 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized and Model-Free Federated Learning: Consensus-Based Distillation in Function Space
Apr 02, 2021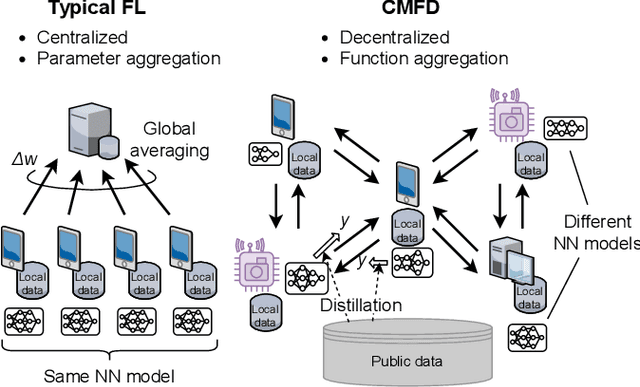
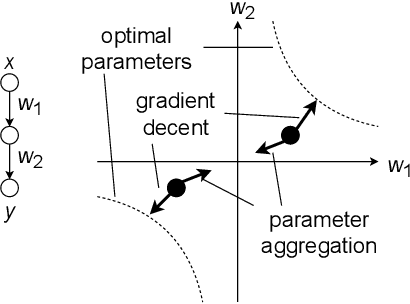
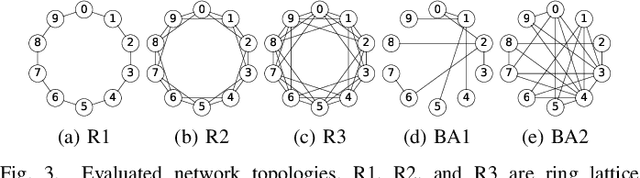
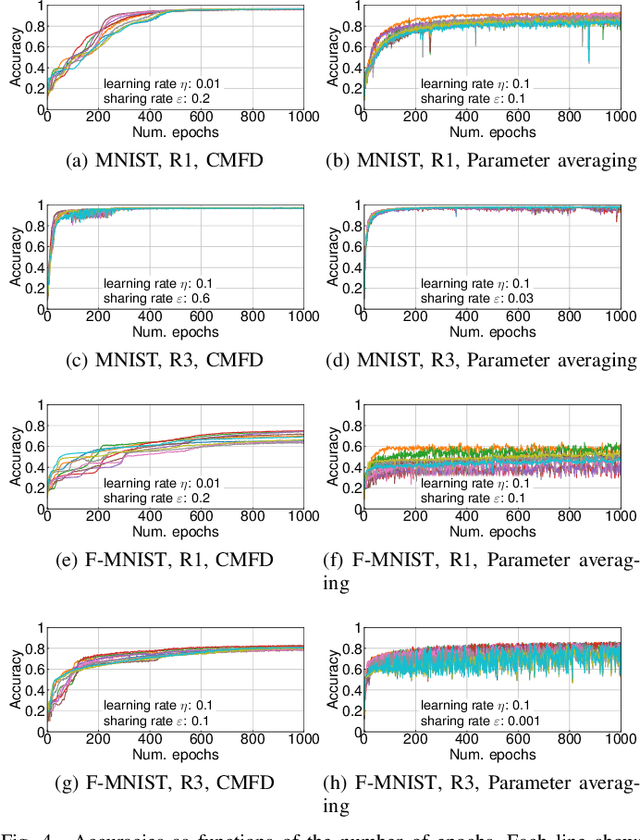
This paper proposes a decentralized FL scheme for IoE devices connected via multi-hop networks. FL has gained attention as an enabler of privacy-preserving algorithms, but it is not guaranteed that FL algorithms converge to the optimal point because of non-convexity when using decentralized parameter averaging schemes. Therefore, a distributed algorithm that converges to the optimal solution should be developed. The key idea of the proposed algorithm is to aggregate the local prediction functions, not in a parameter space but in a function space. Since machine learning tasks can be regarded as convex functional optimization problems, a consensus-based optimization algorithm achieves the global optimum if it is tailored to work in a function space. This paper at first analyzes the convergence of the proposed algorithm in a function space, which is referred to as a meta-algorithm. It is shown that spectral graph theory can be applied to the function space in a similar manner as that of numerical vectors. Then, a CMFD is developed for NN as an implementation of the meta-algorithm. CMFD leverages knowledge distillation to realize function aggregation among adjacent devices without parameter averaging. One of the advantages of CMFD is that it works even when NN models are different among the distributed learners. This paper shows that CMFD achieves higher accuracy than parameter aggregation under weakly-connected networks. The stability of CMFD is also higher than that of parameter aggregation methods.
