 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScheduling for Urban Air Mobility using Safe Learning
Sep 28, 2022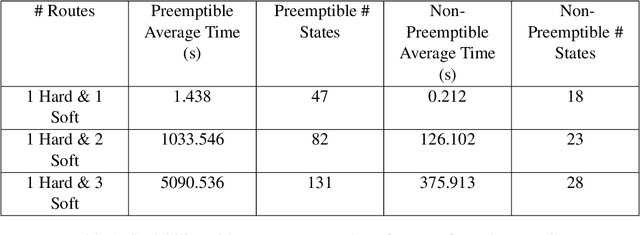

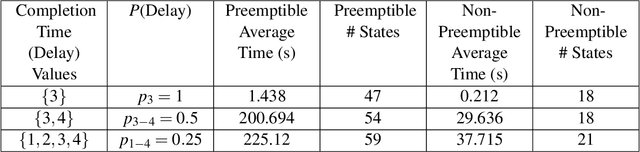
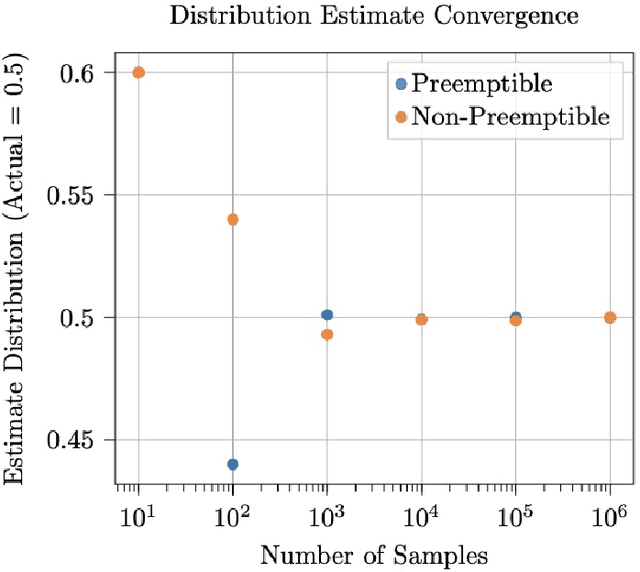
This work considers the scheduling problem for Urban Air Mobility (UAM) vehicles travelling between origin-destination pairs with both hard and soft trip deadlines. Each route is described by a discrete probability distribution over trip completion times (or delay) and over inter-arrival times of requests (or demand) for the route along with a fixed hard or soft deadline. Soft deadlines carry a cost that is incurred when the deadline is missed. An online, safe scheduler is developed that ensures that hard deadlines are never missed, and that average cost of missing soft deadlines is minimized. The system is modelled as a Markov Decision Process (MDP) and safe model-based learning is used to find the probabilistic distributions over route delays and demand. Monte Carlo Tree Search (MCTS) Earliest Deadline First (EDF) is used to safely explore the learned models in an online fashion and develop a near-optimal non-preemptive scheduling policy. These results are compared with Value Iteration (VI) and MCTS (Random) scheduling solutions.
* In Proceedings FMAS2022 ASYDE2022, arXiv:2209.13181
Safe Multi-Agent Reinforcement Learning via Shielding
Feb 02, 2021



Multi-agent reinforcement learning (MARL) has been increasingly used in a wide range of safety-critical applications, which require guaranteed safety (e.g., no unsafe states are ever visited) during the learning process.Unfortunately, current MARL methods do not have safety guarantees. Therefore, we present two shielding approaches for safe MARL. In centralized shielding, we synthesize a single shield to monitor all agents' joint actions and correct any unsafe action if necessary. In factored shielding, we synthesize multiple shields based on a factorization of the joint state space observed by all agents; the set of shields monitors agents concurrently and each shield is only responsible for a subset of agents at each step.Experimental results show that both approaches can guarantee the safety of agents during learning without compromising the quality of learned policies; moreover, factored shielding is more scalable in the number of agents than centralized shielding.
