 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: A Vision and Intent-Aware Social Attention Framework for Multi-Agent Trajectory Prediction
Nov 13, 2025



Multi-agent trajectory prediction is crucial for autonomous systems operating in dense, interactive environments. Existing methods often fail to jointly capture agents' long-term goals and their fine-grained social interactions, which leads to unrealistic multi-agent futures. We propose VISTA, a recursive goal-conditioned transformer for multi-agent trajectory forecasting. VISTA combines (i) a cross-attention fusion module that integrates long-horizon intent with past motion, (ii) a social-token attention mechanism for flexible interaction modeling across agents, and (iii) pairwise attention maps that make social influence patterns interpretable at inference time. Our model turns single-agent goal-conditioned prediction into a coherent multi-agent forecasting framework. Beyond standard displacement metrics, we evaluate trajectory collision rates as a measure of joint realism. On the high-density MADRAS benchmark and on SDD, VISTA achieves state-of-the-art accuracy and substantially fewer collisions. On MADRAS, it reduces the average collision rate of strong baselines from 2.14 to 0.03 percent, and on SDD it attains zero collisions while improving ADE, FDE, and minFDE. These results show that VISTA generates socially compliant, goal-aware, and interpretable trajectories, making it promising for safety-critical autonomous systems.
Anomaly-Aware YOLO: A Frugal yet Robust Approach to Infrared Small Target Detection
Oct 06, 2025Infrared Small Target Detection (IRSTD) is a challenging task in defense applications, where complex backgrounds and tiny target sizes often result in numerous false alarms using conventional object detectors. To overcome this limitation, we propose Anomaly-Aware YOLO (AA-YOLO), which integrates a statistical anomaly detection test into its detection head. By treating small targets as unexpected patterns against the background, AA-YOLO effectively controls the false alarm rate. Our approach not only achieves competitive performance on several IRSTD benchmarks, but also demonstrates remarkable robustness in scenarios with limited training data, noise, and domain shifts. Furthermore, since only the detection head is modified, our design is highly generic and has been successfully applied across various YOLO backbones, including lightweight models. It also provides promising results when integrated into an instance segmentation YOLO. This versatility makes AA-YOLO an attractive solution for real-world deployments where resources are constrained. The code will be publicly released.
ICPR 2024 Competition on Domain Adaptation and GEneralization for Character Classification (DAGECC)
Dec 23, 2024In this companion paper for the DAGECC (Domain Adaptation and GEneralization for Character Classification) competition organized within the frame of the ICPR 2024 conference, we present the general context of the tasks we proposed to the community, we introduce the data that were prepared for the competition and we provide a summary of the results along with a description of the top three winning entries. The competition was centered around domain adaptation and generalization, and our core aim is to foster interest and facilitate advancement on these topics by providing a high-quality, lightweight, real world dataset able to support fast prototyping and validation of novel ideas.
Robust infrared small target detection using self-supervised and a contrario paradigms
Oct 09, 2024


Detecting small targets in infrared images poses significant challenges in defense applications due to the presence of complex backgrounds and the small size of the targets. Traditional object detection methods often struggle to balance high detection rates with low false alarm rates, especially when dealing with small objects. In this paper, we introduce a novel approach that combines a contrario paradigm with Self-Supervised Learning (SSL) to improve Infrared Small Target Detection (IRSTD). On the one hand, the integration of an a contrario criterion into a YOLO detection head enhances feature map responses for small and unexpected objects while effectively controlling false alarms. On the other hand, we explore SSL techniques to overcome the challenges of limited annotated data, common in IRSTD tasks. Specifically, we benchmark several representative SSL strategies for their effectiveness in improving small object detection performance. Our findings show that instance discrimination methods outperform masked image modeling strategies when applied to YOLO-based small object detection. Moreover, the combination of the a contrario and SSL paradigms leads to significant performance improvements, narrowing the gap with state-of-the-art segmentation methods and even outperforming them in frugal settings. This two-pronged approach offers a robust solution for improving IRSTD performance, particularly under challenging conditions.
Self-Supervised Learning for Real-World Object Detection: a Survey
Oct 09, 2024



