 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly-Aware YOLO: A Frugal yet Robust Approach to Infrared Small Target Detection
Oct 06, 2025Infrared Small Target Detection (IRSTD) is a challenging task in defense applications, where complex backgrounds and tiny target sizes often result in numerous false alarms using conventional object detectors. To overcome this limitation, we propose Anomaly-Aware YOLO (AA-YOLO), which integrates a statistical anomaly detection test into its detection head. By treating small targets as unexpected patterns against the background, AA-YOLO effectively controls the false alarm rate. Our approach not only achieves competitive performance on several IRSTD benchmarks, but also demonstrates remarkable robustness in scenarios with limited training data, noise, and domain shifts. Furthermore, since only the detection head is modified, our design is highly generic and has been successfully applied across various YOLO backbones, including lightweight models. It also provides promising results when integrated into an instance segmentation YOLO. This versatility makes AA-YOLO an attractive solution for real-world deployments where resources are constrained. The code will be publicly released.
Self-Supervised Learning for Real-World Object Detection: a Survey
Oct 09, 2024



Self-Supervised Learning (SSL) has emerged as a promising approach in computer vision, enabling networks to learn meaningful representations from large unlabeled datasets. SSL methods fall into two main categories: instance discrimination and Masked Image Modeling (MIM). While instance discrimination is fundamental to SSL, it was originally designed for classification and may be less effective for object detection, particularly for small objects. In this survey, we focus on SSL methods specifically tailored for real-world object detection, with an emphasis on detecting small objects in complex environments. Unlike previous surveys, we offer a detailed comparison of SSL strategies, including object-level instance discrimination and MIM methods, and assess their effectiveness for small object detection using both CNN and ViT-based architectures. Specifically, our benchmark is performed on the widely-used COCO dataset, as well as on a specialized real-world dataset focused on vehicle detection in infrared remote sensing imagery. We also assess the impact of pre-training on custom domain-specific datasets, highlighting how certain SSL strategies are better suited for handling uncurated data. Our findings highlight that instance discrimination methods perform well with CNN-based encoders, while MIM methods are better suited for ViT-based architectures and custom dataset pre-training. This survey provides a practical guide for selecting optimal SSL strategies, taking into account factors such as backbone architecture, object size, and custom pre-training requirements. Ultimately, we show that choosing an appropriate SSL pre-training strategy, along with a suitable encoder, significantly enhances performance in real-world object detection, particularly for small object detection in frugal settings.
Robust infrared small target detection using self-supervised and a contrario paradigms
Oct 09, 2024


Detecting small targets in infrared images poses significant challenges in defense applications due to the presence of complex backgrounds and the small size of the targets. Traditional object detection methods often struggle to balance high detection rates with low false alarm rates, especially when dealing with small objects. In this paper, we introduce a novel approach that combines a contrario paradigm with Self-Supervised Learning (SSL) to improve Infrared Small Target Detection (IRSTD). On the one hand, the integration of an a contrario criterion into a YOLO detection head enhances feature map responses for small and unexpected objects while effectively controlling false alarms. On the other hand, we explore SSL techniques to overcome the challenges of limited annotated data, common in IRSTD tasks. Specifically, we benchmark several representative SSL strategies for their effectiveness in improving small object detection performance. Our findings show that instance discrimination methods outperform masked image modeling strategies when applied to YOLO-based small object detection. Moreover, the combination of the a contrario and SSL paradigms leads to significant performance improvements, narrowing the gap with state-of-the-art segmentation methods and even outperforming them in frugal settings. This two-pronged approach offers a robust solution for improving IRSTD performance, particularly under challenging conditions.
$\textit{A Contrario}$ Paradigm for YOLO-based Infrared Small Target Detection
Feb 03, 2024



