 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWatch from sky: machine-learning-based multi-UAV network for predictive police surveillance
Mar 06, 2022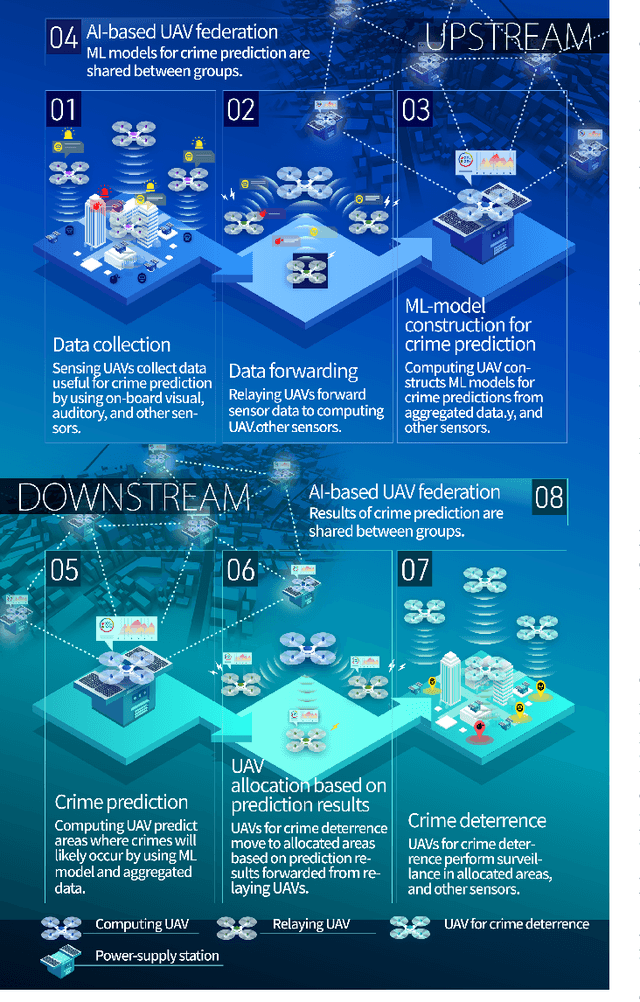
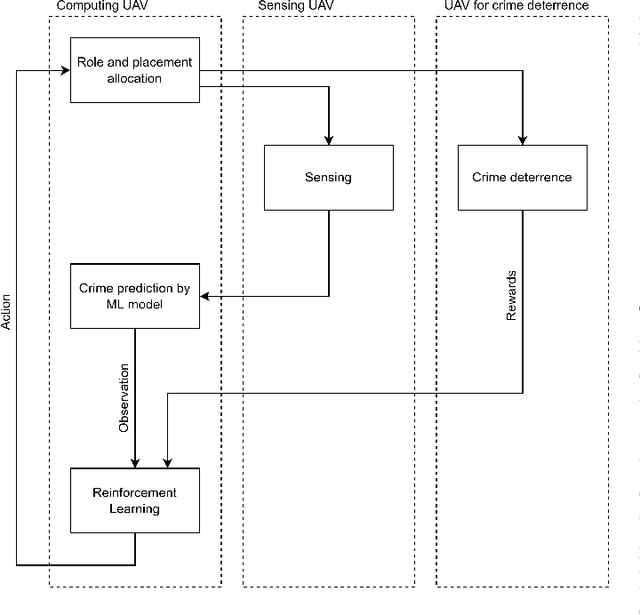
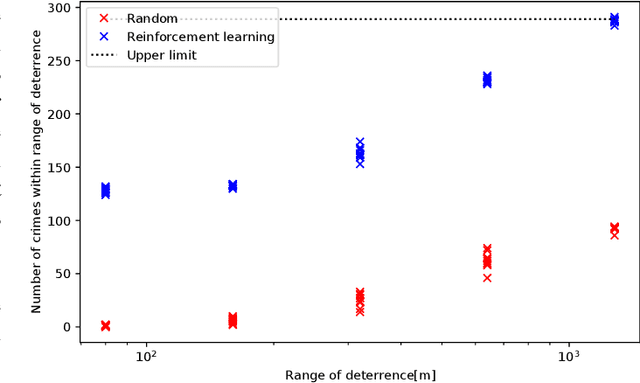
This paper presents the watch-from-sky framework, where multiple unmanned aerial vehicles (UAVs) play four roles, i.e., sensing, data forwarding, computing, and patrolling, for predictive police surveillance. Our framework is promising for crime deterrence because UAVs are useful for collecting and distributing data and have high mobility. Our framework relies on machine learning (ML) technology for controlling and dispatching UAVs and predicting crimes. This paper compares the conceptual model of our framework against the literature. It also reports a simulation of UAV dispatching using reinforcement learning and distributed ML inference over a lossy UAV network.
