 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLottery Hypothesis based Unsupervised Pre-training for Model Compression in Federated Learning
Paper and Code
Apr 21, 2020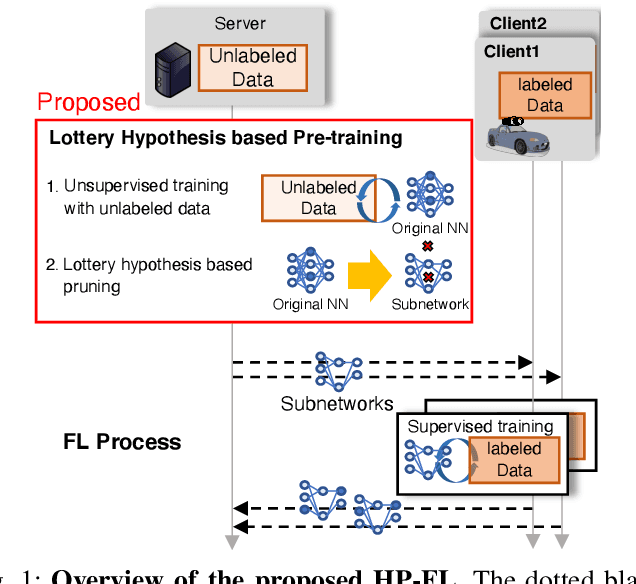


Federated learning (FL) enables a neural network (NN) to be trained using privacy-sensitive data on mobile devices while retaining all the data on their local storages. However, FL asks the mobile devices to perform heavy communication and computation tasks, i.e., devices are requested to upload and download large-volume NN models and train them. This paper proposes a novel unsupervised pre-training method adapted for FL, which aims to reduce both the communication and computation costs through model compression. Since the communication and computation costs are highly dependent on the volume of NN models, reducing the volume without decreasing model performance can reduce these costs. The proposed pre-training method leverages unlabeled data, which is expected to be obtained from the Internet or data repository much more easily than labeled data. The key idea of the proposed method is to obtain a ``good'' subnetwork from the original NN using the unlabeled data based on the lottery hypothesis. The proposed method trains an original model using a denoising auto encoder with the unlabeled data and then prunes small-magnitude parameters of the original model to generate a small but good subnetwork. The proposed method is evaluated using an image classification task. The results show that the proposed method requires 35\% less traffic and computation time than previous methods when achieving a certain test accuracy.