Self-Supervised Learning (SSL) has emerged as a promising approach in computer vision, enabling networks to learn meaningful representations from large unlabeled datasets. SSL methods fall into two main categories: instance discrimination and Masked Image Modeling (MIM). While instance discrimination is fundamental to SSL, it was originally designed for classification and may be less effective for object detection, particularly for small objects. In this survey, we focus on SSL methods specifically tailored for real-world object detection, with an emphasis on detecting small objects in complex environments. Unlike previous surveys, we offer a detailed comparison of SSL strategies, including object-level instance discrimination and MIM methods, and assess their effectiveness for small object detection using both CNN and ViT-based architectures. Specifically, our benchmark is performed on the widely-used COCO dataset, as well as on a specialized real-world dataset focused on vehicle detection in infrared remote sensing imagery. We also assess the impact of pre-training on custom domain-specific datasets, highlighting how certain SSL strategies are better suited for handling uncurated data. Our findings highlight that instance discrimination methods perform well with CNN-based encoders, while MIM methods are better suited for ViT-based architectures and custom dataset pre-training. This survey provides a practical guide for selecting optimal SSL strategies, taking into account factors such as backbone architecture, object size, and custom pre-training requirements. Ultimately, we show that choosing an appropriate SSL pre-training strategy, along with a suitable encoder, significantly enhances performance in real-world object detection, particularly for small object detection in frugal settings.
$\textit{A Contrario}$ Paradigm for YOLO-based Infrared Small Target Detection
Feb 03, 2024



Detecting small to tiny targets in infrared images is a challenging task in computer vision, especially when it comes to differentiating these targets from noisy or textured backgrounds. Traditional object detection methods such as YOLO struggle to detect tiny objects compared to segmentation neural networks, resulting in weaker performance when detecting small targets. To reduce the number of false alarms while maintaining a high detection rate, we introduce an $\textit{a contrario}$ decision criterion into the training of a YOLO detector. The latter takes advantage of the $\textit{unexpectedness}$ of small targets to discriminate them from complex backgrounds. Adding this statistical criterion to a YOLOv7-tiny bridges the performance gap between state-of-the-art segmentation methods for infrared small target detection and object detection networks. It also significantly increases the robustness of YOLO towards few-shot settings.
Evaluating Crowd Density Estimators via Their Uncertainty Bounds
Feb 07, 2019
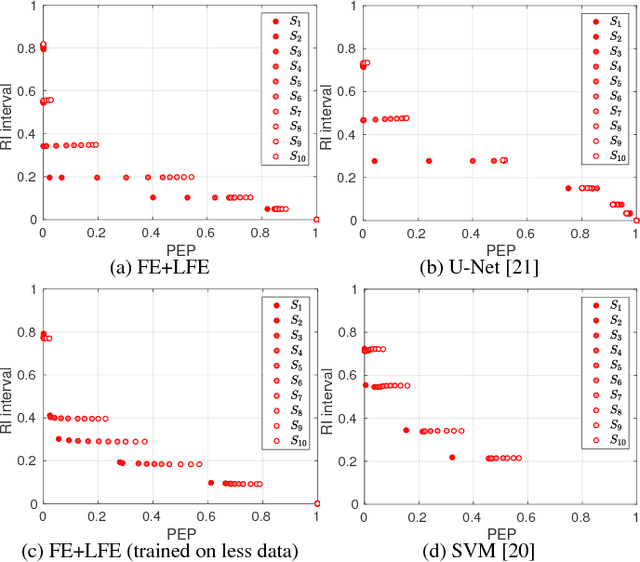

In this work, we use the Belief Function Theory which extends the probabilistic framework in order to provide uncertainty bounds to different categories of crowd density estimators. Our method allows us to compare the multi-scale performance of the estimators, and also to characterize their reliability for crowd monitoring applications requiring varying degrees of prudence.
Geometry-Based Multiple Camera Head Detection in Dense Crowds
Aug 02, 2018
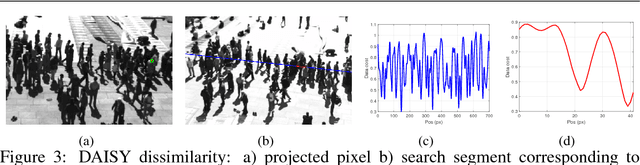