Communication-oriented Model Fine-tuning for Packet-loss Resilient Distributed Inference under Highly Lossy IoT Networks
Dec 17, 2021
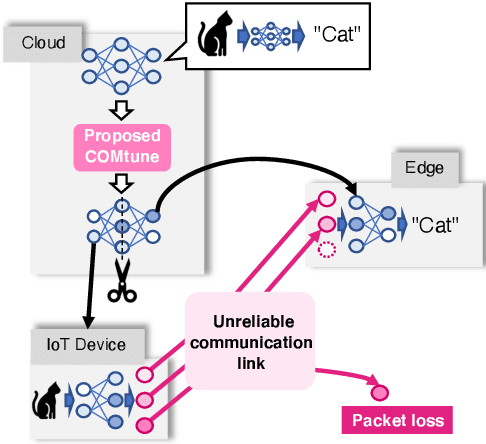
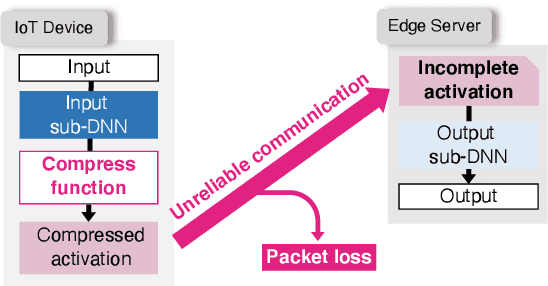
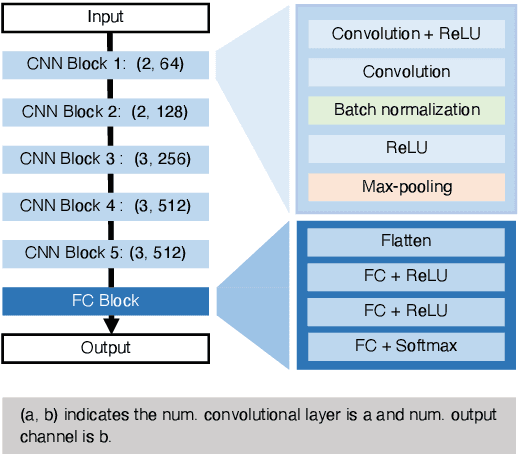
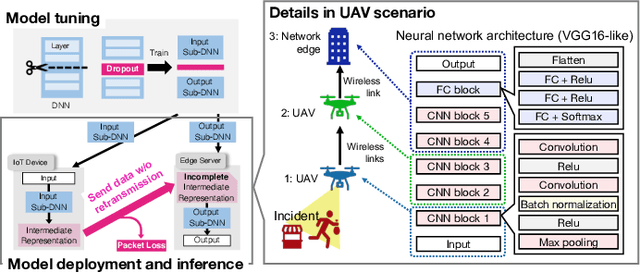
The distributed inference (DI) framework has gained traction as a technique for real-time applications empowered by cutting-edge deep machine learning (ML) on resource-constrained Internet of things (IoT) devices. In DI, computational tasks are offloaded from the IoT device to the edge server via lossy IoT networks. However, generally, there is a communication system-level trade-off between communication latency and reliability; thus, to provide accurate DI results, a reliable and high-latency communication system is required to be adapted, which results in non-negligible end-to-end latency of the DI. This motivated us to improve the trade-off between the communication latency and accuracy by efforts on ML techniques. Specifically, we have proposed a communication-oriented model tuning (COMtune), which aims to achieve highly accurate DI with low-latency but unreliable communication links. In COMtune, the key idea is to fine-tune the ML model by emulating the effect of unreliable communication links through the application of the dropout technique. This enables the DI system to obtain robustness against unreliable communication links. Our ML experiments revealed that COMtune enables accurate predictions with low latency and under lossy networks.