Zero-Shot Adaptation for mmWave Beam-Tracking on Overhead Messenger Wires through Robust Adversarial Reinforcement Learning
Feb 16, 2021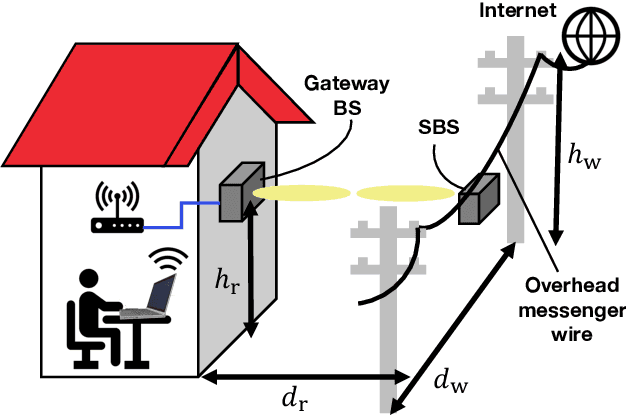
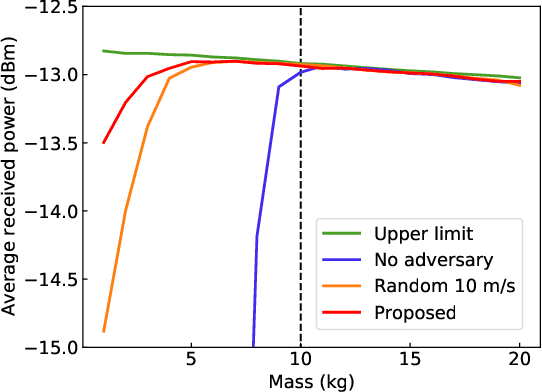
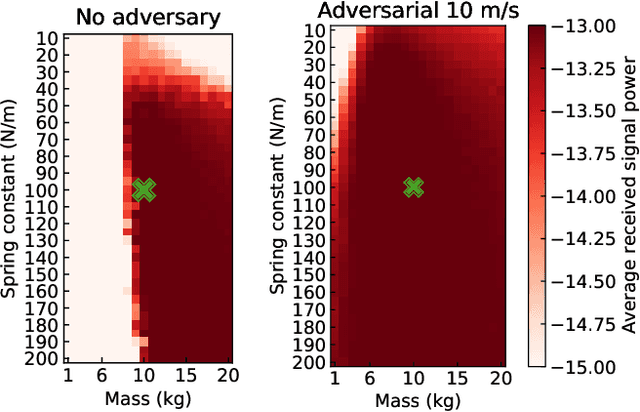
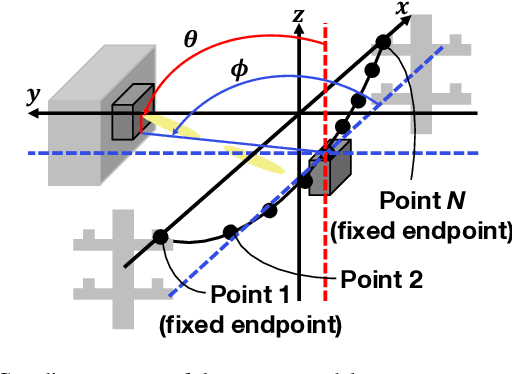
This paper discusses the opportunity of bringing the concept of zero-shot adaptation into learning-based millimeter-wave (mmWave) communication systems, particularly in environments with unstable urban infrastructures. Here, zero-shot adaptation implies that a learning agent adapts to unseen scenarios during training without any adaptive fine-tuning. By considering learning-based beam-tracking of a mmWave node placed on an overhead messenger wire, we first discuss the importance of zero-shot adaptation. More specifically, we confirm that the gap between the values of wire tension and total wire mass in training and test scenarios deteriorates the beam-tracking performance in terms of the received power. Motivated by this discussion, we propose a robust beam-tracking method to adapt to a broad range of test scenarios in a zero-shot manner, i.e., without requiring any retraining to adapt the scenarios. The key idea is to leverage a recent, robust adversarial reinforcement learning technique, where such training and test gaps are regarded as disturbances from adversaries. In our case, a beam-tracking agent performs training competitively bases on an intelligent adversary who causes beam misalignments. Numerical evaluations confirm the feasibility of zero-shot adaptation by showing that the on-wire node achieves feasible beam-tracking performance without any adaptive fine-tuning in unseen scenarios.
Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data
Aug 14, 2020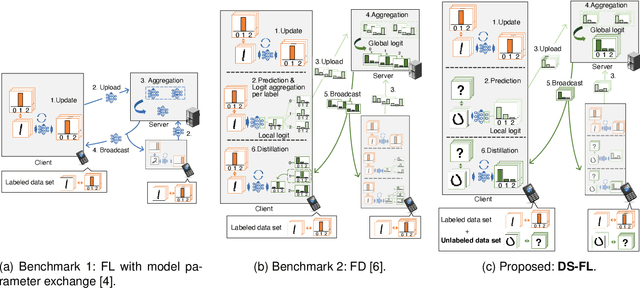

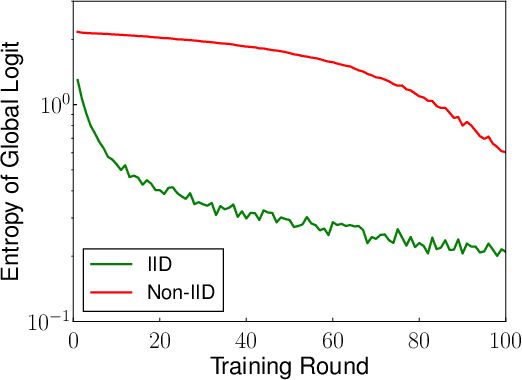
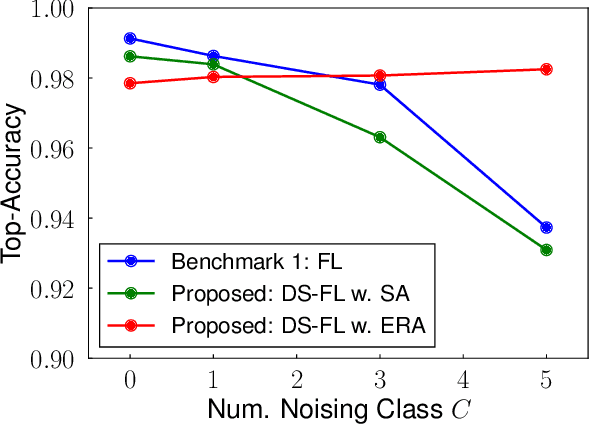
This study develops a federated learning (FL) framework overcoming largely incremental communication costs due to model sizes in typical frameworks without compromising model performance. To this end, based on the idea of leveraging an unlabeled open dataset, we propose a distillation-based semi-supervised FL (DS-FL) algorithm that exchanges the outputs of local models among mobile devices, instead of model parameter exchange employed by the typical frameworks. In DS-FL, the communication cost depends only on the output dimensions of the models and does not scale up according to the model size. The exchanged model outputs are used to label each sample of the open dataset, which creates an additionally labeled dataset. Based on the new dataset, local models are further trained, and model performance is enhanced owing to the data augmentation effect. We further highlight that in DS-FL, the heterogeneity of the devices' dataset leads to ambiguous of each data sample and lowing of the training convergence. To prevent this, we propose entropy reduction averaging, where the aggregated model outputs are intentionally sharpened. Moreover, extensive experiments show that DS-FL reduces communication costs up to 99% relative to those of the FL benchmark while achieving similar or higher classification accuracy.
