 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark Dataset for Spatially Aligned Road Damage Assessment in Small Uncrewed Aerial Systems Disaster Imagery
Dec 13, 2025This paper presents the largest known benchmark dataset for road damage assessment and road alignment, and provides 18 baseline models trained on the CRASAR-U-DRIODs dataset's post-disaster small uncrewed aerial systems (sUAS) imagery from 10 federally declared disasters, addressing three challenges within prior post-disaster road damage assessment datasets. While prior disaster road damage assessment datasets exist, there is no current state of practice, as prior public datasets have either been small-scale or reliant on low-resolution imagery insufficient for detecting phenomena of interest to emergency managers. Further, while machine learning (ML) systems have been developed for this task previously, none are known to have been operationally validated. These limitations are overcome in this work through the labeling of 657.25km of roads according to a 10-class labeling schema, followed by training and deploying ML models during the operational response to Hurricanes Debby and Helene in 2024. Motivated by observed road line misalignment in practice, 9,184 road line adjustments were provided for spatial alignment of a priori road lines, as it was found that when the 18 baseline models are deployed against real-world misaligned road lines, model performance degraded on average by 5.596\% Macro IoU. If spatial alignment is not considered, approximately 8\% (11km) of adverse conditions on road lines will be labeled incorrectly, with approximately 9\% (59km) of road lines misaligned off the actual road. These dynamics are gaps that should be addressed by the ML, CV, and robotics communities to enable more effective and informed decision-making during disasters.
Now you see it, Now you don't: Damage Label Agreement in Drone & Satellite Post-Disaster Imagery
May 12, 2025
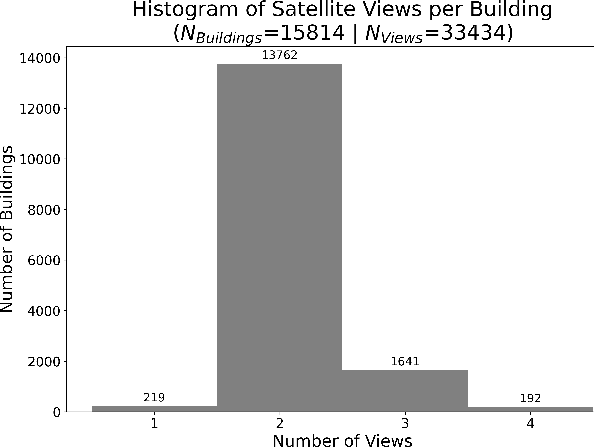

This paper audits damage labels derived from coincident satellite and drone aerial imagery for 15,814 buildings across Hurricanes Ian, Michael, and Harvey, finding 29.02% label disagreement and significantly different distributions between the two sources, which presents risks and potential harms during the deployment of machine learning damage assessment systems. Currently, there is no known study of label agreement between drone and satellite imagery for building damage assessment. The only prior work that could be used to