 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Large Language Models to Reason via EM Policy Gradient
Apr 24, 2025Recently, foundation models such as OpenAI's O1 and O3, along with DeepSeek's R1, have demonstrated strong reasoning capacities and problem-solving skills acquired through large-scale reinforcement learning (RL), with wide applications in mathematics, coding, science, intelligent agents, and virtual assistants. In this work, we introduce an off-policy reinforcement learning algorithm, EM Policy Gradient, aimed at enhancing LLM reasoning by optimizing expected return over reasoning trajectories. We frame the reasoning task as an Expectation-Maximization (EM) optimization problem, alternating between sampling diverse rationale trajectories and performing reward-guided fine-tuning. Unlike PPO and GRPO, which rely on complex importance weights and heuristic clipping, our method provides a simpler, more principled off-policy policy gradient approach, eliminating these complexities while maintaining strong performance. We evaluate the effectiveness of EM Policy Gradient on the GSM8K and MATH (HARD) datasets, where it achieves performance comparable to or slightly surpassing the state-of-the-art GRPO, while offering additional advantages in scalability, simplicity, and reasoning conciseness. Moreover, models fine-tuned with our method exhibit cognitive behaviors, such as sub-problem decomposition, self-verification, and backtracking, highlighting its potential to enhance both the interpretability and robustness of LLM reasoning.
WALL-E: An Efficient Reinforcement Learning Research Framework
Jan 28, 2019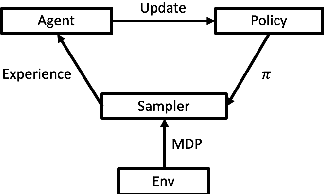
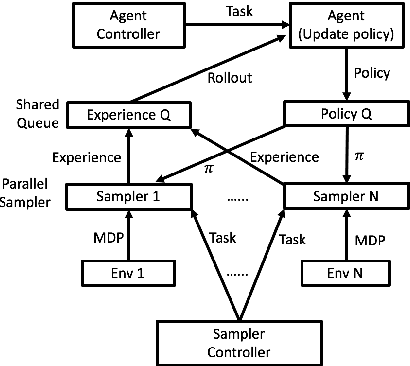
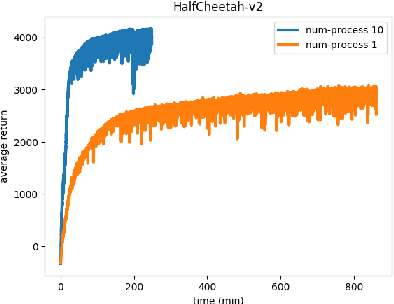

There are two halves to RL systems: experience collection time and policy learning time. For a large number of samples in rollouts, experience collection time is the major bottleneck. Thus, it is necessary to speed up the rollout generation time with multi-process architecture support. Our work, dubbed WALL-E, utilizes multiple rollout samplers running in parallel to rapidly generate experience. Due to our parallel samplers, we experience not only faster convergence times, but also higher average reward thresholds. For example, on the MuJoCo HalfCheetah-v2 task, with $N = 10$ parallel sampler processes, we are able to achieve much higher average return than those from using only a single process architecture.
Stochastic Variance Reduction for Policy Gradient Estimation
Mar 29, 2018
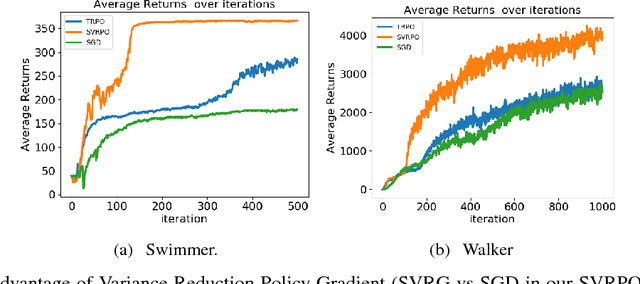
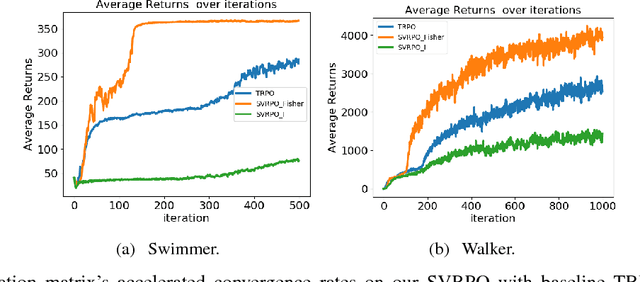