Lottery Hypothesis based Unsupervised Pre-training for Model Compression in Federated Learning
Apr 21, 2020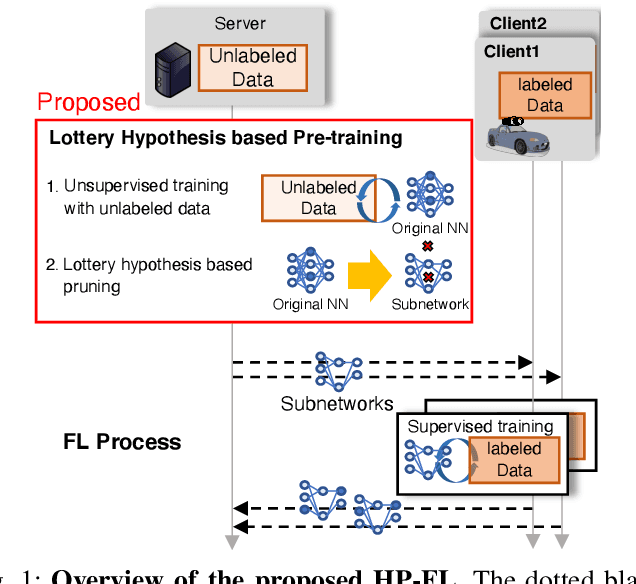


Federated learning (FL) enables a neural network (NN) to be trained using privacy-sensitive data on mobile devices while retaining all the data on their local storages. However, FL asks the mobile devices to perform heavy communication and computation tasks, i.e., devices are requested to upload and download large-volume NN models and train them. This paper proposes a novel unsupervised pre-training method adapted for FL, which aims to reduce both the communication and computation costs through model compression. Since the communication and computation costs are highly dependent on the volume of NN models, reducing the volume without decreasing model performance can reduce these costs. The proposed pre-training method leverages unlabeled data, which is expected to be obtained from the Internet or data repository much more easily than labeled data. The key idea of the proposed method is to obtain a ``good'' subnetwork from the original NN using the unlabeled data based on the lottery hypothesis. The proposed method trains an original model using a denoising auto encoder with the unlabeled data and then prunes small-magnitude parameters of the original model to generate a small but good subnetwork. The proposed method is evaluated using an image classification task. The results show that the proposed method requires 35\% less traffic and computation time than previous methods when achieving a certain test accuracy.
Hybrid-FL: Cooperative Learning Mechanism Using Non-IID Data in Wireless Networks
May 17, 2019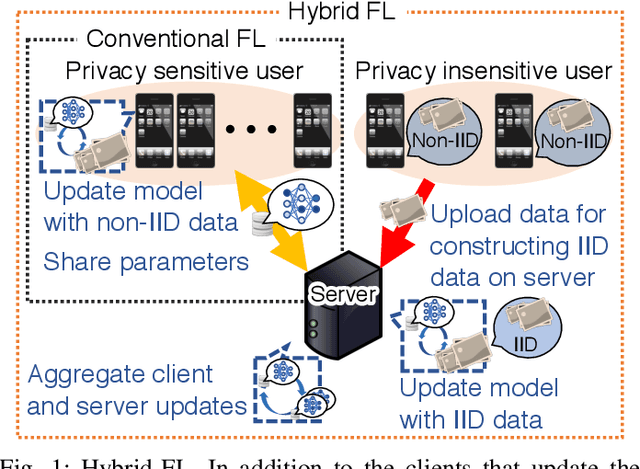
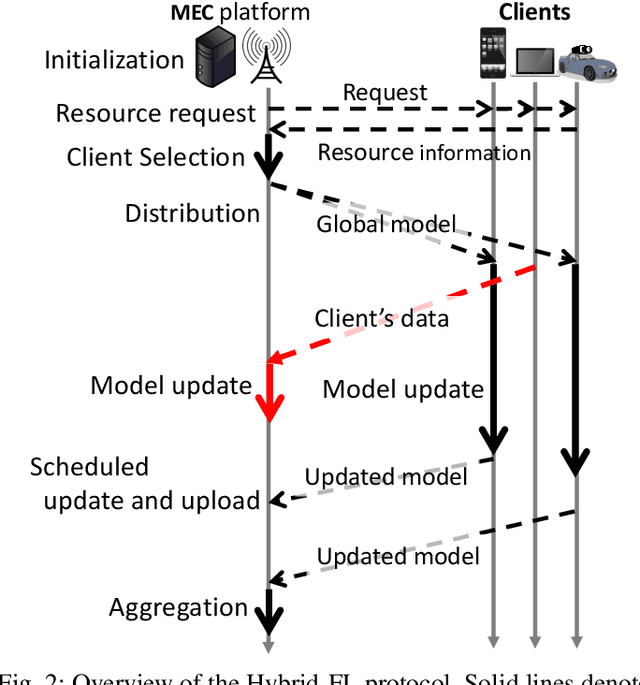
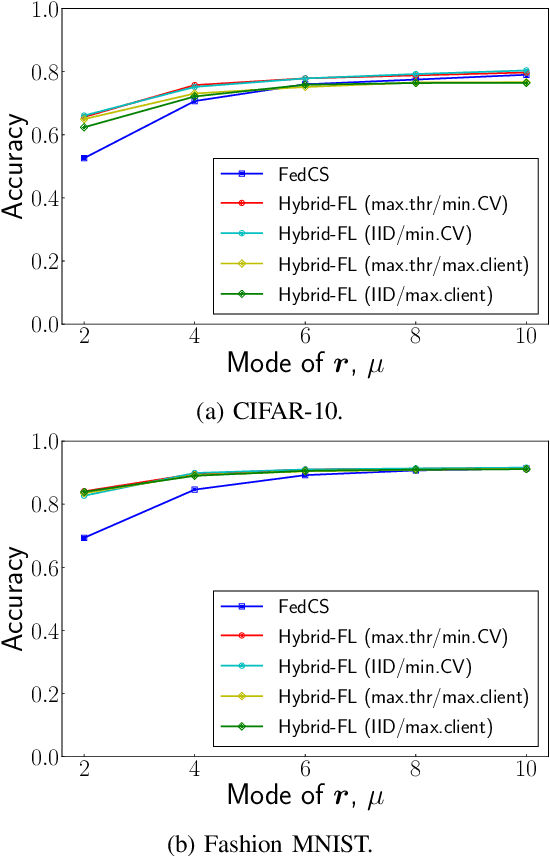

A decentralized learning mechanism, Federated Learning (FL), has attracted much attention, which enables privacy-preserving training using the rich data and computational resources of mobile clients. However, data on mobile clients is typically not independent and identically distributed (IID) owing to diverse of mobile users' interest and usage, and FL on non-IID data could degrade the model performance. This work aims to extend FL to solve the