infer if such imagery-derived labels agree is limited by differing damage label schemas, misaligned building locations, and low data quantities. This work overcomes these limitations by comparing damage labels using the same damage label schemas and building locations from three hurricanes, with the 15,814 buildings representing 19.05 times more buildings considered than the most relevant prior work. The analysis finds satellite-derived labels significantly under-report damage by at least 20.43% compared to drone-derived labels (p<1.2x10^-117), and satellite- and drone-derived labels represent significantly different distributions (p<5.1x10^-175). This indicates that computer vision and machine learning (CV/ML) models trained on at least one of these distributions will misrepresent actual conditions, as the differing satellite and drone-derived distributions cannot simultaneously represent the distribution of actual conditions in a scene. This potential misrepresentation poses ethical risks and potential societal harm if not managed. To reduce the risk of future societal harms, this paper offers four recommendations to improve reliability and transparency to decisio-makers when deploying CV/ML damage assessment systems in practice
CRASAR-U-DROIDs: A Large Scale Benchmark Dataset for Building Alignment and Damage Assessment in Georectified sUAS Imagery
Jul 24, 2024
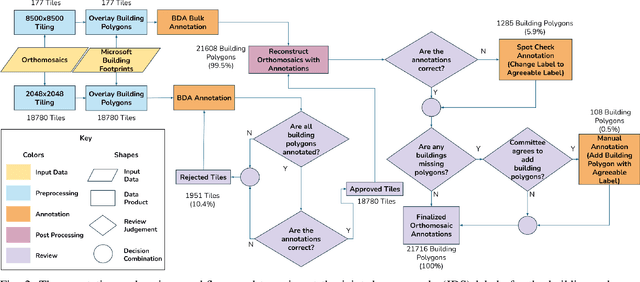

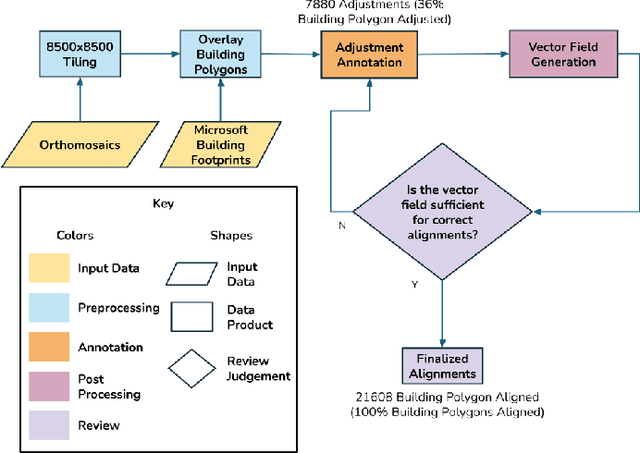
This document presents the Center for Robot Assisted Search And Rescue - Uncrewed Aerial Systems - Disaster Response Overhead Inspection Dataset (CRASAR-U-DROIDs) for building damage assessment and spatial alignment collected from small uncrewed aerial systems (sUAS) geospatial imagery. This dataset is motivated by the increasing use of sUAS in disaster response and the lack of previous work in utilizing high-resolution geospatial sUAS imagery for machine learning and computer vision models, the lack of alignment with operational use cases, and with hopes of enabling further investigations between sUAS and satellite imagery. The CRASAR-U-DRIODs dataset consists of fifty-two (52) orthomosaics from ten (10) federally declared disasters (Hurricane Ian, Hurricane Ida, Hurricane Harvey, Hurricane Idalia, Hurricane Laura, Hurricane Michael, Musset Bayou Fire, Mayfield Tornado, Kilauea Eruption, and Champlain Towers Collapse) spanning 67.98 square kilometers (26.245 square miles), containing 21,716 building polygons and damage labels, and 7,880 adjustment