Recent advances in policy gradient methods and deep learning have demonstrated their applicability for complex reinforcement learning problems. However, the variance of the performance gradient estimates obtained from the simulation is often excessive, leading to poor sample efficiency. In this paper, we apply the stochastic variance reduced gradient descent (SVRG) to model-free policy gradient to significantly improve the sample-efficiency. The SVRG estimation is incorporated into a trust-region Newton conjugate gradient framework for the policy optimization. On several Mujoco tasks, our method achieves significantly better performance compared to the state-of-the-art model-free policy gradient methods in robotic continuous control such as trust region policy optimization (TRPO)
Learning to Explore with Meta-Policy Gradient
Mar 26, 2018

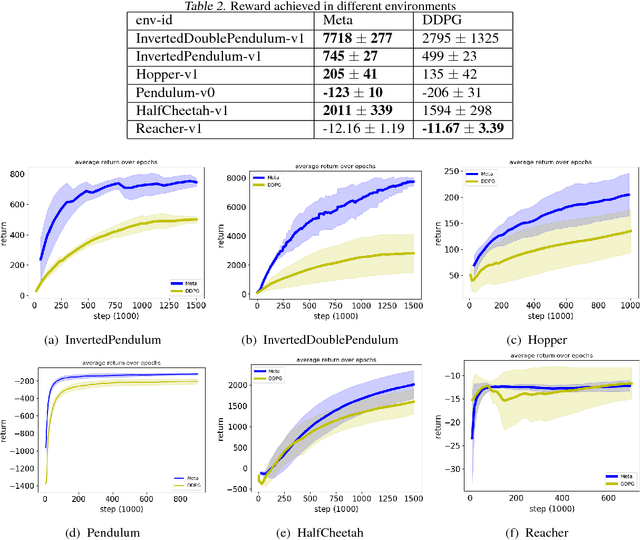

The performance of off-policy learning, including deep Q-learning and deep deterministic policy gradient (DDPG), critically depends on the choice of the exploration policy. Existing exploration methods are mostly based on adding noise to the on-going actor policy and can only explore \emph{local} regions close to what the actor policy dictates. In this work, we develop a simple meta-policy gradient algorithm that allows us to adaptively learn the exploration policy in DDPG. Our algorithm allows us to train flexible exploration behaviors that are independent of the actor policy, yielding a \emph{global exploration} that significantly speeds up the learning process. With an extensive study, we show that our method significantly improves the sample-efficiency of DDPG on a variety of reinforcement learning tasks.
Variational Inference for Policy Gradient
Mar 25, 2018Inspired by the seminal work on Stein Variational Inference and Stein Variational Policy Gradient, we derived a method to generate samples from the posterior variational parameter distribution by \textit{explicitly} minimizing the KL divergence to match the target distribution in an amortize fashion. Consequently, we applied this varational inference technique into vanilla policy gradient, TRPO and PPO with Bayesian Neural Network parameterizations for reinforcement learning problems.
Thompson Sampling in Dynamic Systems for Contextual Bandit Problems
Oct 17, 2013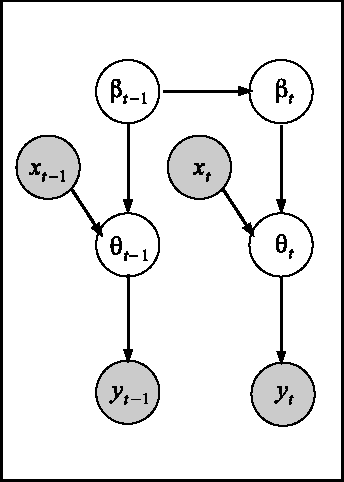
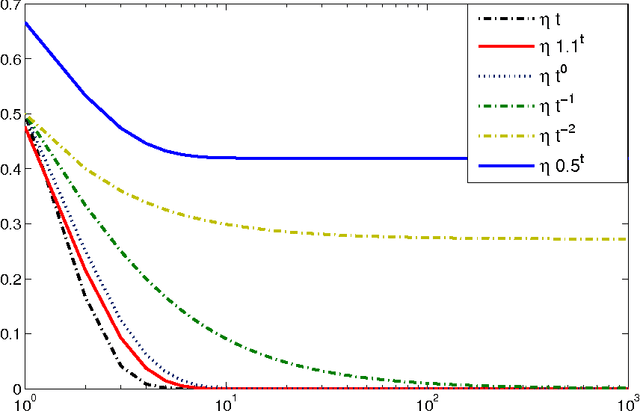
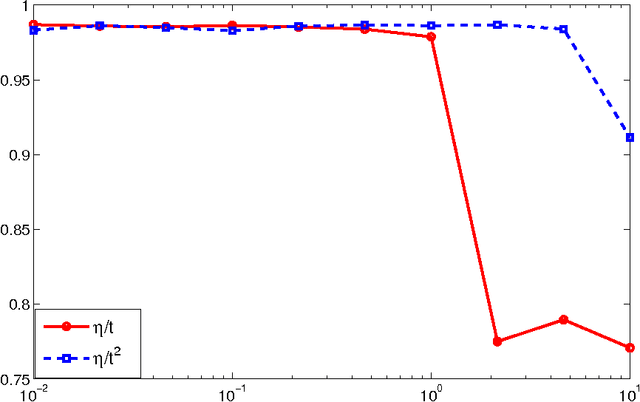
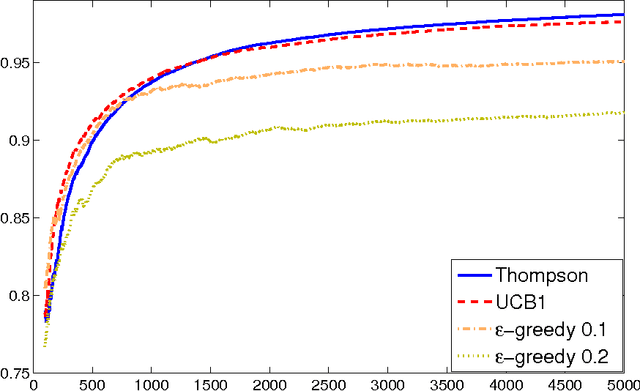
We consider the multiarm bandit problems in the timevarying dynamic system for rich structural features. For the nonlinear dynamic model, we propose the approximate inference for the posterior distributions based on Laplace Approximation. For the context bandit problems, Thompson Sampling is adopted based on the underlying posterior distributions of the parameters. More specifically, we introduce the discount decays on the previous samples impact and analyze the different decay rates with the underlying sample dynamics. Consequently, the exploration and exploitation is adaptively tradeoff according to the dynamics in the system.