Frame-Capture-Based CSI Recomposition Pertaining to Firmware-Agnostic WiFi Sensing
Oct 29, 2021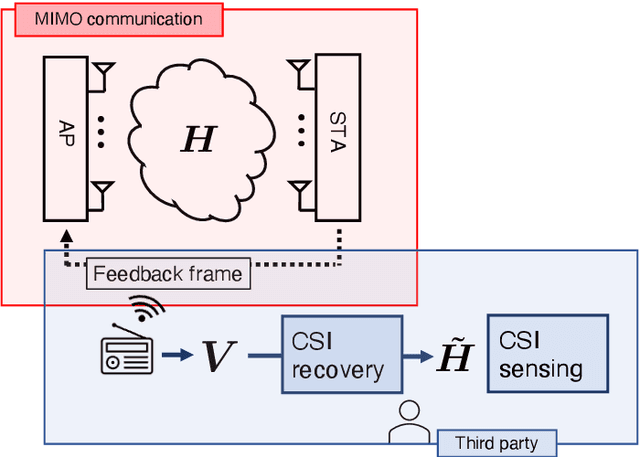
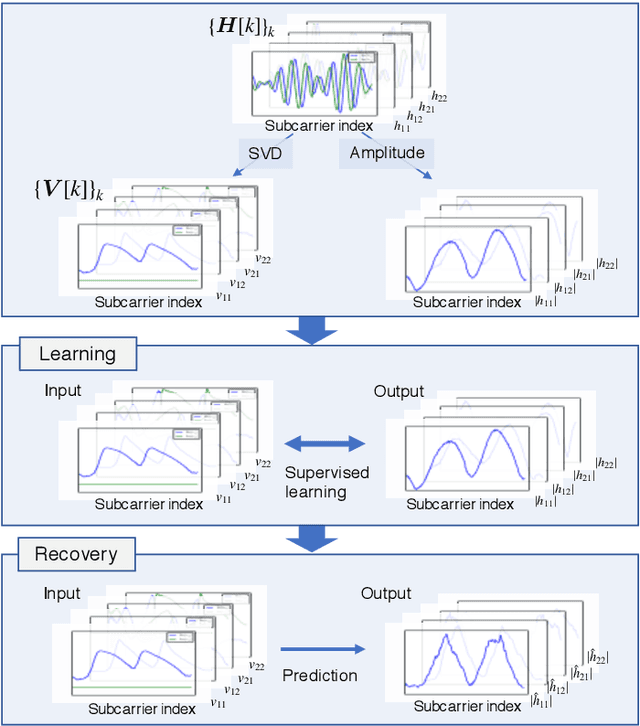
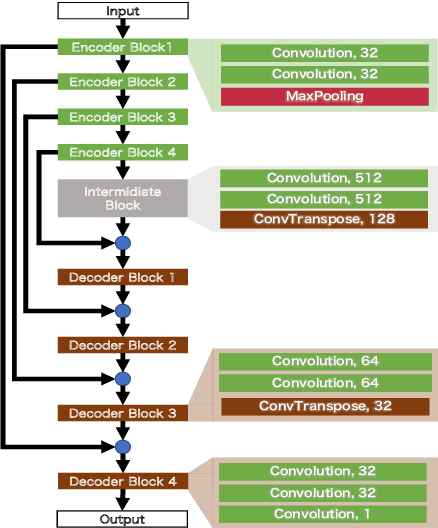
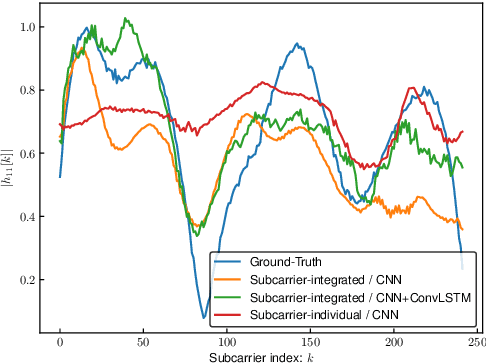
With regard to the implementation of WiFi sensing agnostic according to the availability of channel state information (CSI), we investigate the possibility of estimating a CSI matrix based on its compressed version, which is known as beamforming feedback matrix (BFM). Being different from the CSI matrix that is processed and discarded in physical layer components, the BFM can be captured using a medium-access-layer frame-capturing technique because this is exchanged among an access point (AP) and stations (STAs) over the air. This indicates that WiFi sensing that leverages the BFM matrix is more practical to implement using the pre-installed APs. However, the ability of BFM-based sensing has been evaluated in a few tasks, and more general insights into its performance should be provided. To fill this gap, we propose a CSI estimation method based on BFM, approximating the estimation function with a machine learning model. In addition, to improve the estimation accuracy, we leverage the inter-subcarrier dependency using the BFMs at multiple subcarriers in orthogonal frequency division multiplexing transmissions. Our simulation evaluation reveals that the estimated CSI matches the ground-truth amplitude. Moreover, compared to CSI estimation at each individual subcarrier, the effect of the BFMs at multiple subcarriers on the CSI estimation accuracy is validated.