annotations. The imagery was tiled and presented in conjunction with overlaid building polygons to a pool of 130 annotators who provided human judgments of damage according to the Joint Damage Scale. These annotations were then reviewed via a two-stage review process in which building polygon damage labels were first reviewed individually and then again by committee. Additionally, the building polygons have been aligned spatially to precisely overlap with the imagery to enable more performant machine learning models to be trained. It appears that CRASAR-U-DRIODs is the largest labeled dataset of sUAS orthomosaic imagery.
Non-Uniform Spatial Alignment Errors in sUAS Imagery From Wide-Area Disasters
May 10, 2024

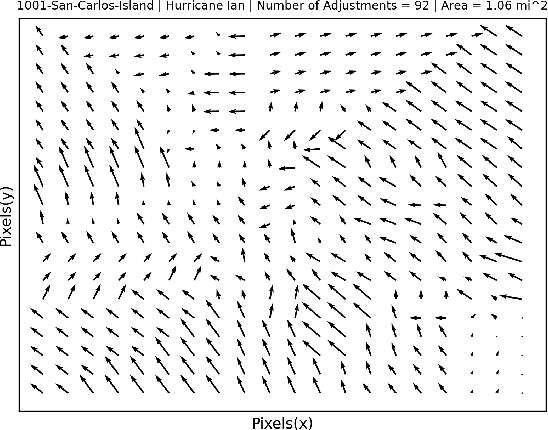
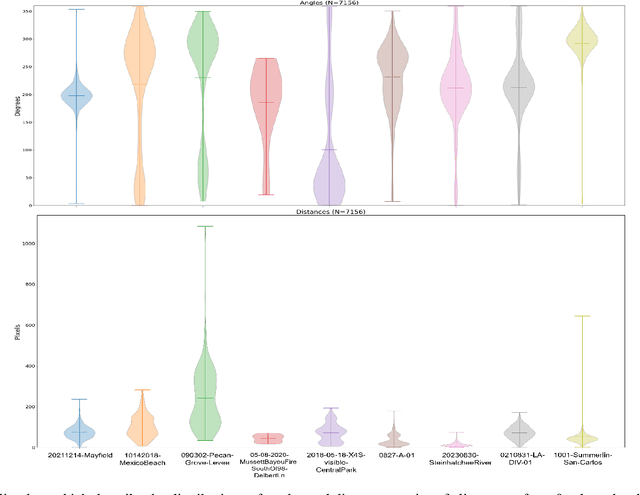
This work presents the first quantitative study of alignment errors between small uncrewed aerial systems (sUAS) geospatial imagery and a priori building polygons and finds that alignment errors are non-uniform and irregular. The work also introduces a publicly available dataset of imagery, building polygons, and human-generated and curated adjustments that can be used to evaluate existing strategies for aligning building polygons with sUAS imagery. There are no efforts that have aligned pre-existing spatial data with sUAS imagery, and thus, there is no clear state of practice. However, this effort and analysis show that the translational alignment errors present in this type of data, averaging 82px and an intersection over the union of 0.65, which would induce further errors and biases in downstream machine learning systems unless addressed. This study identifies and analyzes the translational alignment errors of 21,619 building polygons in fifty-one orthomosaic images, covering 16787.2 Acres (26.23 square miles), constructed from sUAS raw imagery from nine wide-area disasters (Hurricane Ian, Hurricane Harvey, Hurricane Michael, Hurricane Ida, Hurricane Idalia, Hurricane Laura, the Mayfield Tornado, the Musset Bayou Fire, and the Kilauea Eruption). The analysis finds no uniformity among the angle and distance metrics of the building polygon alignments as they present an average degree variance of 0.4 and an average pixel distance variance of 0.45. This work alerts the sUAS community to the problem of spatial alignment and that a simple linear transform, often used to align satellite imagery, will not be sufficient to align spatial data in sUAS orthomosaic imagery.
Differentiable Boustrophedon Path Plans