This paper addresses the problem of head detection in crowded environments. Our detection is based entirely on the geometric consistency across cameras with overlapping fields of view, and no additional learning process is required. We propose a fully unsupervised method for inferring scene and camera geometry, in contrast to existing algorithms which require specific calibration procedures. Moreover, we avoid relying on the presence of body parts other than heads or on background subtraction, which have limited effectiveness under heavy clutter. We cast the head detection problem as a stereo MRF-based optimization of a dense pedestrian height map, and we introduce a constraint which aligns the height gradient according to the vertical vanishing point direction. We validate the method in an outdoor setting with varying pedestrian density levels. With only three views, our approach is able to detect simultaneously tens of heavily occluded pedestrians across a large, homogeneous area.
Efficient Evaluation of the Number of False Alarm Criterion
Jul 10, 2018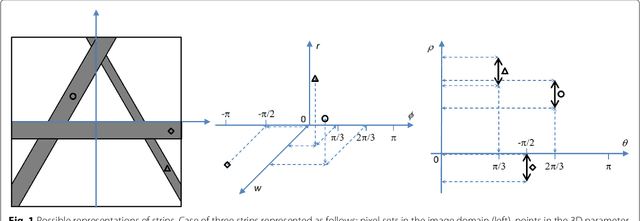

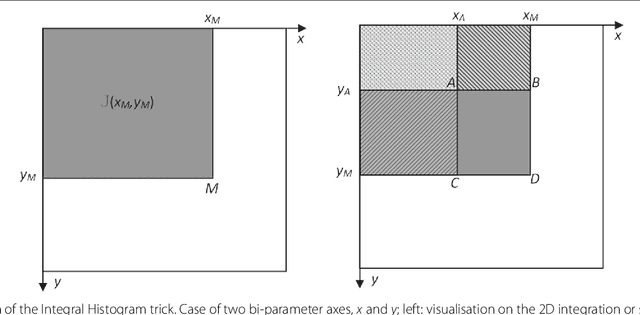
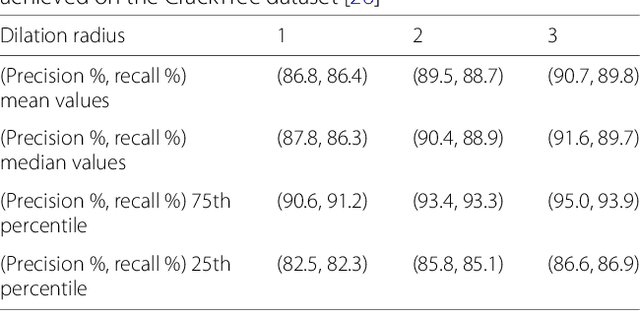
This paper proposes a method for computing efficiently the significance of a parametric pattern inside a binary image. On the one hand, a-contrario strategies avoid the user involvement for tuning detection thresholds, and allow one to account fairly for different pattern sizes. On the other hand, a-contrario criteria become intractable when the pattern complexity in terms of parametrization increases. In this work, we introduce a strategy which relies on the use of a cumulative space of reduced dimensionality, derived from the coupling of a classic (Hough) cumulative space with an integral histogram trick. This space allows us to store partial computations which are required by the a-contrario criterion, and to evaluate the significance with a lower computational