 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Debiasing Sentence Representations
Jul 16, 2020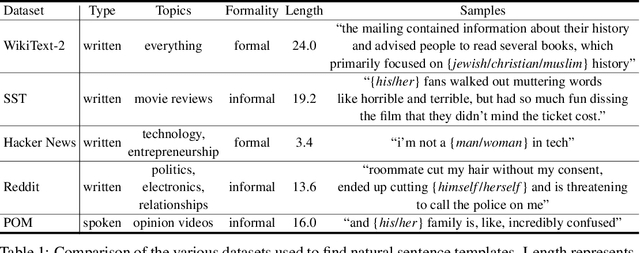
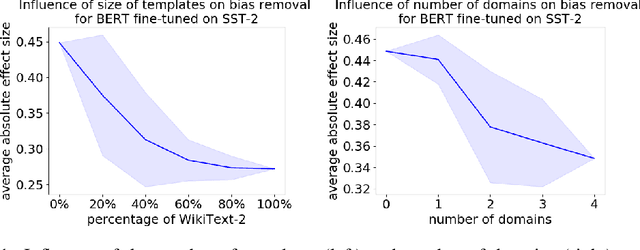

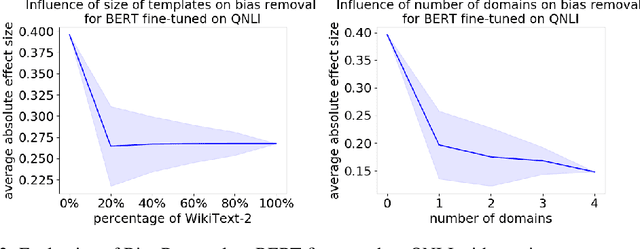
As natural language processing methods are increasingly deployed in real-world scenarios such as healthcare, legal systems, and social science, it becomes necessary to recognize the role they potentially play in shaping social biases and stereotypes. Previous work has revealed the presence of social biases in widely used word embeddings involving gender, race, religion, and other social constructs. While some methods were proposed to debias these word-level embeddings, there is a need to perform debiasing at the sentence-level given the recent shift towards new contextualized sentence representations such as ELMo and BERT. In this paper, we investigate the presence of social biases in sentence-level representations and propose a new method, Sent-Debias, to reduce these biases. We show that Sent-Debias is effective in removing biases, and at the same time, preserves performance on sentence-level downstream tasks such as sentiment analysis, linguistic acceptability, and natural language understanding. We hope that our work will inspire future research on characterizing and removing social biases from widely adopted sentence representations for fairer NLP.
Strong and Simple Baselines for Multimodal Utterance Embeddings
May 14, 2019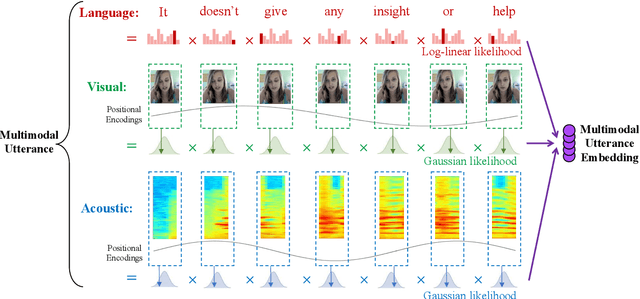