Sep 18, 2023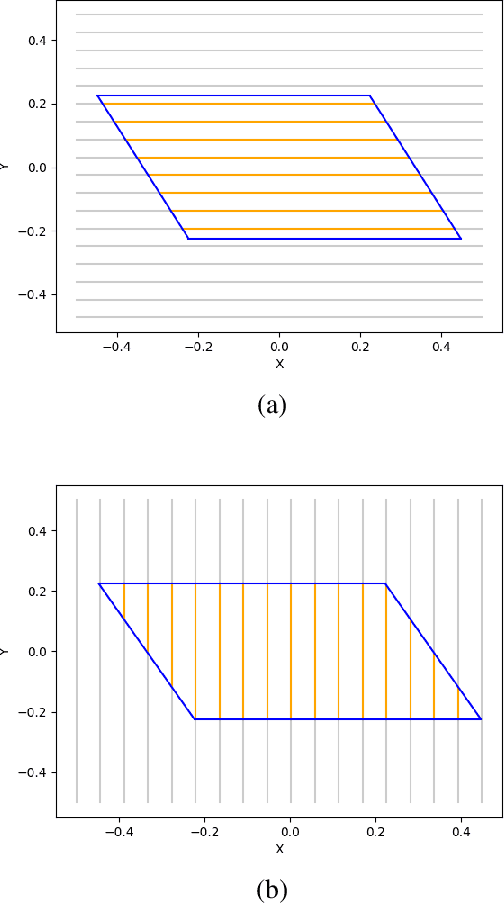
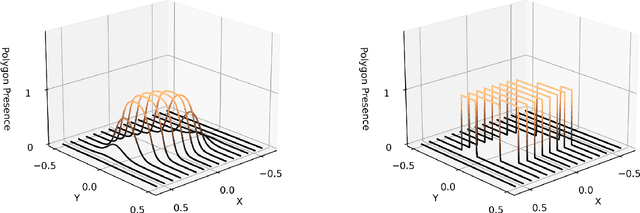
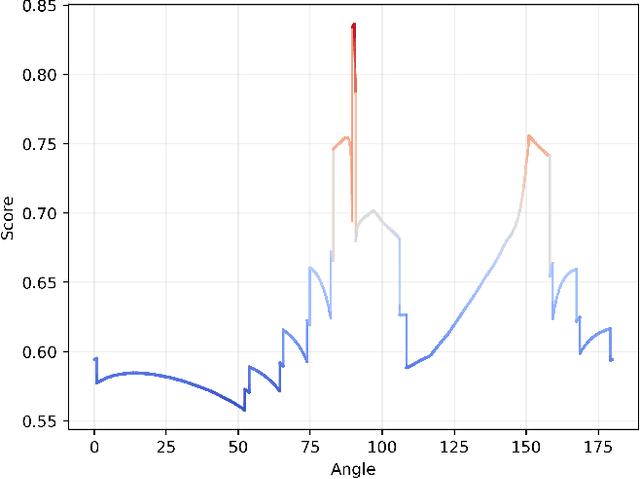
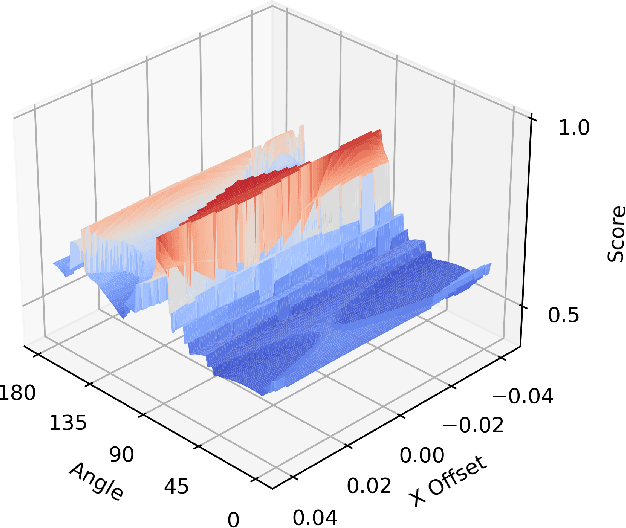
This paper introduces a differentiable representation for optimization of boustrophedon path plans in convex polygons, explores an additional parameter of these path plans that can be optimized, discusses the properties of this representation that can be leveraged during the optimization process, and shows that the previously published attempt at optimization of these path plans was too coarse to be practically useful. Experiments were conducted to show that this differentiable representation can reproduce the same scores from transitional discrete representations of boustrophedon path plans with high fidelity. Finally, optimization via gradient descent was attempted, but found to fail because the search space is far more non-convex than was previously considered in the literature. The wide range of applications for boustrophedon path plans means that this work has the potential to improve path planning efficiency in numerous areas of robotics including mapping and search tasks using uncrewed aerial systems, environmental sampling tasks using uncrewed marine vehicles, and agricultural tasks using ground vehicles, among numerous others applications.
Improving Drone Imagery For Computer Vision/Machine Learning in Wilderness Search and Rescue
Sep 05, 2023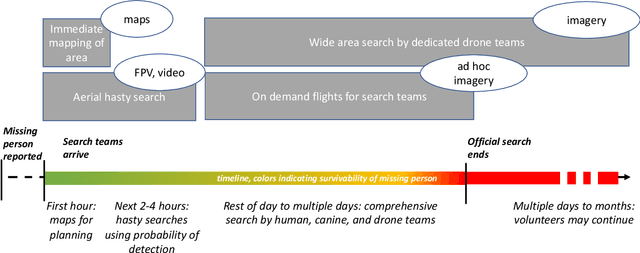
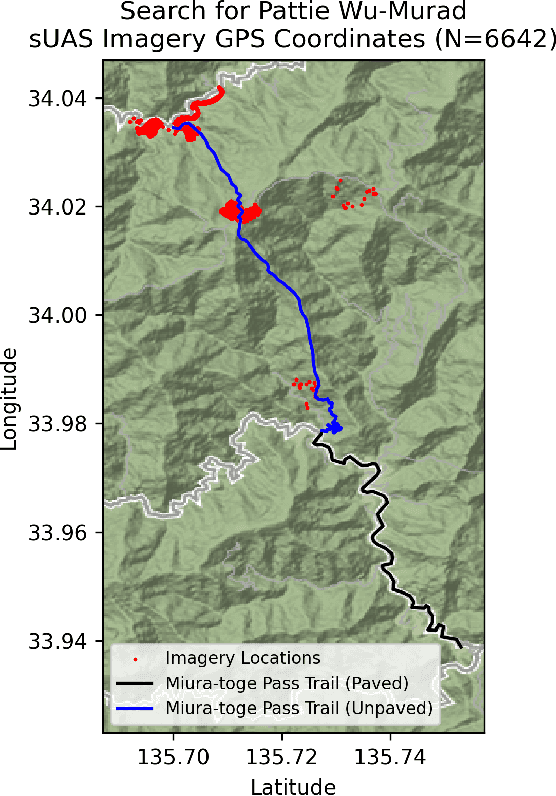


This paper describes gaps in acquisition of drone imagery that impair the use with computer vision/machine learning (CV/ML) models and makes five recommendations to maximize image suitability for CV/ML post-processing. It describes a notional work process for the use of drones in wilderness search and rescue incidents. The large volume of data from the wide area search phase offers the greatest opportunity for CV/ML techniques because of the large number of images that would otherwise have to be manually inspected. The 2023 Wu-Murad search in Japan, one of the largest missing person searches conducted in that area, serves as a case study. Although drone teams conducting wide area searches may not know in advance if the data they collect is going to be used for CV/ML post-processing, there are data collection procedures that can improve the search in general with automated collection software. If the drone teams do expect to use CV/ML, then they can exploit knowledge about the model to further optimize flights.