cost than by following a straightforward approach. The method is illustrated on synthetic examples on patterns with various parametrizations up to five dimensions. In order to demonstrate how to apply this generic concept in a real scenario, we consider a difficult crack detection task in still images, which has been addressed in the literature with various local and global detection strategies. We model cracks as bounded segments, detected by the proposed a-contrario criterion, which allow us to introduce additional spatial constraints based on their relative alignment. On this application, the proposed strategy yields state-of the-art results, and underlines its potential for handling complex pattern detection tasks.
2CoBel : An Efficient Belief Function Extension for Two-dimensional Continuous Spaces
Mar 23, 2018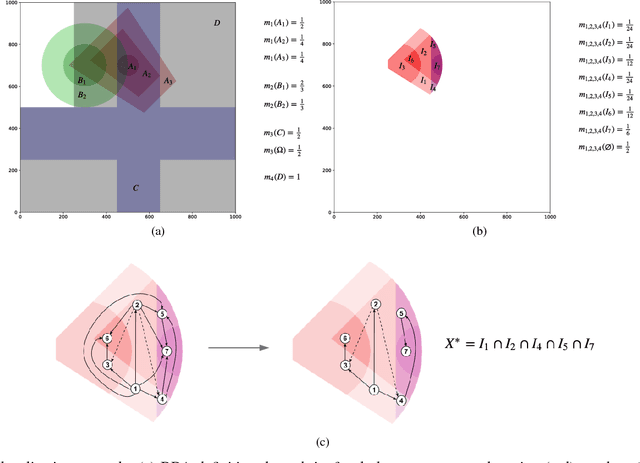
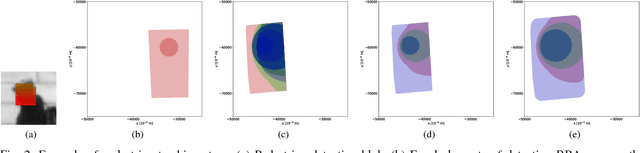
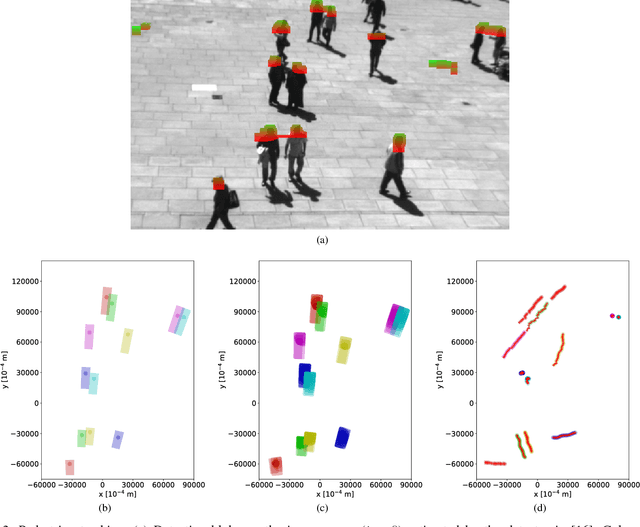
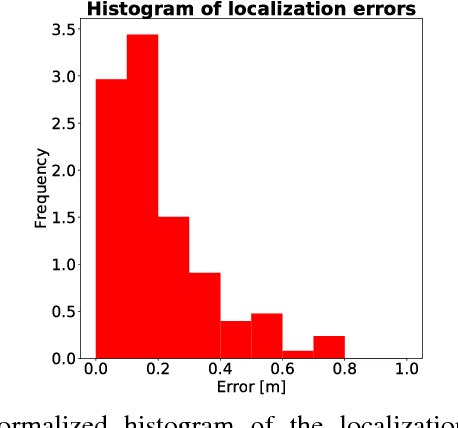
This paper introduces an innovative approach for handling 2D compound hypotheses within the Belief Function Theory framework. We propose a polygon-based generic rep- resentation which relies on polygon clipping operators. This approach allows us to account in the computational cost for the precision of the representation independently of the cardinality of the discernment frame. For the BBA combination and decision making, we propose efficient algorithms which rely on hashes for fast lookup, and on a topological ordering of the focal elements within a directed acyclic graph encoding their interconnections. Additionally, an implementation of the functionalities proposed in this paper is provided as an open source library. Experimental results on a pedestrian localization problem are reported. The experiments show that the solution is accurate and that it fully benefits from the scalability of the 2D search space granularity provided by our representation.