 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric as Transform: Exploring beyond Affine Transform for Interpretable Neural Network
Oct 21, 2024


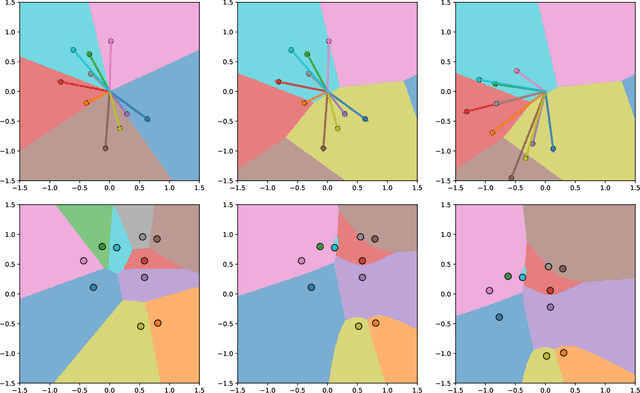
Artificial Neural Networks of varying architectures are generally paired with affine transformation at the core. However, we find dot product neurons with global influence less interpretable as compared to local influence of euclidean distance (as used in Radial Basis Function Network). In this work, we explore the generalization of dot product neurons to $l^p$-norm, metrics, and beyond. We find that metrics as transform performs similarly to affine transform when used in MultiLayer Perceptron or Convolutional Neural Network. Moreover, we explore various properties of Metrics, compare it with Affine, and present multiple cases where metrics seem to provide better interpretability. We develop an interpretable local dictionary based Neural Networks and use it to understand and reject adversarial examples.
Dimension Mixer: A Generalized Method for Structured Sparsity in Deep Neural Networks
Nov 30, 2023The recent success of multiple neural architectures like CNNs, Transformers, and MLP-Mixers motivated us to look for similarities and differences between them. We found that these architectures can be interpreted through the lens of a general concept of dimension mixing. Research on coupling flows and the butterfly transform shows that partial and hierarchical signal mixing schemes are sufficient for efficient and expressive function approximation. In this work, we study group-wise sparse, non-linear, multi-layered and learnable mixing schemes of inputs and find that they are complementary to many standard neural architectures. Following our observations and drawing inspiration from the Fast Fourier Transform, we generalize Butterfly Structure to use non-linear mixer function allowing for MLP as mixing function called Butterfly MLP. We were also able to mix along sequence dimension for Transformer-based architectures called Butterfly Attention. Experiments on CIFAR and LRA datasets demonstrate that the proposed Non-Linear Butterfly Mixers are efficient and scale well when the host architectures are used as mixing function. Additionally, we propose Patch-Only MLP-Mixer for processing spatial 2D signals demonstrating a different dimension mixing strategy.
Importance Estimation with Random Gradient for Neural Network Pruning
Oct 31, 2023Global Neuron Importance Estimation is used to prune neural networks for efficiency reasons. To determine the global importance of each neuron or convolutional kernel, most of the existing methods either use activation or gradient information or both, which demands abundant labelled examples. In this work, we use heuristics to derive importance estimation similar to Taylor First Order (TaylorFO) approximation based methods. We name our methods TaylorFO-abs and TaylorFO-sq. We propose two additional methods to improve these importance estimation methods. Firstly, we propagate random gradients from the last layer of a network, thus avoiding the need for labelled examples. Secondly, we normalize the gradient magnitude of the last layer output before propagating, which allows all examples to contribute similarly to the importance score. Our methods with additional techniques perform better than previous methods when tested on ResNet and VGG architectures on CIFAR-100 and STL-10 datasets. Furthermore, our method also complements the existing methods and improves their performances when combined with them.