Beamforming Feedback-based Model-driven Angle of Departure Estimation Toward Firmware-Agnostic WiFi Sensing
Oct 27, 2021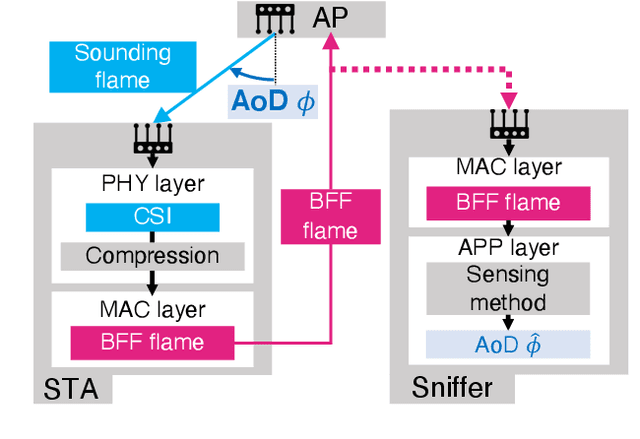
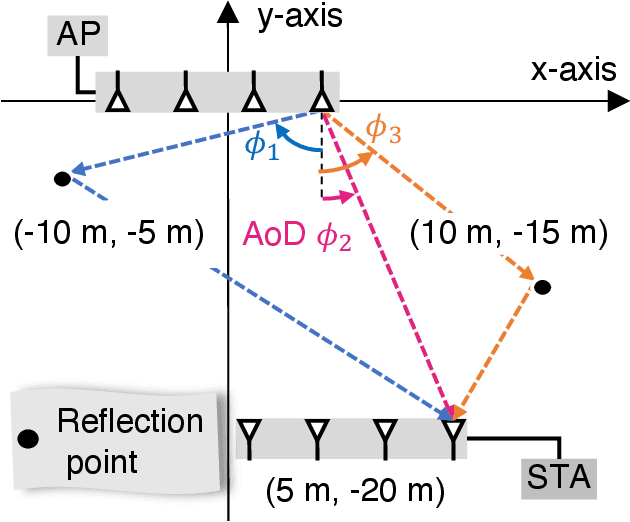
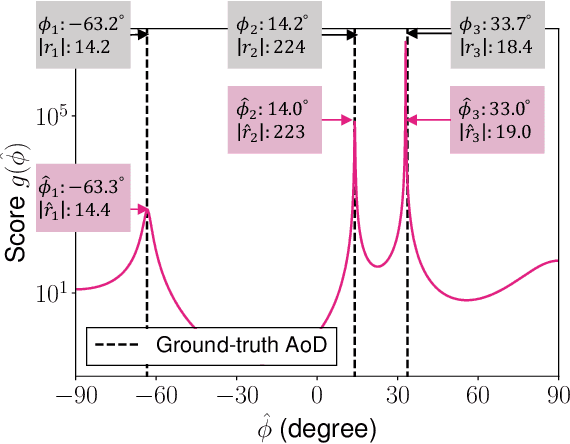
This paper proves that the angle of departure (AoD) estimation using the multiple signal classification (MUSIC) with only WiFi control frames for beamforming feedback (BFF), defined in IEEE 802.11ac/ax, is possible. Although channel state information (CSI) enables model-driven AoD estimation, most BFF-based sensing techniques are data-driven because they only contain the right singular vectors of CSI and subcarrier-averaged stream gain. Specifically, we find that right singular vectors with a subcarrier-averaged stream gain of zero have the same role as the noise subspace vectors in the CSI-based MUSIC algorithm. Numerical evaluations confirm that the proposed BFF-based MUSIC successfully estimates the AoDs and gains for all propagation paths. Meanwhile, this result implies a potential privacy risk; a malicious sniffer can carry out AoD estimation only with unencrypted BFF frames.