Near-Optimal Reactive Synthesis Incorporating Runtime Information
Jul 31, 2020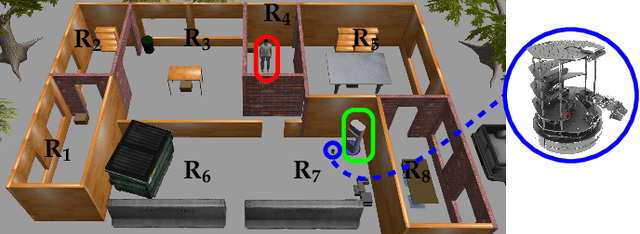
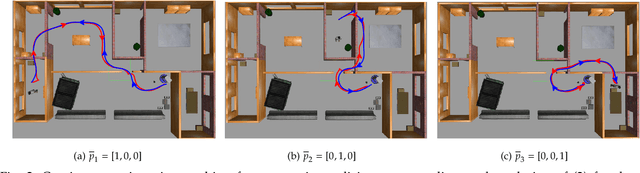
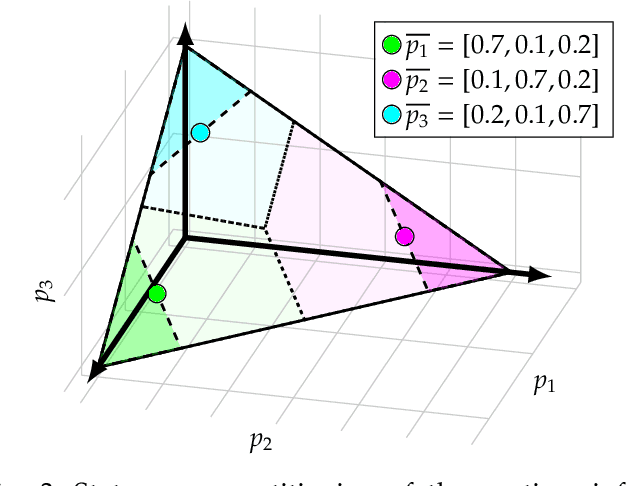
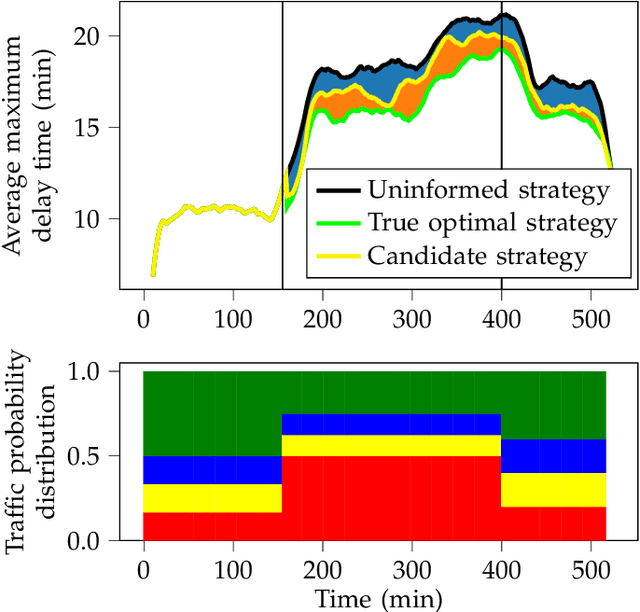
We consider the problem of optimal reactive synthesis - compute a strategy that satisfies a mission specification in a dynamic environment, and optimizes a performance metric. We incorporate task-critical information, that is only available at runtime, into the strategy synthesis in order to improve performance. Existing approaches to utilising such time-varying information require online re-synthesis, which is not computationally feasible in real-time applications. In this paper, we pre-synthesize a set of strategies corresponding to candidate instantiations (pre-specified representative information scenarios). We then propose a novel switching mechanism to dynamically switch between the strategies at runtime while guaranteeing all safety and liveness goals are met. We also characterize bounds on the performance suboptimality. We demonstrate our approach on two examples - robotic motion planning where the likelihood of the position of the robot's goal is updated in real-time, and an air traffic management problem for urban air mobility.