Neural Network Pruning for Real-time Polyp Segmentation
Jun 22, 2023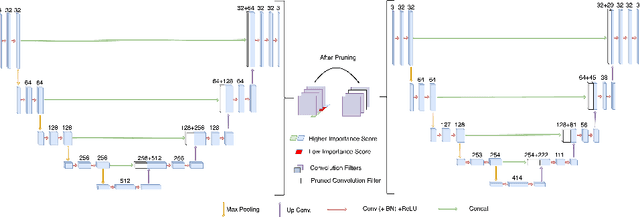
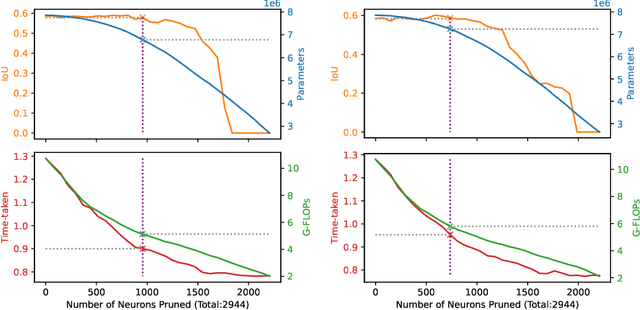
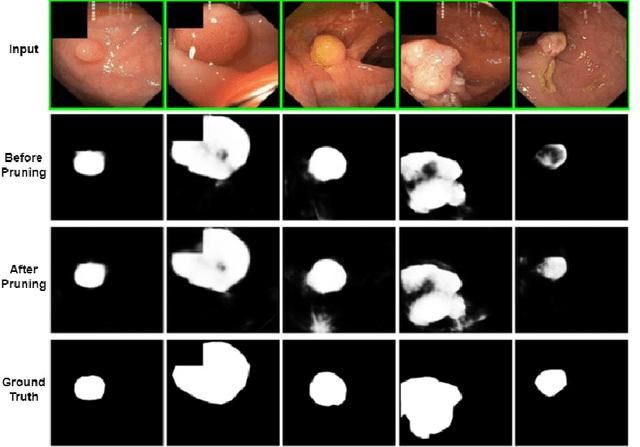
Computer-assisted treatment has emerged as a viable application of medical imaging, owing to the efficacy of deep learning models. Real-time inference speed remains a key requirement for such applications to help medical personnel. Even though there generally exists a trade-off between performance and model size, impressive efforts have been made to retain near-original performance by compromising model size. Neural network pruning has emerged as an exciting area that aims to eliminate redundant parameters to make the inference faster. In this study, we show an application of neural network pruning in polyp segmentation. We compute the importance score of convolutional filters and remove the filters having the least scores, which to some value of pruning does not degrade the performance. For computing the importance score, we use the Taylor First Order (TaylorFO) approximation of the change in network output for the removal of certain filters. Specifically, we employ a gradient-normalized backpropagation for the computation of the importance score. Through experiments in the polyp datasets, we validate that our approach can significantly reduce the parameter count and FLOPs retaining similar performance.
Noisy Heuristics NAS: A Network Morphism based Neural Architecture Search using Heuristics
Jul 10, 2022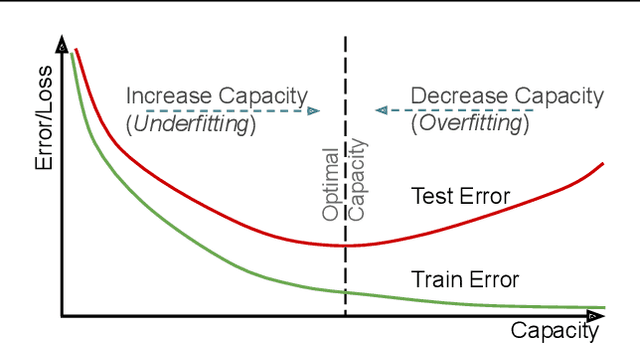

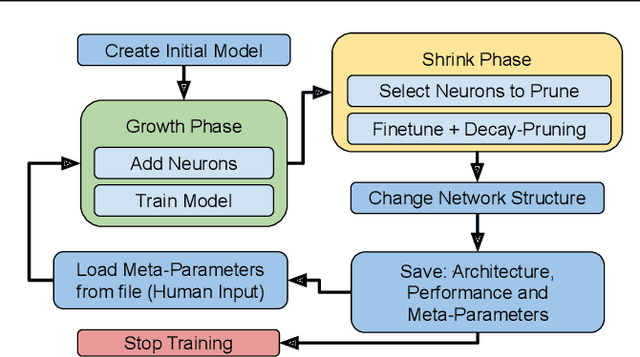
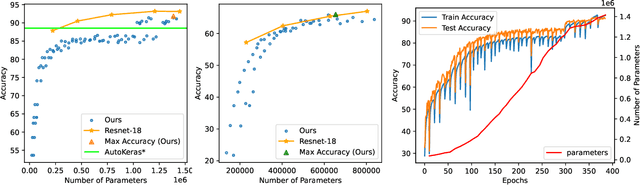
Network Morphism based Neural Architecture Search (NAS) is one of the most efficient methods, however, knowing where and when to add new neurons or remove dis-functional ones is generally left to black-box Reinforcement Learning models. In this paper, we present a new Network Morphism based NAS called Noisy Heuristics NAS which uses heuristics learned from manually developing neural network models and inspired by biological neuronal dynamics. Firstly, we add new neurons randomly and prune away some to select only the