 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Limits and Efficient Algorithms for Differentially Private Federated Learning
May 18, 2026Federated Learning is a leading framework for training ML and AI models collaboratively across numerous user devices or databases. We study the trade-offs among estimation accuracy, privacy constraints, and communication cost for differentially private (DP) federated M estimation. The two standard methods in the literature are FedAvg, which may suffer from high federation bias, and FedSGD, which can incur high communication cost. Aimed at improving accuracy at a reduced communication cost, we propose FedHybrid, which uses FedSGD starting with an improved initialization by the FedAvg estimator. We propose FedNewton, which averages local Newton iterations to reduce bias in FedAvg, achieving an estimation accuracy comparable to FedSGD with much fewer communication rounds when the number of clients grows sufficiently slowly. We establish finite sample upper bounds on the mean-squared error rates of the DP versions of these estimators as functions of the number of clients, local sample sizes, privacy budget, and number of iterations. We further derive a minimax lower bound on the MSE of any iterative private federated procedure that provides a benchmark to assess the optimality gap of these methods. We numerically evaluate our methods for training a logistic regression and a neural network on the computer vision datasets MNIST and CIFAR-10.
Spectral clustering for dependent community Hawkes process models of temporal networks
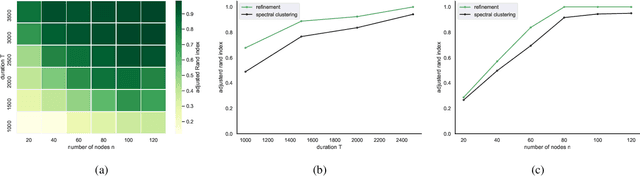
May 28, 2025Temporal networks observed continuously over time through timestamped relational events data are commonly encountered in application settings including online social media communications, financial transactions, and international relations. Temporal networks often exhibit community structure and strong dependence patterns among node pairs. This dependence can be modeled through mutual excitations, where an interaction event from a sender to a receiver node increases the possibility of future events among other node pairs. We provide statistical results for a class of models that we call dependent community Hawkes (DCH) models, which combine the stochastic block model with mutually exciting Hawkes processes for modeling both community structure and dependence among node pairs, respectively. We derive a non-asymptotic upper bound on the misclustering error of spectral clustering on the event count matrix as a function of the number of nodes and communities, time duration, and the amount of dependence in the model. Our result leverages recent results on bounding an appropriate distance between a multivariate Hawkes process count vector and a Gaussian vector, along with results from random matrix theory. We also propose a DCH model that incorporates only self and reciprocal excitation along with highly scalable parameter estimation using a Generalized Method of Moments (GMM) estimator that we demonstrate to be consistent for growing network size and time duration.
Heterogeneous transfer learning for high dimensional regression with feature mismatch
Dec 24, 2024We consider the problem of transferring knowledge from a source, or proxy, domain to a new target domain for learning a high-dimensional regression model with possibly different features. Recently, the statistical properties of homogeneous transfer learning have been investigated. However, most homogeneous transfer and multi-task learning methods assume that the target and proxy domains have the same feature space, limiting their practical applicability. In applications, target and proxy feature spaces are frequently inherently different, for example, due to the inability to measure some variables in the target data-poor environments. Conversely, existing heterogeneous transfer learning methods do not provide statistical error guarantees, limiting their utility for scientific discovery. We propose a two-stage method that involves learning the relationship between the missing and observed features through a projection step in the proxy data and then solving a joint penalized regression optimization problem in the target data. We develop an upper bound on the method's parameter estimation risk and prediction risk, assuming that the proxy and the target domain parameters are sparsely different. Our results elucidate how estimation and prediction error depend on the complexity of the model, sample size, the extent of overlap, and correlation between matched and mismatched features.
The co-varying ties between networks and item responses via latent variables
Sep 28, 2024