performance degradation problem resulting from non-IID data of mobile clients. We assume that a limited number (e.g., less than 1%) of clients who allow their data to be uploaded to a server, and we propose a novel learning mechanism referred to as Hybrid-FL, where the server updates the model using data gathered from the clients and merge the model with models trained by clients. In Hybrid-FL, we design a heuristic algorithms that solves the data and client selection problem to construct "good" dataset on the server under bandwidth and time limitation. The algorithm increases the amount of data gathered from clients and makes the data approximately IID for improving model performance. Evaluations consisting of network simulations and machine learning (ML) experiments show that the proposed scheme achieves a significantly higher classification accuracy than previous schemes in the non-IID case.
Deep Reinforcement Learning-Based Channel Allocation for Wireless LANs with Graph Convolutional Networks
May 17, 2019

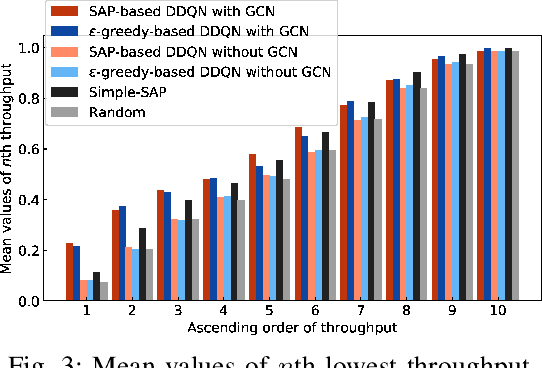
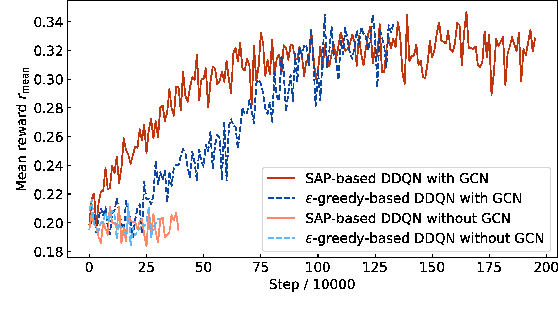
Last year, IEEE 802.11 Extremely High Throughput Study Group (EHT Study Group) was established to initiate discussions on new IEEE 802.11 features. Coordinated control methods of the access points (APs) in the wireless local area networks (WLANs) are discussed in EHT Study Group. The present study proposes a deep reinforcement learning-based channel allocation scheme using graph convolutional networks (GCNs). As a deep reinforcement learning method, we use a well-known method double deep Q-network. In densely deployed WLANs, the number of the available topologies of APs is extremely high, and thus we extract the features of the topological structures based on GCNs. We apply GCNs to a contention graph where APs within their carrier sensing ranges are connected to extract the features of carrier sensing relationships. Additionally, to improve the learning speed especially in an early stage of learning, we employ a game theory-based method to collect the training data independently of the neural network model. The simulation results indicate that the proposed method can appropriately control the channels when compared to extant methods.