Strategy Synthesis for Surveillance-Evasion Games with Learning-Enabled Visibility Optimization
Nov 18, 2019

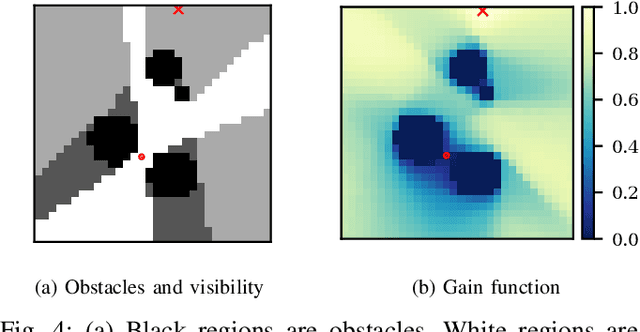
This paper studies a two-player game with a quantitative surveillance requirement on an adversarial target moving in a discrete state space and a secondary objective to maximize short-term visibility of the environment. We impose the surveillance requirement as a temporal logic constraint.We then use a greedy approach to determine vantage points that optimize a notion of information gain, namely, the number of newly-seen states. By using a convolutional neural network trained on a class of environments, we can efficiently approximate the information gain at each potential vantage point.Subsequent vantage points are chosen such that moving to that location will not jeopardize the surveillance requirement, regardless of any future action chosen by the target. Our method combines guarantees of correctness from formal methods with the scalability of machine learning to provide an efficient approach for surveillance-constrained visibility optimization.
Decentralized Runtime Synthesis of Shields for Multi-Agent Systems
Oct 23, 2019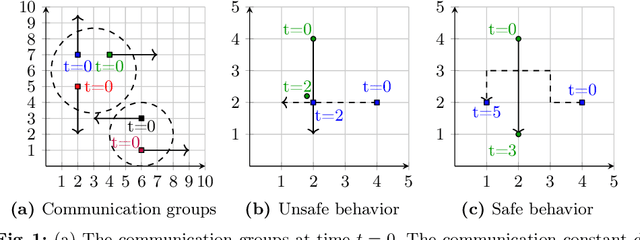
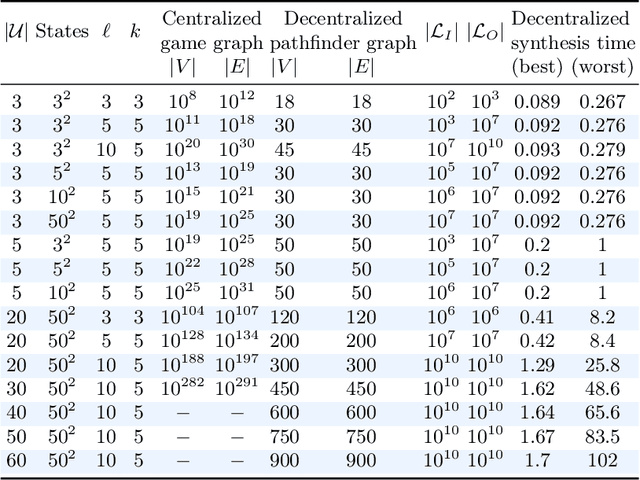
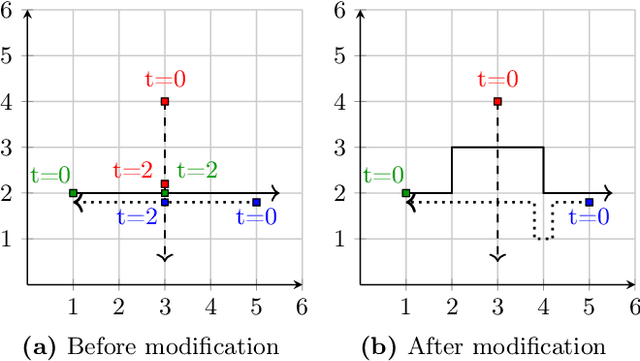
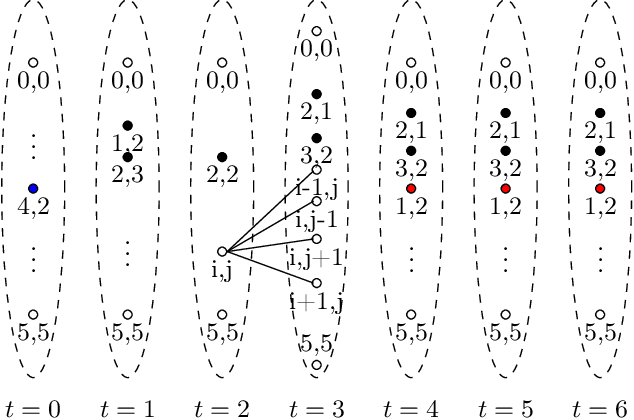
A shield is attached to a system to guarantee safety by correcting the system's behavior at runtime. Existing methods that employ design-time synthesis of shields do not scale to multi-agent systems. Moreover, such shields are typically implemented in a centralized manner, requiring global information on the state of all agents in the system. We address these limitations through a new approach where the shields are synthesized at runtime and do not require global information. There is a shield onboard every agent, which can only modify the behavior of the corresponding agent. In this approach, which is fundamentally decentralized, the shield on every agent has two components: a pathfinder that corrects the