Detecting small to tiny targets in infrared images is a challenging task in computer vision, especially when it comes to differentiating these targets from noisy or textured backgrounds. Traditional object detection methods such as YOLO struggle to detect tiny objects compared to segmentation neural networks, resulting in weaker performance when detecting small targets. To reduce the number of false alarms while maintaining a high detection rate, we introduce an $\textit{a contrario}$ decision criterion into the training of a YOLO detector. The latter takes advantage of the $\textit{unexpectedness}$ of small targets to discriminate them from complex backgrounds. Adding this statistical criterion to a YOLOv7-tiny bridges the performance gap between state-of-the-art segmentation methods for infrared small target detection and object detection networks. It also significantly increases the robustness of YOLO towards few-shot settings.
Deep-NFA: a Deep $\textit{a contrario}$ Framework for Small Object Detection
Mar 02, 2023



The detection of small objects is a challenging task in computer vision. Conventional object detection methods have difficulty in finding the balance between high detection and low false alarm rates. In the literature, some methods have addressed this issue by enhancing the feature map responses, but without guaranteeing robustness with respect to the number of false alarms induced by background elements. To tackle this problem, we introduce an $\textit{a contrario}$ decision criterion into the learning process to take into account the unexpectedness of small objects. This statistic criterion enhances the feature map responses while controlling the number of false alarms (NFA) and can be integrated into any semantic segmentation neural network. Our add-on NFA module not only allows us to obtain competitive results for small target and crack detection tasks respectively, but also leads to more robust and interpretable results.
Détection de petites cibles par apprentissage profond et critère a contrario
Oct 03, 2022

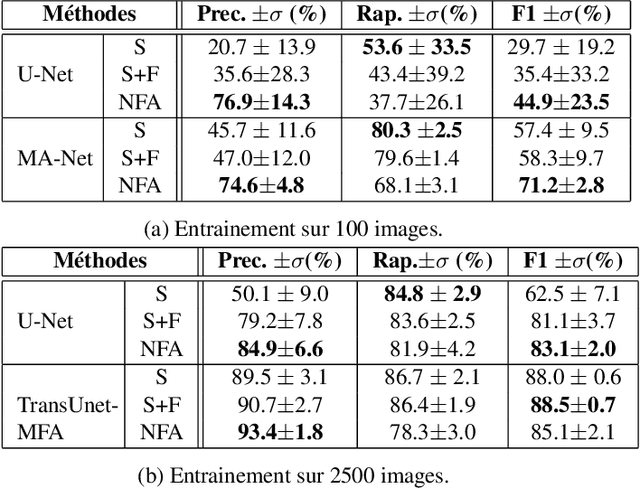
Small target detection is an essential yet challenging task in defense applications, since differentiating low-contrast targets from natural textured and noisy environment remains difficult. To better take into account the contextual information, we propose to explore deep learning approaches based on attention mechanisms. Specifically, we propose a customized version of TransUnet including channel attention, which has shown a significant improvement in performance. Moreover, the lack of annotated data induces weak detection precision, leading to many false alarms. We thus explore a contrario methods in order to select meaningful potential targets detected by a weak deep learning training. -- La d\'etection de petites cibles est une probl\'ematique d\'elicate mais essentielle dans le domaine de la d\'efense, notamment lorsqu'il s'agit de diff\'erencier ces cibles d'un fond bruit\'e ou textur\'e, ou lorsqu'elles sont de faible contraste. Pour mieux prendre en compte les informations contextuelles, nous proposons d'explorer diff\'erentes approches de segmentation par apprentissage profond, dont certaines bas\'ees sur les m\'ecanismes d'attention. Nous proposons \'egalement d'inclure un module d'attention par canal au TransUnet, r\'eseau \`a l'\'etat de l'art, ce qui permet d'am\'eliorer significativement les performances. Par ailleurs, le manque de donn\'ees annot\'ees induit une perte en pr\'ecision lors des d\'etections, conduisant \`a de nombreuses fausses alarmes non pertinentes. Nous explorons donc des m\'ethodes a contrario afin de s\'electionner les cibles les plus significatives d\'etect\'ees par un r\'eseau entra\^in\'e avec peu de donn\'ees.
* 4 pages, in French