Quantitative Data Analysis: CRASAR Small Unmanned Aerial Systems at Hurricane Ian
Aug 28, 2023



This paper provides a summary of the 281 sorties that were flown by the 10 different models of small unmanned aerial systems (sUAS) at Hurricane Ian, and the failures made in the field. These 281 sorties, supporting 44 missions, represents the largest use of sUAS in a disaster to date (previously Hurricane Florence with 260 sorties). The sUAS operations at Hurricane Ian differ slightly from prior operations as they included the first documented uses of drones performing interior search for victims, and the first use of a VTOL fixed wing aircraft during a large scale disaster. However, there are substantive similarities to prior drone operations. Most notably, rotorcraft continue to perform the vast majority of flights, wireless data transmission capacity continues to be a limitation, and the lack of centralized control for unmanned and manned aerial systems continues to cause operational friction. This work continues by documenting the failures, both human and technological made in the field and concludes with a discussion summarizing potential areas for further work to improve sUAS response to large scale disasters.
Open Problems in Computer Vision for Wilderness SAR and The Search for Patricia Wu-Murad
Aug 10, 2023



This paper details the challenges in applying two computer vision systems, an EfficientDET supervised learning model and the unsupervised RX spectral classifier, to 98.9 GB of drone imagery from the Wu-Murad wilderness search and rescue (WSAR) effort in Japan and identifies 3 directions for future research. There have been at least 19 proposed approaches and 3 datasets aimed at locating missing persons in drone imagery, but only 3 approaches (2 unsupervised and 1 of an unknown structure) are referenced in the literature as having been used in an actual WSAR operation. Of these proposed approaches, the EfficientDET architecture and the unsupervised spectral RX classifier were selected as the most appropriate for this setting. The EfficientDET model was applied to the HERIDAL dataset and despite achieving performance that is statistically equivalent to the state-of-the-art, the model fails to translate to the real world in terms of false positives (e.g., identifying tree limbs and rocks as people), and false negatives (e.g., failing to identify members of the search team). The poor results in practice for algorithms that showed good results on datasets suggest 3 areas of future research: more realistic datasets for wilderness SAR, computer vision models that are capable of seamlessly handling the variety of imagery that can be collected during actual WSAR operations, and better alignment on performance measures.
Wireless Network Demands of Data Products from Small Uncrewed Aerial Systems at Hurricane Ian
Mar 22, 2023



Data collected at Hurricane Ian (2022) quantifies the demands that small uncrewed aerial systems (UAS), or drones, place on the network communication infrastructure and identifies gaps in the field. Drones have been increasingly used since Hurricane Katrina (2005) for disaster response, however getting the data from the drone to the appropriate decision makers throughout incident command in a timely fashion has been problematic. These delays have persisted even as countries such as the USA have made significant investments in wireless infrastructure, rapidly deployable nodes, and an increase in commercial satellite solutions. Hurricane Ian serves as a case study of the mismatch between communications needs and capabilities. In the first four days of the response, nine drone teams flew 34 missions under the direction of the State of Florida FL-UAS1, generating 636GB of data. The teams had access to six different wireless communications networks but had to resort to physically transferring data to the nearest intact emergency operations center in order to make the data available to the relevant agencies. The analysis of the mismatch contributes a model of the drone data-to-decision workflow in a disaster and quantifies wireless network communication requirements throughout the workflow in five factors. Four of the factors-availability, bandwidth, burstiness, and spatial distribution-were previously identified from analyses of Hurricanes Harvey (2017) and Michael (2018). This work adds upload rate as a fifth attribute. The analysis is expected to improve drone design and edge computing schemes as well as inform wireless communication research and development.
