 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization error of min-norm interpolators in transfer learning
Paper and Code
Jun 20, 2024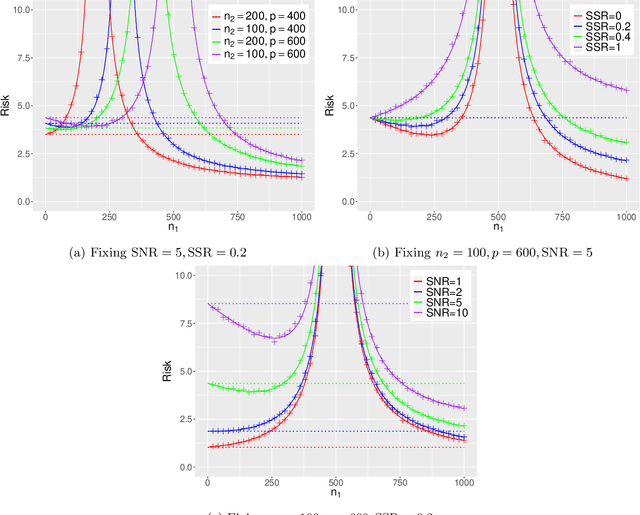
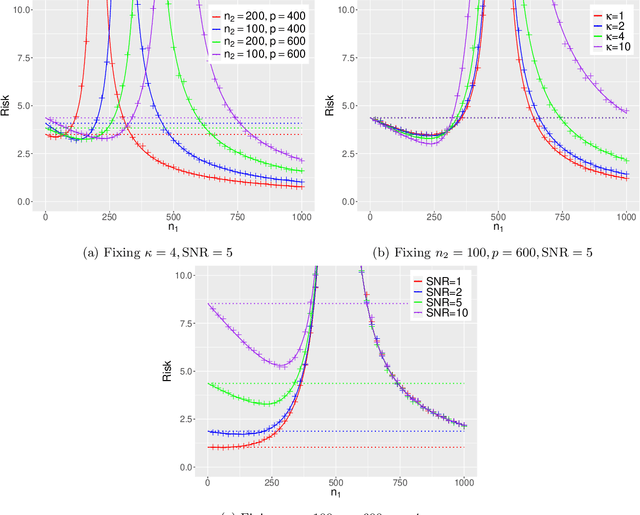
This paper establishes the generalization error of pooled min-$\ell_2$-norm interpolation in transfer learning where data from diverse distributions are available. Min-norm interpolators emerge naturally as implicit regularized limits of modern machine learning algorithms. Previous work characterized their out-of-distribution risk when samples from the test distribution are unavailable during training. However, in many applications, a limited amount of test data may be available during training, yet properties of min-norm interpolation in this setting are not well-understood. We address this gap by characterizing the bias and variance of pooled min-$\ell_2$-norm interpolation under covariate and model shifts. The pooled interpolator captures both early fusion and a form of intermediate fusion. Our results have several implications: under model shift, for low signal-to-noise ratio (SNR), adding data always hurts. For higher SNR, transfer learning helps as long as the shift-to-signal (SSR) ratio lies below a threshold that we characterize explicitly. By consistently estimating these ratios, we provide a data-driven method to determine: (i) when the pooled interpolator outperforms the target-based interpolator, and (ii) the optimal number of target samples that minimizes the generalization error. Under covariate shift, if the source sample size is small relative to the dimension, heterogeneity between between domains improves the risk, and vice versa. We establish a novel anisotropic local law to achieve these characterizations, which may be of independent interest in random matrix theory. We supplement our theoretical characterizations with comprehensive simulations that demonstrate the finite-sample efficacy of our results.