behavior of the agent and an ordering mechanism that dynamically modifies the priority of the agent. The current priority determines if the shield uses the pathfinder to modify behavior of the agent. We derive an upper bound on the maximum deviation for any agent from its original behavior. We prove that the worst-case synthesis time is quadratic in the number of agents at runtime as opposed to exponential at design-time for existing methods. We test the performance of the decentralized, runtime shield synthesis approach on a collision-avoidance problem. For 50 agents in a 50x50 grid, the synthesis at runtime requires a few seconds per agent whenever a potential collision is detected. In contrast, the centralized design-time synthesis of shields for a similar setting is intractable beyond 4 agents in a 5x5 grid.
Reward-Based Deception with Cognitive Bias
Apr 25, 2019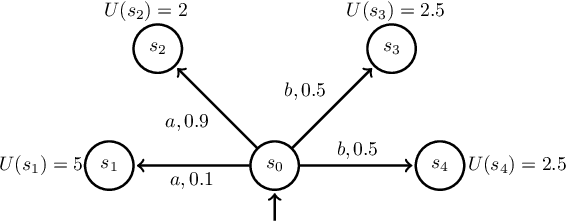

Deception plays a key role in adversarial or strategic interactions for the purpose of self-defence and survival. This paper introduces a general framework and solution to address deception. Most existing approaches for deception consider obfuscating crucial information to rational adversaries with abundant memory and computation resources. In this paper, we consider deceiving adversaries with bounded rationality and in terms of expected rewards. This problem is commonly encountered in many applications especially involving human adversaries. Leveraging the cognitive bias of humans in reward evaluation under stochastic outcomes, we introduce a framework to optimally assign resources of a limited quantity to optimally defend against human adversaries. Modeling such cognitive biases follows the so-called prospect theory from behavioral psychology literature. Then we formulate the resource allocation problem as a signomial program to minimize the defender's cost in an environment modeled as a Markov decision process. We use police patrol hour assignment as an illustrative example and provide detailed simulation results based on real-world data.