Relationships among teachers are known to influence their teaching-related perceptions. We study whether and how teachers' advising relationships (networks) are related to their perceptions of satisfaction, students, and influence over educational policies, recorded as their responses to a questionnaire (item responses). We propose a novel joint model of network and item responses (JNIRM) with correlated latent variables to understand these co-varying ties. This methodology allows the analyst to test and interpret the dependence between a network and item responses. Using JNIRM, we discover that teachers' advising relationships contribute to their perceptions of satisfaction and students more often than their perceptions of influence over educational policies. In addition, we observe that the complementarity principle applies in certain schools, where teachers tend to seek advice from those who are different from them. JNIRM shows superior parameter estimation and model fit over separately modeling the network and item responses with latent variable models.
VLSI Architectures of Forward Kinematic Processor for Robotics Applications
Mar 07, 2024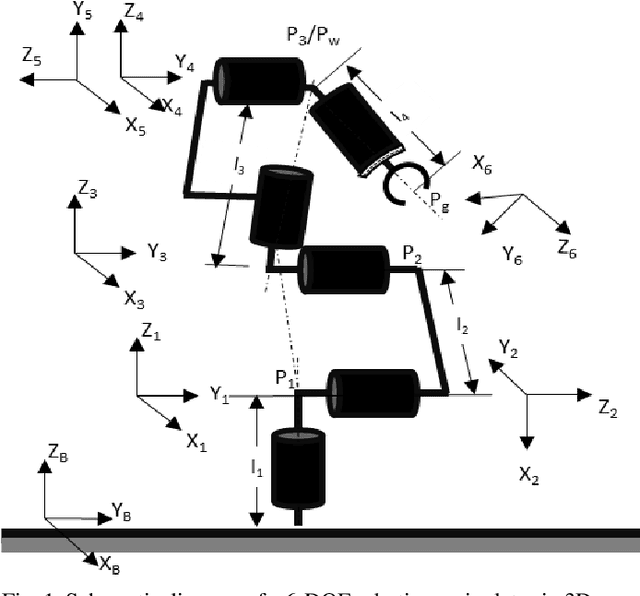
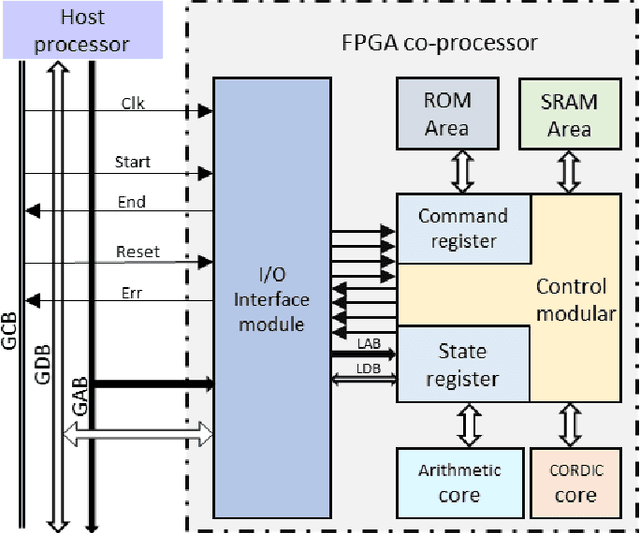
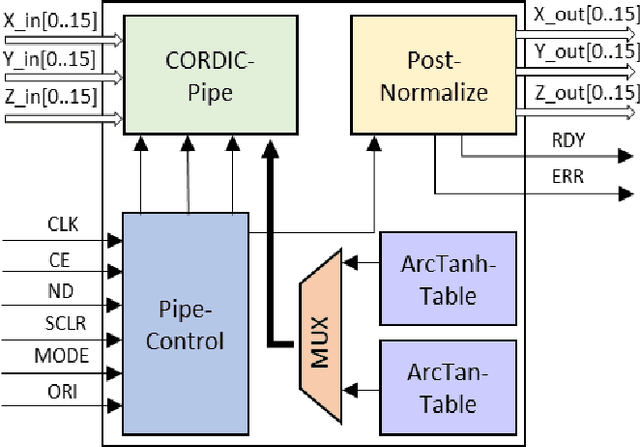
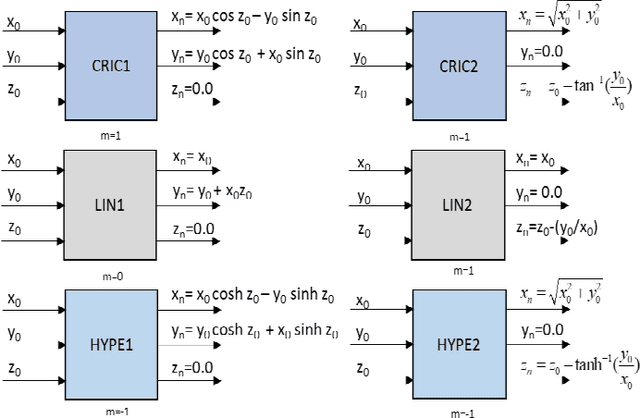
This paper aims to get a comprehensive review of current-day robotic computation technologies at VLSI architecture level. We studied several repots in the domain of robotic processor architecture. In this work, we focused on the forward kinematics architectures which consider CORDIC algorithms, VLSI circuits of WE DSP16 chip, parallel