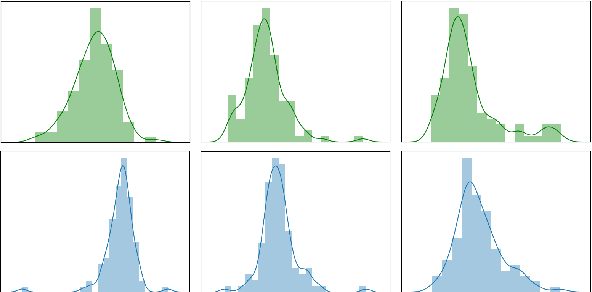

Human language is a rich multimodal signal consisting of spoken words, facial expressions, body gestures, and vocal intonations. Learning representations for these spoken utterances is a complex research problem due to the presence of multiple heterogeneous sources of information. Recent advances in multimodal learning have followed the general trend of building more complex models that utilize various attention, memory and recurrent components. In this paper, we propose two simple but strong baselines to learn embeddings of multimodal utterances. The first baseline assumes a conditional factorization of the utterance into unimodal factors. Each unimodal factor is modeled using the simple form of a likelihood function obtained via a linear transformation of the embedding. We show that the optimal embedding can be derived in closed form by taking a weighted average of the unimodal features. In order to capture richer representations, our second baseline extends the first by factorizing into unimodal, bimodal, and trimodal factors, while retaining simplicity and efficiency during learning and inference. From a set of experiments across two tasks, we show strong performance on both supervised and semi-supervised multimodal prediction, as well as significant (10 times) speedups over neural models during inference. Overall, we believe that our strong baseline models offer new benchmarking options for future research in multimodal learning.
Black is to Criminal as Caucasian is to Police: Detecting and Removing Multiclass Bias in Word Embeddings
May 13, 2019
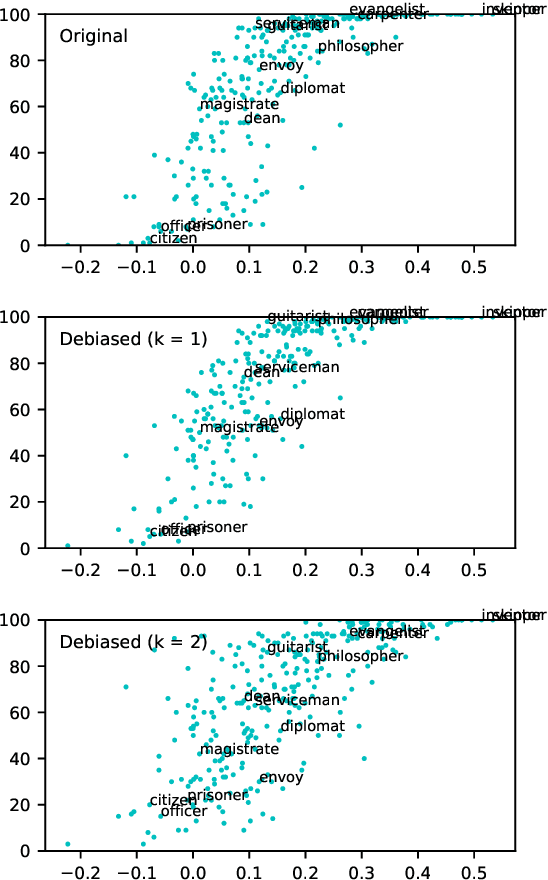

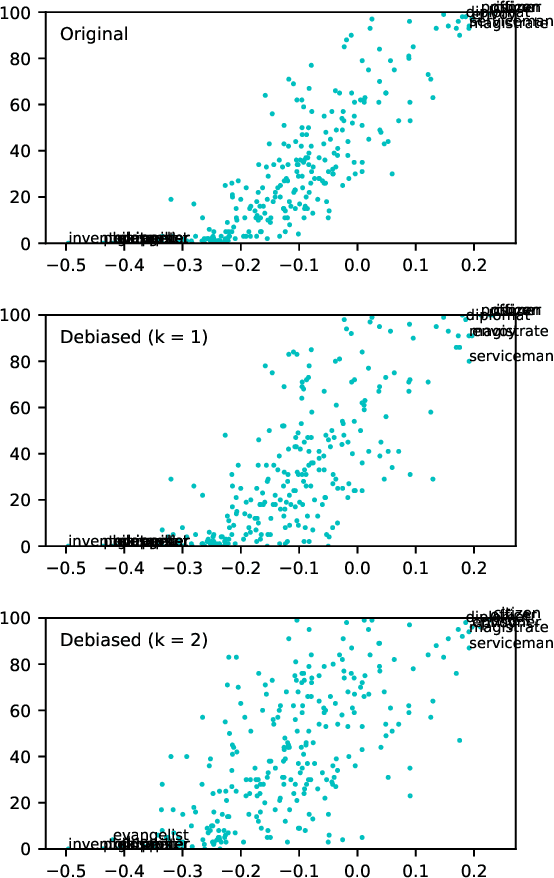
Online texts -- across genres, registers, domains, and styles -- are riddled with human stereotypes, expressed in overt or subtle ways. Word embeddings, trained on these texts, perpetuate and amplify these stereotypes, and propagate biases to machine learning models that use word embeddings as features. In this work, we propose a method to debias word embeddings in multiclass settings such as race and religion, extending the work of (Bolukbasi et al., 2016) from the binary setting, such as binary gender. Next, we propose a novel methodology for the evaluation of multiclass debiasing. We demonstrate that our multiclass debiasing is robust and maintains the efficacy in standard NLP tasks.