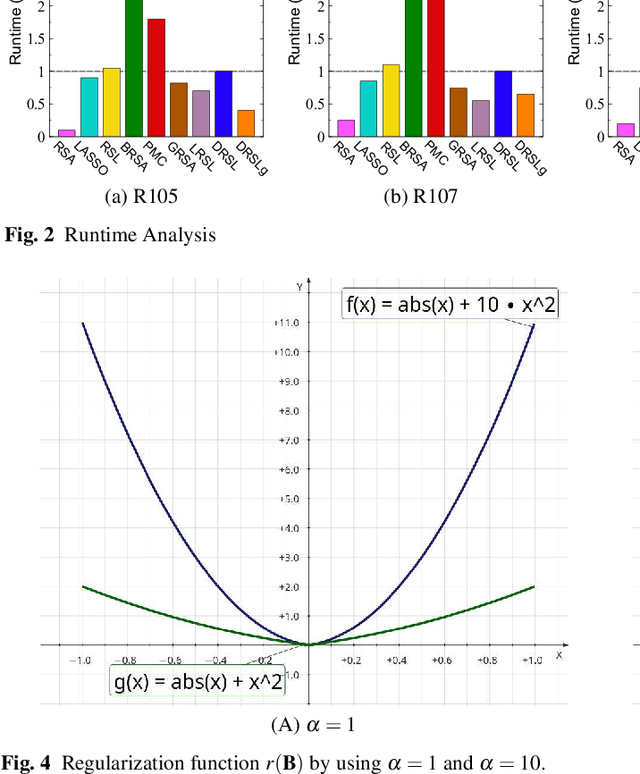
Similarity analysis is one of the crucial steps in most fMRI studies. Representational Similarity Analysis (RSA) can measure similarities of neural signatures generated by different cognitive states. This paper develops Deep Representational Similarity Learning (DRSL), a deep extension of RSA that is appropriate for analyzing similarities between various cognitive tasks in fMRI datasets with a large number of subjects, and high-dimensionality -- such as whole-brain images. Unlike the previous methods, DRSL is not limited by a linear transformation or a restricted fixed nonlinear kernel function -- such as Gaussian kernel. DRSL utilizes a multi-layer neural network for mapping neural responses to linear space, where this network can implement a customized nonlinear transformation for each subject separately. Furthermore, utilizing a gradient-based optimization in DRSL can significantly reduce runtime of analysis on large datasets because it uses a batch of samples in each iteration rather than all neural responses to find an optimal solution. Empirical studies on multi-subject fMRI datasets with various tasks -- including visual stimuli, decision making, flavor, and working memory -- confirm that the proposed method achieves superior performance to other state-of-the-art RSA algorithms.
Supervised Hyperalignment for multi-subject fMRI data alignment
Jan 09, 2020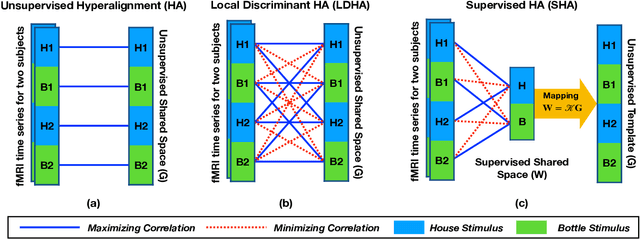
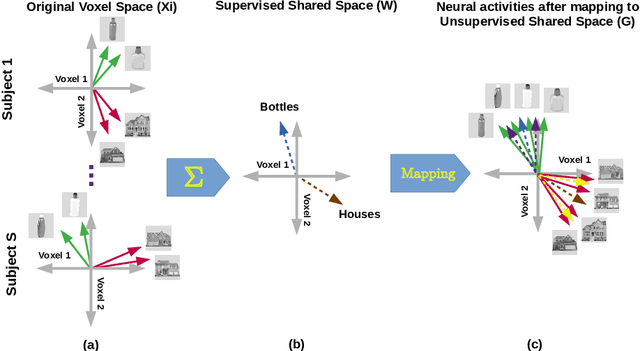
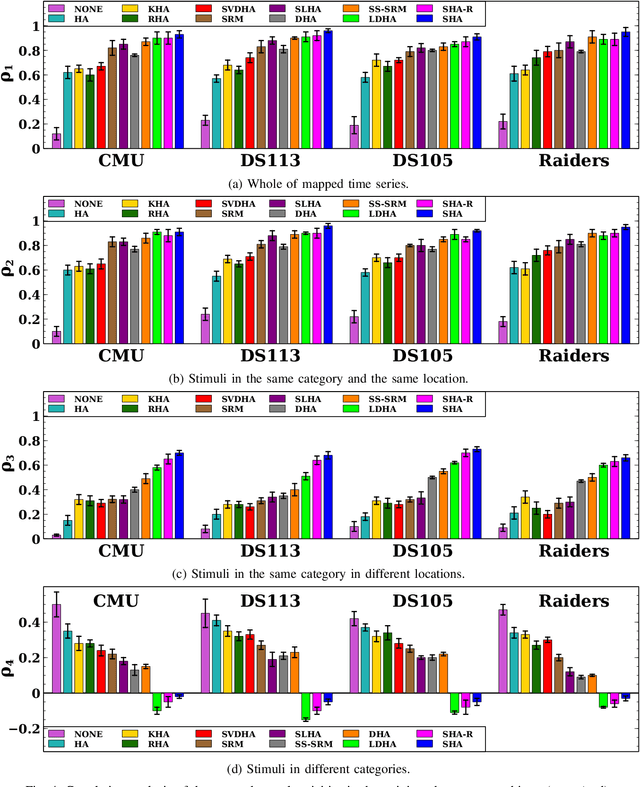
Hyperalignment has been widely employed in Multivariate Pattern (MVP) analysis to discover the cognitive states in the human brains based on multi-subject functional Magnetic Resonance Imaging (fMRI) datasets. Most of the existing HA methods utilized unsupervised approaches, where they only maximized the correlation between the voxels with the same position in the time series. However, these unsupervised solutions may not be optimum for handling the functional alignment in the supervised MVP problems. This paper proposes a Supervised Hyperalignment (SHA) method to ensure better functional alignment for MVP analysis, where the proposed method provides a supervised shared space that can maximize the correlation among the stimuli belonging to the same category and minimize the correlation between distinct categories of stimuli. Further, SHA employs a generalized optimization solution, which generates the shared space and calculates the mapped features in a single iteration, hence with optimum time and space complexities for large datasets. Experiments on multi-subject datasets demonstrate that SHA method achieves up to 19% better performance for multi-class problems over the state-of-the-art HA algorithms.
Statistical Inference, Learning and Models in Big Data
Jan 28, 2016
The need for new methods to deal with big data is a common theme in most scientific fields, although its definition tends to vary with the context. Statistical ideas are an essential part of this, and as a partial response, a thematic program on statistical inference, learning, and models in big data was held in 2015 in Canada, under the general direction of the Canadian Statistical Sciences Institute, with major funding from, and most activities located at, the Fields Institute for Research in Mathematical Sciences. This paper gives an overview of the topics covered, describing challenges and strategies that seem common to many different areas of application, and including some examples of applications to make these challenges and strategies more concrete.
* Thematic Program on Statistical Inference, Learning, and Models for Big Data, Fields Institute; 23 pages, 2 figures