Packet-Loss-Tolerant Split Inference for Delay-Sensitive Deep Learning in Lossy Wireless Networks
Apr 28, 2021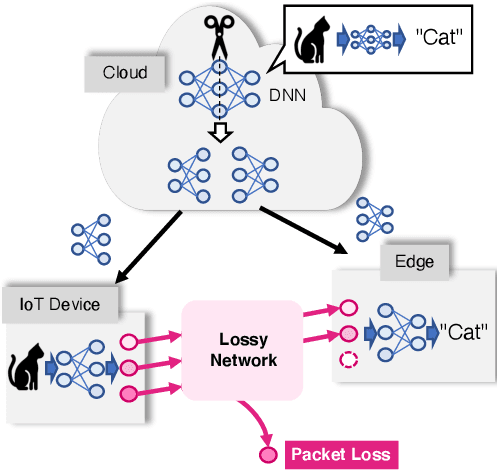
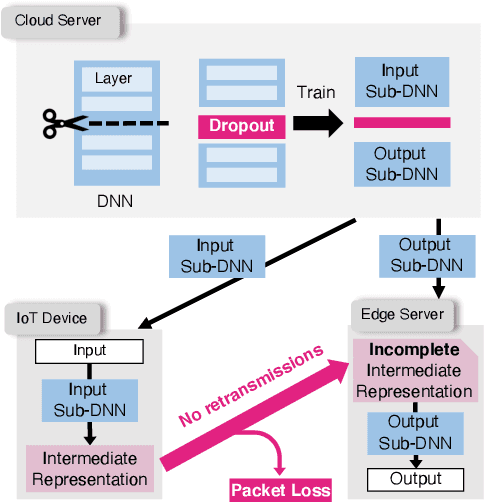
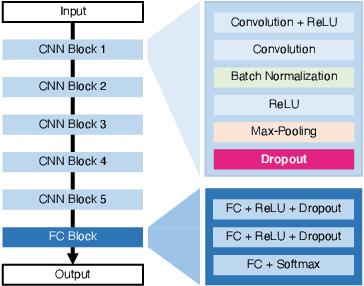
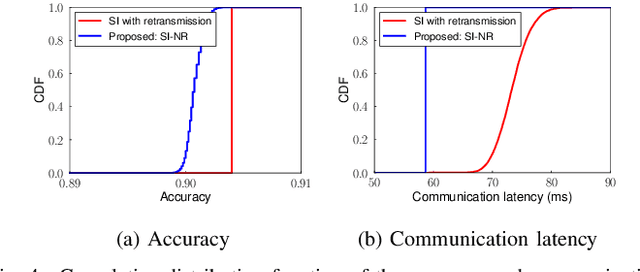
The distributed inference framework is an emerging technology for real-time applications empowered by cutting-edge deep machine learning (ML) on resource-constrained Internet of things (IoT) devices. In distributed inference, computational tasks are offloaded from the IoT device to other devices or the edge server via lossy IoT networks. However, narrow-band and lossy IoT networks cause non-negligible packet losses and retransmissions, resulting in non-negligible communication latency. This study solves the problem of the incremental retransmission latency caused by packet loss in a lossy IoT network. We propose a split inference with no retransmissions (SI-NR) method that achieves high accuracy without any retransmissions, even when packet loss occurs. In SI-NR, the key idea is to train the ML model by emulating the packet loss by a dropout method, which randomly drops the output of hidden units in a DNN layer. This enables the SI-NR system to obtain robustness against packet losses. Our ML experimental evaluation reveals that SI-NR obtains accurate predictions without packet retransmission at a packet loss rate of 60%.
Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data
Aug 14, 2020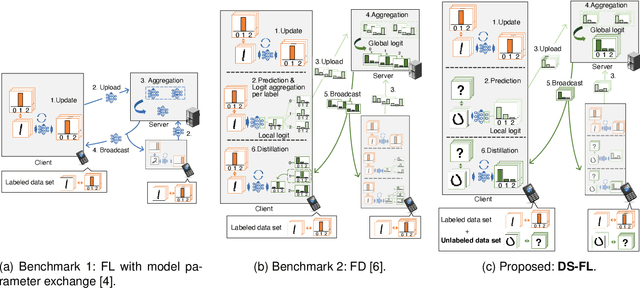

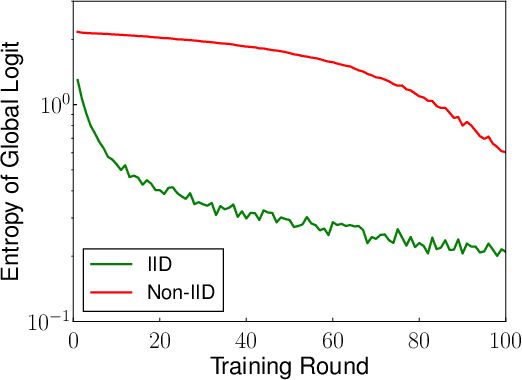
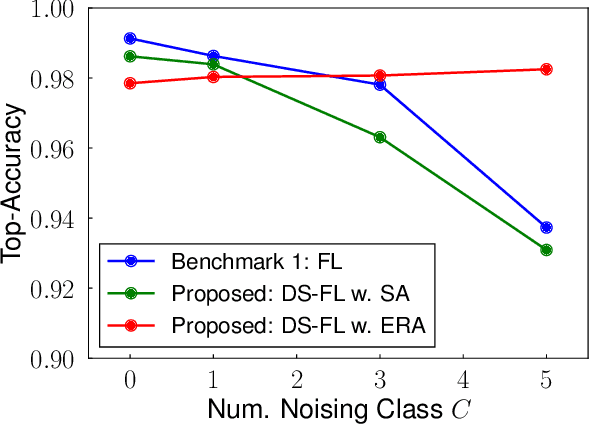
This study develops a federated learning (FL) framework overcoming largely incremental communication costs due to model sizes in typical frameworks without compromising model performance. To this end, based on the idea of leveraging an unlabeled open dataset, we propose a distillation-based semi-supervised FL (DS-FL) algorithm that exchanges the outputs of local models among mobile devices, instead of model parameter exchange employed by the typical frameworks. In DS-FL, the communication cost depends only on the output dimensions of the models and does not scale up according to the model size. The exchanged model outputs are used to label each sample of the open dataset, which creates an additionally labeled dataset. Based on the new dataset, local models are further trained, and model performance is enhanced owing to the data augmentation effect. We further highlight that in DS-FL, the heterogeneity of the devices' dataset leads to ambiguous of each data sample and lowing of the training convergence. To prevent this, we propose entropy reduction averaging, where the aggregated model outputs are intentionally sharpened. Moreover, extensive experiments show that DS-FL reduces communication costs up to 99% relative to those of the FL benchmark while achieving similar or higher classification accuracy.
Lottery Hypothesis based Unsupervised Pre-training for Model Compression in Federated Learning
Apr 21, 2020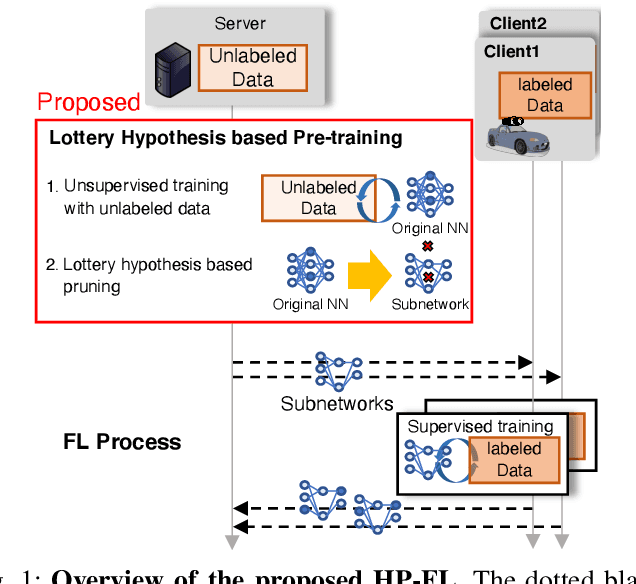


Federated learning (FL) enables a neural network (NN) to be trained using privacy-sensitive data on mobile devices while retaining all the data on their local storages. However, FL asks the mobile devices to perform heavy communication and computation tasks, i.e., devices are requested to upload and download large-volume NN models and train them. This paper proposes a novel unsupervised pre-training method adapted for FL, which aims to reduce both the communication and computation costs through model compression. Since the communication and computation costs are highly dependent on the volume of NN models, reducing the volume without decreasing model performance can reduce these costs. The proposed pre-training method leverages unlabeled data, which is expected to be obtained from the Internet or data repository much more easily than labeled data. The key idea of the proposed method is to obtain a ``good'' subnetwork from the original NN using the unlabeled data based on the lottery hypothesis. The proposed method trains an original model using a denoising auto encoder with the unlabeled data and then prunes small-magnitude parameters of the original model to generate a small but good subnetwork. The proposed method is evaluated using an image classification task. The results show that the proposed method requires 35\% less traffic and computation time than previous methods when achieving a certain test accuracy.