best fitting neurons. Secondly, we control the number of layers in the network using the relationship of hidden units to the number of input-output connections. Our method can increase or decrease the capacity or non-linearity of models online which is specified with a few meta-parameters by the user. Our method generalizes both on toy datasets and on real-world data sets such as MNIST, CIFAR-10, and CIFAR-100. The performance is comparable to the hand-engineered architecture ResNet-18 with the similar parameters.
Brand Label Albedo Extraction of eCommerce Products using Generative Adversarial Network
Sep 07, 2021
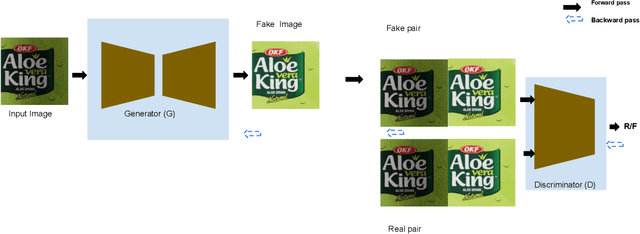


In this paper we present our solution to extract albedo of branded labels for e-commerce products. To this end, we generate a large-scale photo-realistic synthetic data set for albedo extraction followed by training a generative model to translate images with diverse lighting conditions to albedo. We performed an extensive evaluation to test the generalisation of our method to in-the-wild images. From the experimental results, we observe that our solution generalises well compared to the existing method both in the unseen rendered images as well as in the wild image.
Input Invex Neural Network
Jun 16, 2021

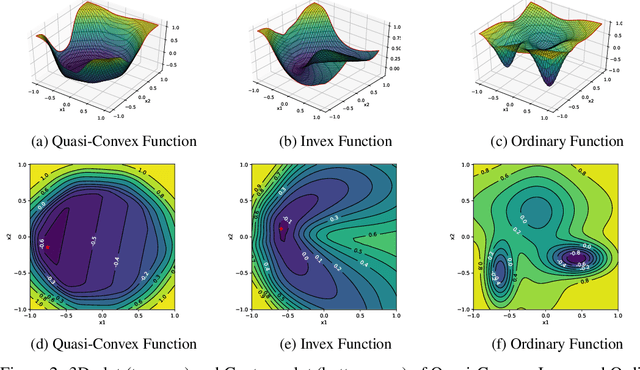
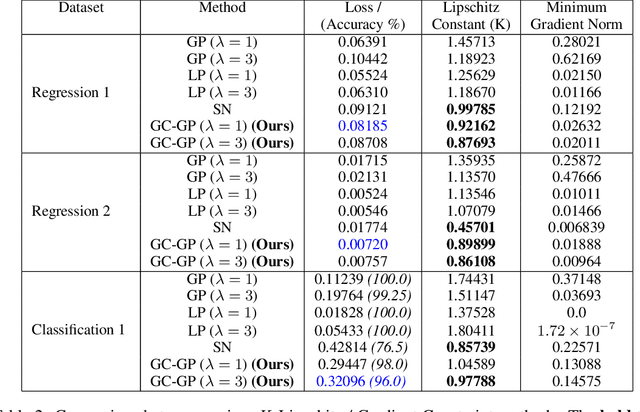
In this paper, we present a novel method to constrain invexity on Neural Networks (NN). Invex functions ensure every stationary point is global minima. Hence, gradient descent commenced from any point will lead to the global minima. Another advantage of invexity on NN is to divide data space locally into two connected sets with a highly non-linear decision boundary by simply thresholding the output. To this end, we formulate a universal invex function approximator and employ it to enforce invexity in NN. We call it Input Invex Neural Networks (II-NN). We first fit data with a known invex function, followed by modification with a NN, compare the direction of the gradient and penalize the direction of gradient on NN if it contradicts with the direction of reference invex function. In order to