 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Improving Sample Efficiency and Multi-Agent Communication in RL-based Train Rescheduling
Apr 28, 2020
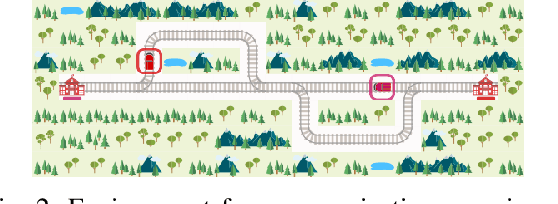
We present preliminary results from our sixth placed entry to the Flatland international competition for train rescheduling, including two improvements for optimized reinforcement learning (RL) training efficiency, and two hypotheses with respect to the prospect of deep RL for complex real-world control tasks: first, that current state of the art policy gradient methods seem inappropriate in the domain of high-consequence environments; second, that learning explicit communication actions (an emerging machine-to-machine language, so to speak) might offer a remedy. These hypotheses need to be confirmed by future work. If confirmed, they hold promises with respect to optimizing highly efficient logistics ecosystems like the Swiss Federal Railways railway network.