processing and pipelined architecture, and lookup table formula and FPGA processor. This study gives us an understanding of different implementation methods for forward kinematics. Our goal is to develop a forward kinematics processor with FPGA for real-time applications, requires a fast response time and low latency of these devices, useful for industrial automation where the processing speed plays a great role.
A Mutually Exciting Latent Space Hawkes Process Model for Continuous-time Networks
May 19, 2022
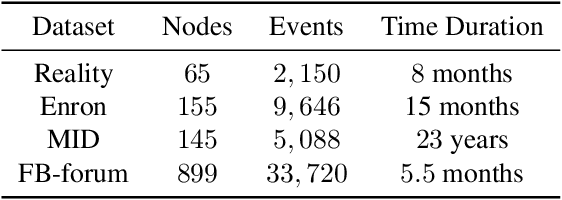
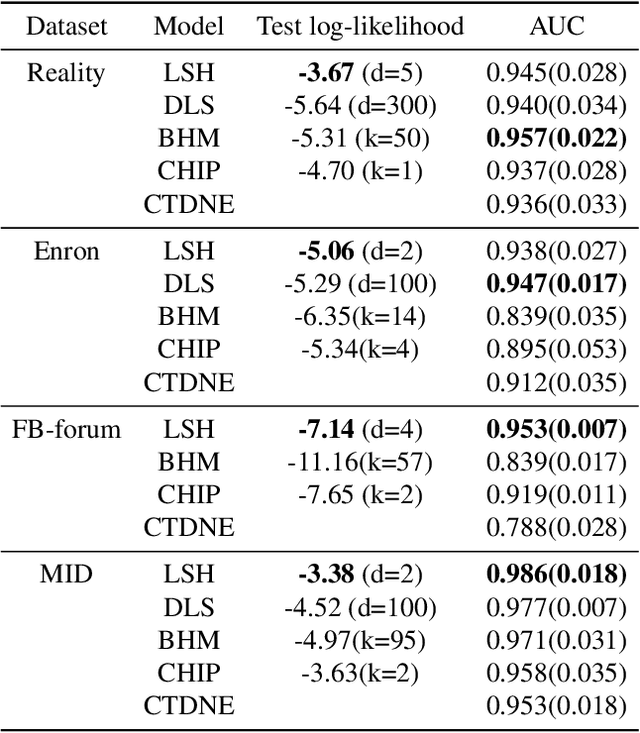
Networks and temporal point processes serve as fundamental building blocks for modeling complex dynamic relational data in various domains. We propose the latent space Hawkes (LSH) model, a novel generative model for continuous-time networks of relational events, using a latent space representation for nodes. We model relational events between nodes using mutually exciting Hawkes processes with baseline intensities dependent upon the distances between the nodes in the latent space and sender and receiver specific effects. We propose an alternating minimization algorithm to jointly estimate the latent positions of the nodes and other model parameters. We demonstrate that our proposed LSH model can replicate many features observed in real temporal networks including reciprocity and transitivity, while also achieves superior prediction accuracy and provides more interpretability compared to existing models.
The Multivariate Community Hawkes Model for Dependent Relational Events in Continuous-time Networks
May 02, 2022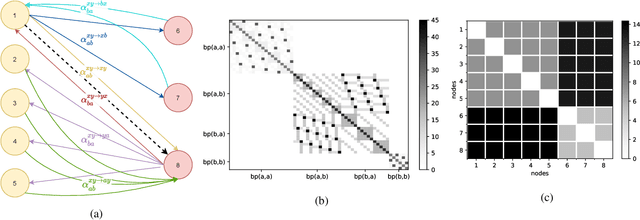


