 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Model Collapse Under Overparametrization: Optimal Mixing Ratios for Interpolation Learning and Ridge Regression
Sep 26, 2025Model collapse occurs when generative models degrade after repeatedly training on their own synthetic outputs. We study this effect in overparameterized linear regression in a setting where each iteration mixes fresh real labels with synthetic labels drawn from the model fitted in the previous iteration. We derive precise generalization error formulae for minimum-$\ell_2$-norm interpolation and ridge regression under this iterative scheme. Our analysis reveals intriguing properties of the optimal mixing weight that minimizes long-term prediction error and provably prevents model collapse. For instance, in the case of min-$\ell_2$-norm interpolation, we establish that the optimal real-data proportion converges to the reciprocal of the golden ratio for fairly general classes of covariate distributions. Previously, this property was known only for ordinary least squares, and additionally in low dimensions. For ridge regression, we further analyze two popular model classes -- the random-effects model and the spiked covariance model -- demonstrating how spectral geometry governs optimal weighting. In both cases, as well as for isotropic features, we uncover that the optimal mixing ratio should be at least one-half, reflecting the necessity of favoring real-data over synthetic. We validate our theoretical results with extensive simulations.
Late Fusion Multi-task Learning for Semiparametric Inference with Nuisance Parameters
Jul 10, 2025In the age of large and heterogeneous datasets, the integration of information from diverse sources is essential to improve parameter estimation. Multi-task learning offers a powerful approach by enabling simultaneous learning across related tasks. In this work, we introduce a late fusion framework for multi-task learning with semiparametric models that involve infinite-dimensional nuisance parameters, focusing on applications such as heterogeneous treatment effect estimation across multiple data sources, including electronic health records from different hospitals or clinical trial data. Our framework is two-step: first, initial double machine-learning estimators are obtained through individual task learning; second, these estimators are adaptively aggregated to exploit task similarities while remaining robust to task-specific differences. In particular, the framework avoids individual level data sharing, preserving privacy. Additionally, we propose a novel multi-task learning method for nuisance parameter estimation, which further enhances parameter estimation when nuisance parameters exhibit similarity across tasks. We establish theoretical guarantees for the method, demonstrating faster convergence rates compared to individual task learning when tasks share similar parametric components. Extensive simulations and real data applications complement the theoretical findings of our work while highlight the effectiveness of our framework even in moderate sample sizes.
Generalization error of min-norm interpolators in transfer learning
Jun 20, 2024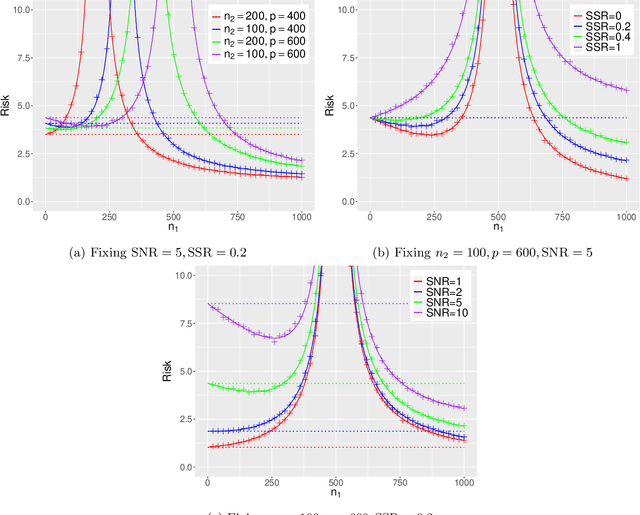
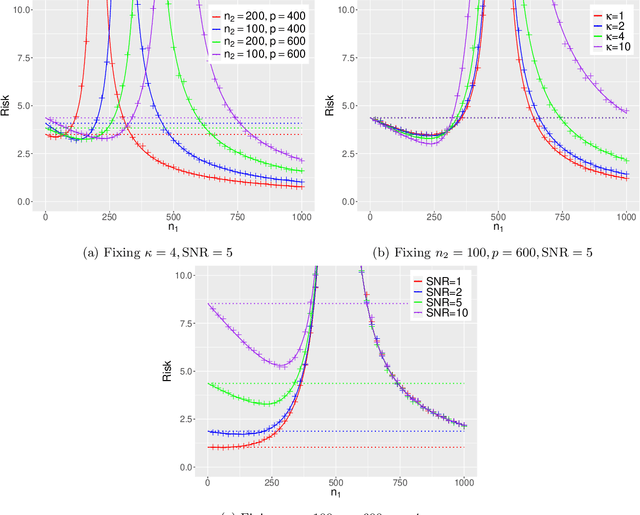
This paper establishes the generalization error of pooled min-$\ell_2$-norm interpolation in transfer learning where data from diverse distributions are available. Min-norm interpolators emerge naturally as implicit regularized limits of modern machine learning algorithms. Previous work characterized their out-of-distribution risk when samples from the test distribution are unavailable during training. However, in many applications, a limited amount of test data may be available during training, yet properties of min-norm interpolation in this setting are not well-understood. We address this gap by characterizing the bias and variance of pooled min-$\ell_2$-norm interpolation under covariate and model shifts. The pooled interpolator captures both early fusion and a form of intermediate fusion. Our results have several implications: under model shift, for low signal-to-noise ratio (SNR), adding data always hurts. For higher SNR, transfer learning helps as long as the shift-to-signal (SSR) ratio lies below a threshold that we characterize explicitly. By consistently estimating these ratios, we provide a data-driven method to determine: (i) when the pooled interpolator outperforms the target-based interpolator, and (ii) the optimal number of target samples that minimizes the generalization error. Under covariate shift, if the source sample size is small relative to the dimension, heterogeneity between between domains improves the risk, and vice versa. We establish a novel anisotropic local law to achieve these characterizations, which may be of independent interest in random matrix theory. We supplement our theoretical characterizations with comprehensive simulations that demonstrate the finite-sample efficacy of our results.