Online Classification Using a Voted RDA Method
Oct 17, 2013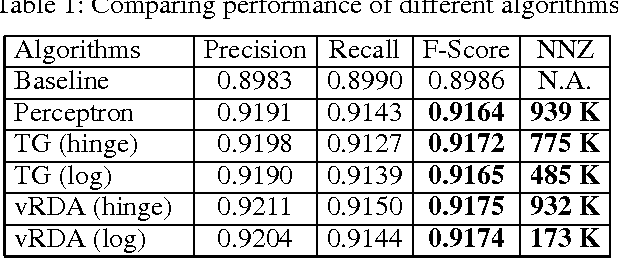
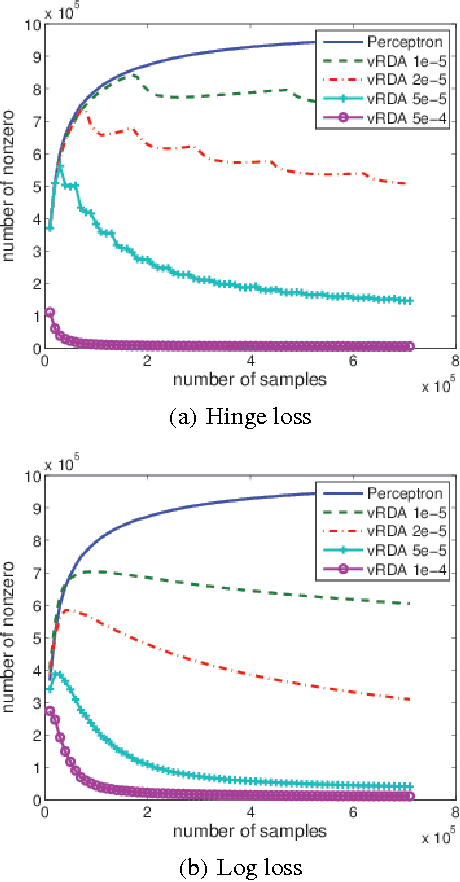
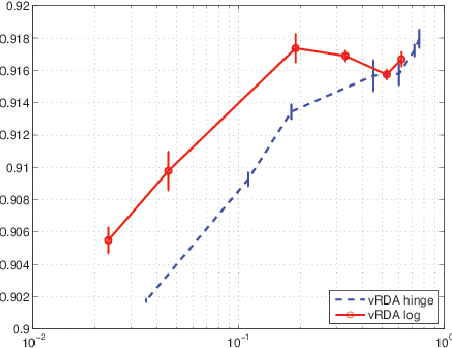
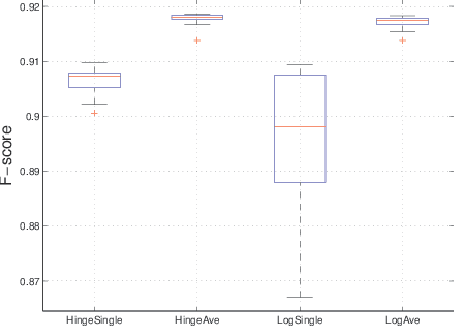
We propose a voted dual averaging method for online classification problems with explicit regularization. This method employs the update rule of the regularized dual averaging (RDA) method, but only on the subsequence of training examples where a classification error is made. We derive a bound on the number of mistakes made by this method on the training set, as well as its generalization error rate. We also introduce the concept of relative strength of regularization, and show how it affects the mistake bound and generalization performance. We experimented with the method using $\ell_1$ regularization on a large-scale natural language processing task, and obtained state-of-the-art classification performance with fairly sparse models.