penalize the direction of the gradient we perform Gradient Clipped Gradient Penalty (GC-GP). We applied our method to the existing NNs for both image classification and regression tasks. From the extensive empirical and qualitative experiments, we observe that our method gives the performance similar to ordinary NN yet having invexity. Our method outperforms linear NN and Input Convex Neural Network (ICNN) with a large margin. We publish our code and implementation details at github.
Label Geometry Aware Discriminator for Conditional Generative Networks
May 12, 2021
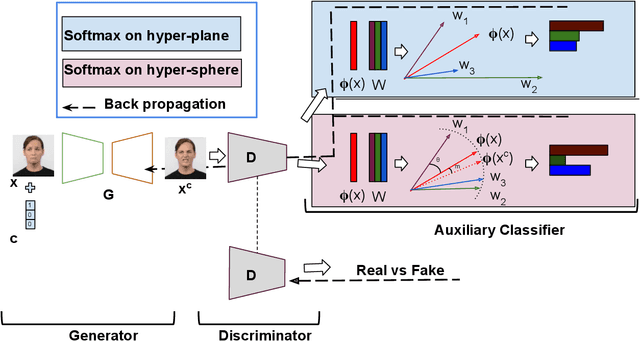
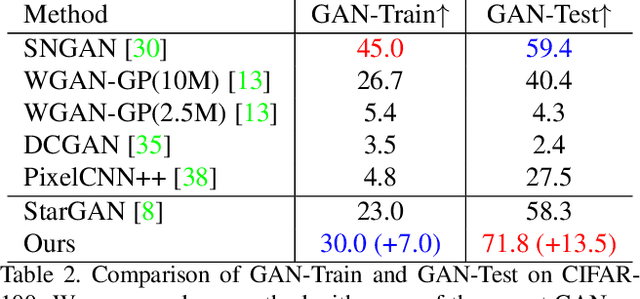

Multi-domain image-to-image translation with conditional Generative Adversarial Networks (GANs) can generate highly photo realistic images with desired target classes, yet these synthetic images have not always been helpful to improve downstream supervised tasks such as image classification. Improving downstream tasks with synthetic examples requires generating images with high fidelity to the unknown conditional distribution of the target class, which many labeled conditional GANs attempt to achieve by adding soft-max cross-entropy loss based auxiliary classifier in the discriminator. As recent studies suggest that the soft-max loss in Euclidean space of deep feature does not leverage their intrinsic angular distribution, we propose to replace this loss in auxiliary classifier with an additive angular margin (AAM) loss that takes benefit of the intrinsic angular distribution, and promotes intra-class compactness and inter-class separation to help generator synthesize high fidelity images. We validate our method on RaFD and CIFAR-100, two challenging face expression and natural image classification data set. Our method outperforms state-of-the-art methods in several different evaluation criteria including recently proposed GAN-train and GAN-test metrics designed to assess the impact of synthetic data on downstream classification task, assessing the usefulness in data augmentation for supervised tasks with prediction accuracy score and average confidence score, and the well known FID metric.