Distributed Synthesis of Surveillance Strategies for Mobile Sensors
Feb 06, 2019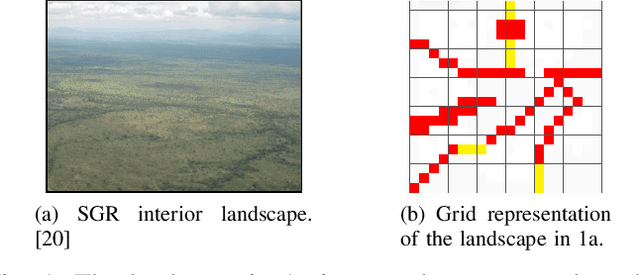


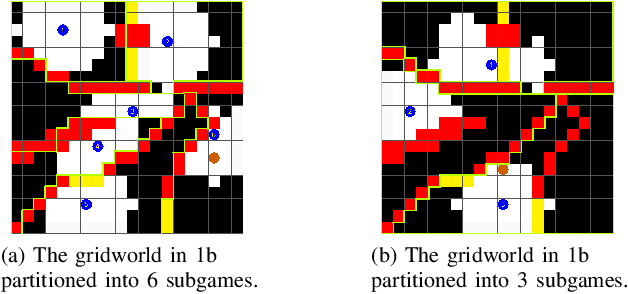
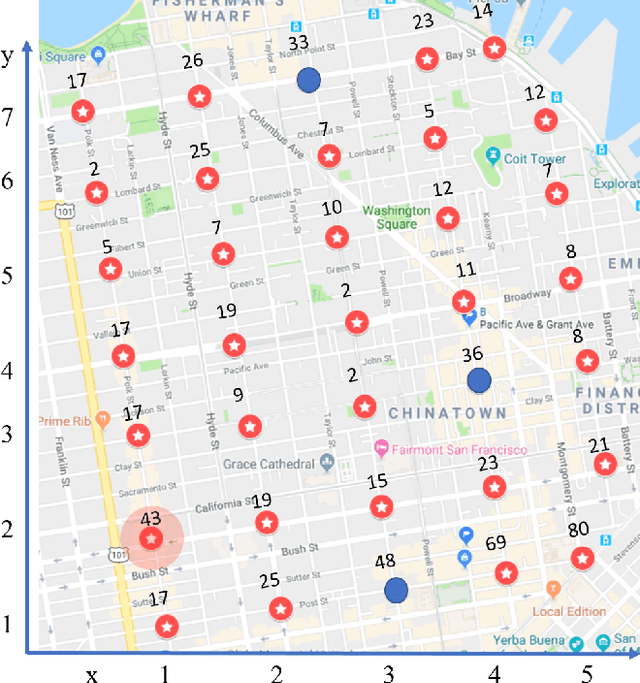
We study the problem of synthesizing strategies for a mobile sensor network to conduct surveillance in partnership with static alarm triggers. We formulate the problem as a multi-agent reactive synthesis problem with surveillance objectives specified as temporal logic formulas. In order to avoid the state space blow-up arising from a centralized strategy computation, we propose a method to decentralize the surveillance strategy synthesis by decomposing the multi-agent game into subgames that can be solved independently. We also decompose the global surveillance specification into local specifications for each sensor, and show that if the sensors satisfy their local surveillance specifications, then the sensor network as a whole will satisfy the global surveillance objective. Thus, our method is able to guarantee global surveillance properties in a mobile sensor network while synthesizing completely decentralized strategies with no need for coordination between the sensors. We also present a case study in which we demonstrate an application of decentralized surveillance strategy synthesis.
Synthesis of surveillance strategies via belief abstraction
Mar 19, 2018
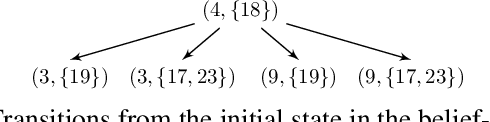
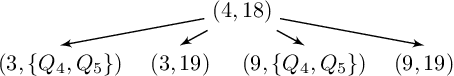

We study the problem of synthesizing a controller for a robot with a surveillance objective, that is, the robot is required to maintain knowledge of the location of a moving, possibly adversarial target. We formulate this problem as a one-sided partial-information game in which the winning condition for the agent is specified as a temporal logic formula. The specification formalizes the surveillance requirement given by the user, including additional non-surveillance tasks. In order to synthesize a surveillance strategy that meets the specification, we transform the partial-information game into a perfect-information one, using abstraction to mitigate the exponential blow-up typically incurred by such transformations. This enables the use of off-the-shelf tools for reactive synthesis. We use counterexample-guided refinement to automatically achieve abstraction precision that is sufficient to synthesize a surveillance strategy. We evaluate the proposed method on two case-studies, demonstrating its applicability to large state-spaces and diverse requirements.