The stochastic block model (SBM) is one of the most widely used generative models for network data. Many continuous-time dynamic network models are built upon the same assumption as the SBM: edges or events between all pairs of nodes are conditionally independent given the block or community memberships, which prevents them from reproducing higher-order motifs such as triangles that are commonly observed in real networks. We propose the multivariate community Hawkes (MULCH) model, an extremely flexible community-based model for continuous-time networks that introduces dependence between node pairs using structured multivariate Hawkes processes. We fit the model using a spectral clustering and likelihood-based local refinement procedure. We find that our proposed MULCH model is far more accurate than existing models both for predictive and generative tasks.
Causal Network Influence with Latent Homophily and Measurement Error: An Application to Therapeutic Community
Mar 27, 2022

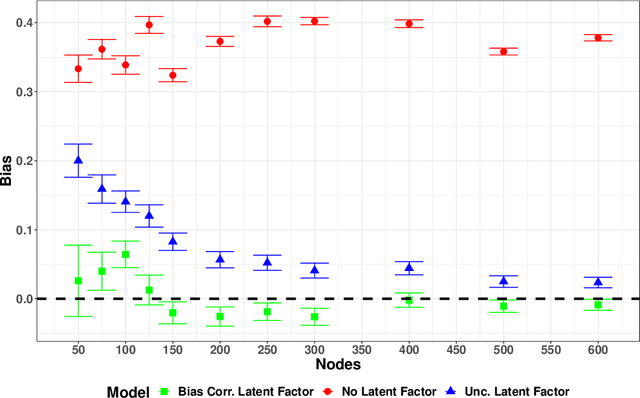

The Spatial or Network Autoregressive model (SAR, NAM) is popular for modeling the influence network connected neighbors exert on the outcome of individuals. However, many authors have noted that the \textit{causal} network influence or contagion cannot be identified from observational data due to the presence of homophily. We propose a latent homophily-adjusted spatial autoregressive model for networked responses to identify the causal contagion and contextual effects. The latent homophily is estimated from the spectral embedding of the network's adjacency matrix. Separately, we develop maximum likelihood estimators for the parameters of the SAR model correcting for measurement error when covariates are measured with error. We show that the bias corrected MLE are consistent and derive its asymptotic limiting distribution. We propose to estimate network influence using the bias corrected MLE in a SAR model with the estimated latent homophily added as a covariate. Our simulations show that the methods perform well in finite sample. We apply our methodology to a data-set of female criminal offenders in a therapeutic community (TC) for substance abuse and criminal behavior. We provide causal estimates of network influence on graduation from TC and re-incarceration after accounting for latent homophily.
Consistent Community Detection in Continuous-Time Networks of Relational Events
Aug 19, 2019

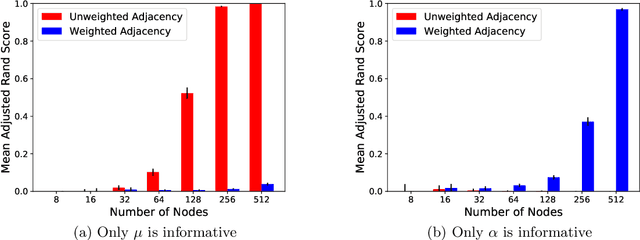

In many application settings involving networks, such as messages between users of an on-line social network or transactions between traders in financial markets, the observed data are in the form of relational events with timestamps, which form a continuous-time network. We propose the Community Hawkes Independent Pairs (CHIP) model for community detection on such timestamped relational event data. We demonstrate that applying spectral clustering to adjacency matrices constructed from relational events generated by the CHIP model provides consistent community detection for a growing number of nodes. In particular, we obtain explicit non-asymptotic upper bounds on the misclustering rates based on the separation conditions required on the parameters of the model for consistent community detection. We also develop consistent and computationally efficient estimators for the parameters of the model. We demonstrate that our proposed CHIP model and estimation procedure scales to large networks with tens of thousands of nodes and provides superior fits compared to existing continuous-time network models on several real networks.
Higher-Order Spectral Clustering under Superimposed Stochastic Block Model
Dec 16, 2018



Higher-order motif structures and multi-vertex interactions are becoming increasingly important in studies that aim to improve our understanding of functionalities and evolution patterns of networks. To elucidate the role of higher-order structures in community detection problems over complex networks, we introduce the notion of a Superimposed Stochastic Block Model (SupSBM). The model is based on a random graph framework in which certain higher-order structures or subgraphs are generated through an independent hyperedge generation process, and are then replaced with graphs that are superimposed with directed or undirected edges generated by an inhomogeneous random graph model. Consequently, the model introduces controlled dependencies between edges which allow for capturing more realistic network phenomena, namely strong local clustering in a sparse network, short average path length, and community structure. We proceed to rigorously analyze the performance of a number of recently proposed higher-order spectral clustering methods on the SupSBM. In particular, we prove non-asymptotic upper bounds on the misclustering error of spectral community detection for a SupSBM setting in which triangles or 3-uniform hyperedges are superimposed with undirected edges. As part of our analysis, we also derive new bounds on the misclustering error of higher-order spectral clustering methods for the standard SBM and the 3-uniform hypergraph SBM. Furthermore, for a non-uniform hypergraph SBM model in which one directly observes both edges and 3-uniform hyperedges, we obtain a criterion that describes when to perform spectral clustering based on edges and when on hyperedges, based on a function of hyperedge density and observation quality.