Black is to Criminal as Caucasian is to Police: Detecting and Removing Multiclass Bias in Word Embeddings
May 13, 2019
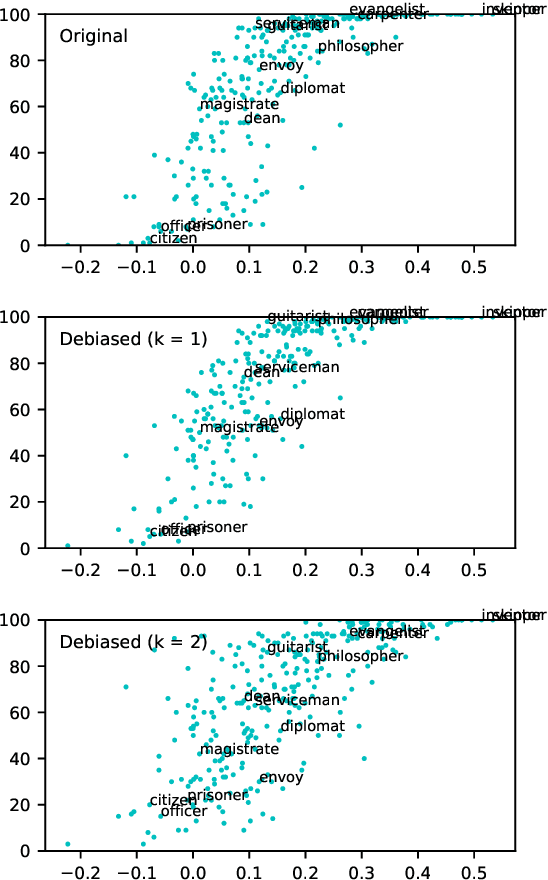

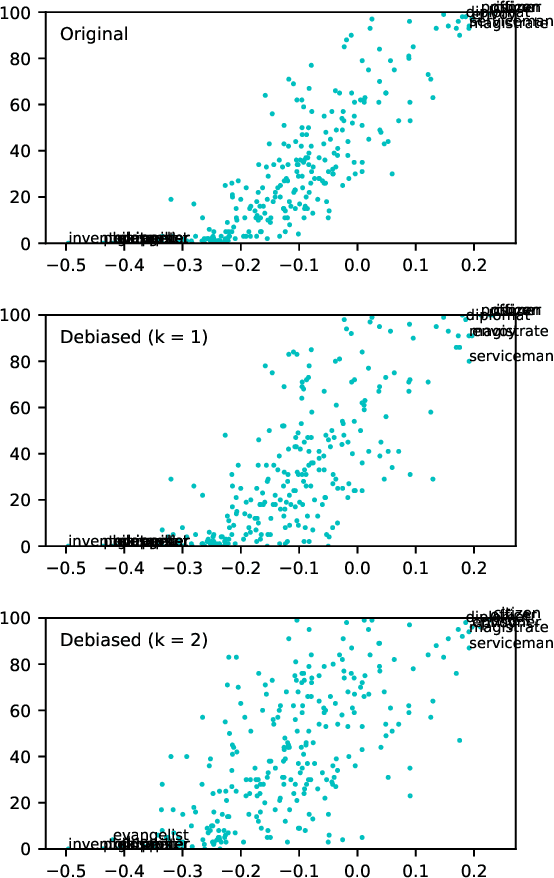
Online texts -- across genres, registers, domains, and styles -- are riddled with human stereotypes, expressed in overt or subtle ways. Word embeddings, trained on these texts, perpetuate and amplify these stereotypes, and propagate biases to machine learning models that use word embeddings as features. In this work, we propose a method to debias word embeddings in multiclass settings such as race and religion, extending the work of (Bolukbasi et al., 2016) from the binary setting, such as binary gender. Next, we propose a novel methodology for the evaluation of multiclass debiasing. We demonstrate that our multiclass debiasing is robust and maintains the efficacy in standard NLP tasks.