 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Sample Efficiency and Multi-Agent Communication in RL-based Train Rescheduling
Paper and Code
Apr 28, 2020
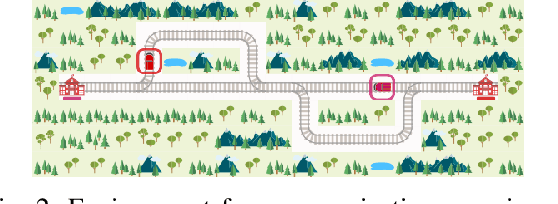
We present preliminary results from our sixth placed entry to the Flatland international competition for train rescheduling, including two improvements for optimized reinforcement learning (RL) training efficiency, and two hypotheses with respect to the prospect of deep RL for complex real-world control tasks: first, that current state of the art policy gradient methods seem inappropriate in the domain of high-consequence environments; second, that learning explicit communication actions (an emerging machine-to-machine language, so to speak) might offer a remedy. These hypotheses need to be confirmed by future work. If confirmed, they hold promises with respect to optimizing highly efficient logistics ecosystems like the Swiss Federal Railways railway network.