Faster Rates for Switchback Experiments
Dec 25, 2023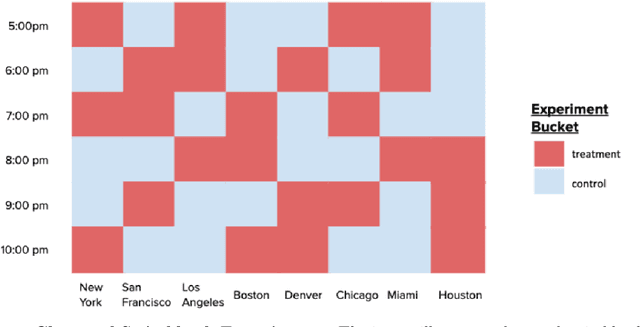

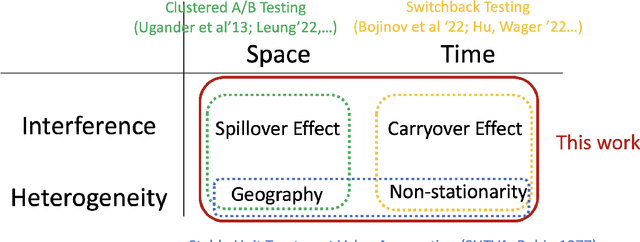
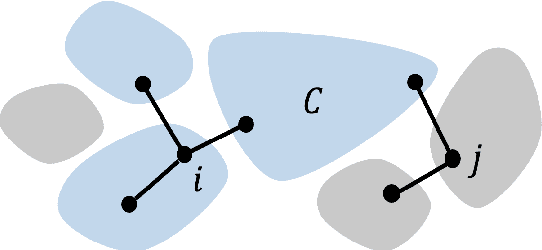
Switchback experimental design, wherein a single unit (e.g., a whole system) is exposed to a single random treatment for interspersed blocks of time, tackles both cross-unit and temporal interference. Hu and Wager (2022) recently proposed a treatment-effect estimator that truncates the beginnings of blocks and established a $T^{-1/3}$ rate for estimating the global average treatment effect (GATE) in a Markov setting with rapid mixing. They claim this rate is optimal and suggest focusing instead on a different (and design-dependent) estimand so as to enjoy a faster rate. For the same design we propose an alternative estimator that uses the whole block and surprisingly show that it in fact achieves an estimation rate of $\sqrt{\log T/T}$ for the original design-independent GATE estimand under the same assumptions.
Inferences on Mixing Probabilities and Ranking in Mixed-Membership Models
Aug 29, 2023Network data is prevalent in numerous big data applications including economics and health networks where it is of prime importance to understand the latent structure of network. In this paper, we model the network using the Degree-Corrected Mixed Membership (DCMM) model. In DCMM model, for each node $i$, there exists a membership vector $\boldsymbol{\pi}_ i = (\boldsymbol{\pi}_i(1), \boldsymbol{\pi}_i(2),\ldots, \boldsymbol{\pi}_i(K))$, where $\boldsymbol{\pi}_i(k)$ denotes the weight that node $i$ puts in community $k$. We derive novel finite-sample expansion for the $\boldsymbol{\pi}_i(k)$s which allows us to obtain asymptotic distributions and confidence interval of the membership mixing probabilities and other related population quantities. This fills an important gap on uncertainty quantification on the membership profile. We further develop a ranking scheme of the vertices based on the membership mixing probabilities on certain communities and perform relevant statistical inferences. A multiplier bootstrap method is proposed for ranking inference of individual member's profile with respect to a given community. The validity of our theoretical results is further demonstrated by via numerical experiments in both real and synthetic data examples.
Deep Neural Networks for Nonparametric Interaction Models with Diverging Dimension
Feb 12, 2023Deep neural networks have achieved tremendous success due to their representation power and adaptation to low-dimensional structures. Their potential for estimating structured regression functions has been recently established in the literature. However, most of the studies require the input dimension to be fixed and consequently ignore the effect of dimension on the rate of convergence and hamper their applications to modern big data with high dimensionality. In this paper, we bridge this gap by analyzing a $k^{th}$ order nonparametric interaction model in both growing dimension scenarios ($d$ grows with $n$ but at a slower rate) and in high dimension ($d \gtrsim n$). In the latter case, sparsity assumptions and associated regularization are required in order to obtain optimal rates of convergence. A new challenge in diverging dimension setting is in calculation mean-square error, the covariance terms among estimated additive components are an order of magnitude larger than those of the variances and they can deteriorate statistical properties without proper care. We introduce a critical debiasing technique to amend the problem. We show that under certain standard assumptions, debiased deep neural networks achieve a minimax optimal rate both in terms of $(n, d)$. Our proof techniques rely crucially on a novel debiasing technique that makes the covariances of additive components negligible in the mean-square error calculation. In addition, we establish the matching lower bounds.