 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeMeshGPT: Artistic Mesh Generation with Autoregressive Tree Sequencing
Mar 14, 2025



We introduce TreeMeshGPT, an autoregressive Transformer designed to generate high-quality artistic meshes aligned with input point clouds. Instead of the conventional next-token prediction in autoregressive Transformer, we propose a novel Autoregressive Tree Sequencing where the next input token is retrieved from a dynamically growing tree structure that is built upon the triangle adjacency of faces within the mesh. Our sequencing enables the mesh to extend locally from the last generated triangular face at each step, and therefore reduces training difficulty and improves mesh quality. Our approach represents each triangular face with two tokens, achieving a compression rate of approximately 22% compared to the naive face tokenization. This efficient tokenization enables our model to generate highly detailed artistic meshes with strong point cloud conditioning, surpassing previous methods in both capacity and fidelity. Furthermore, our method generates mesh with strong normal orientation constraints, minimizing flipped normals commonly encountered in previous methods. Our experiments show that TreeMeshGPT enhances the mesh generation quality with refined details and normal orientation consistency.
NU-MCC: Multiview Compressive Coding with Neighborhood Decoder and Repulsive UDF
Jul 18, 2023Remarkable progress has been made in 3D reconstruction from single-view RGB-D inputs. MCC is the current state-of-the-art method in this field, which achieves unprecedented success by combining vision Transformers with large-scale training. However, we identified two key limitations of MCC: 1) The Transformer decoder is inefficient in handling large number of query points; 2) The 3D representation struggles to recover high-fidelity details. In this paper, we propose a new approach called NU-MCC that addresses these limitations. NU-MCC includes two key innovations: a Neighborhood decoder and a Repulsive Unsigned Distance Function (Repulsive UDF). First, our Neighborhood decoder introduces center points as an efficient proxy of input visual features, allowing each query point to only attend to a small neighborhood. This design not only results in much faster inference speed but also enables the exploitation of finer-scale visual features for improved recovery of 3D textures. Second, our Repulsive UDF is a novel alternative to the occupancy field used in MCC, significantly improving the quality of 3D object reconstruction. Compared to standard UDFs that suffer from holes in results, our proposed Repulsive UDF can achieve more complete surface reconstruction. Experimental results demonstrate that NU-MCC is able to learn a strong 3D representation, significantly advancing the state of the art in single-view 3D reconstruction. Particularly, it outperforms MCC by 9.7% in terms of the F1-score on the CO3D-v2 dataset with more than 5x faster running speed.
NeuralBlox: Real-Time Neural Representation Fusion for Robust Volumetric Mapping
Oct 18, 2021



We present a novel 3D mapping method leveraging the recent progress in neural implicit representation for 3D reconstruction. Most existing state-of-the-art neural implicit representation methods are limited to object-level reconstructions and can not incrementally perform updates given new data. In this work, we propose a fusion strategy and training pipeline to incrementally build and update neural implicit representations that enable the reconstruction of large scenes from sequential partial observations. By representing an arbitrarily sized scene as a grid of latent codes and performing updates directly in latent space, we show that incrementally built occupancy maps can be obtained in real-time even on a CPU. Compared to traditional approaches such as Truncated Signed Distance Fields (TSDFs), our map representation is significantly more robust in yielding a better scene completeness given noisy inputs. We demonstrate the performance of our approach in thorough experimental validation on real-world datasets with varying degrees of added pose noise.
Dynamic Plane Convolutional Occupancy Networks
Nov 11, 2020
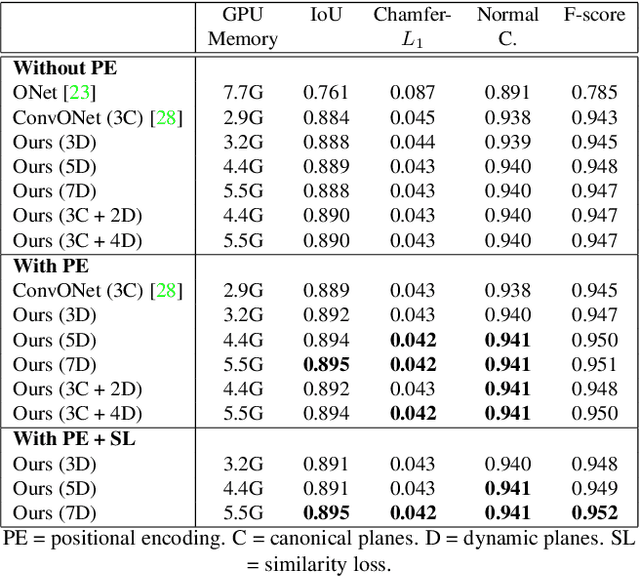
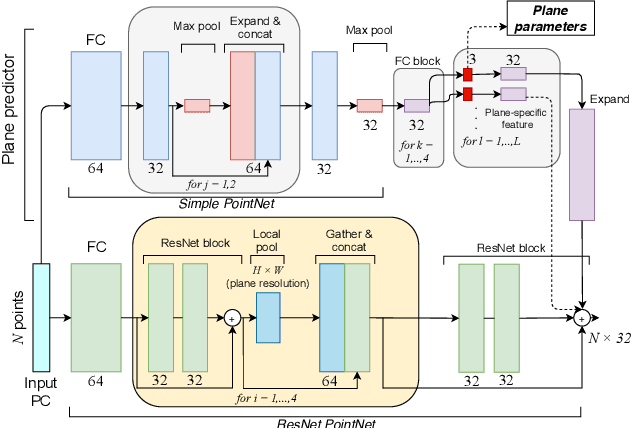
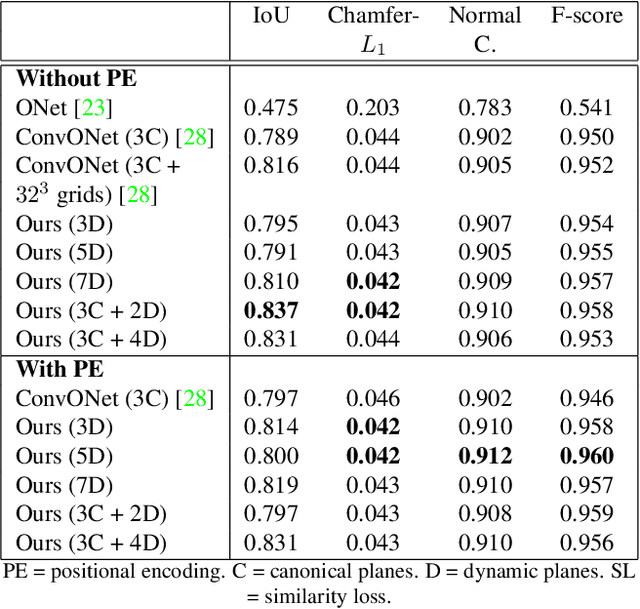
Learning-based 3D reconstruction using implicit neural representations has shown promising progress not only at the object level but also in more complicated scenes. In this paper, we propose Dynamic Plane Convolutional Occupancy Networks, a novel implicit representation pushing further the quality of 3D surface reconstruction. The input noisy point clouds are encoded into per-point features that are projected onto multiple 2D dynamic planes. A fully-connected network learns to predict plane parameters that best describe the shapes of objects or scenes. To further exploit translational equivariance, convolutional neural networks are applied to process the plane features. Our method shows superior performance in surface reconstruction from unoriented point clouds in ShapeNet as well as an indoor scene dataset. Moreover, we also provide interesting observations on the distribution of learned dynamic planes.