 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data
Paper and Code
Aug 14, 2020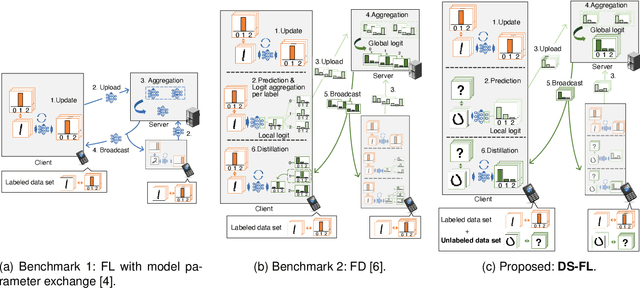

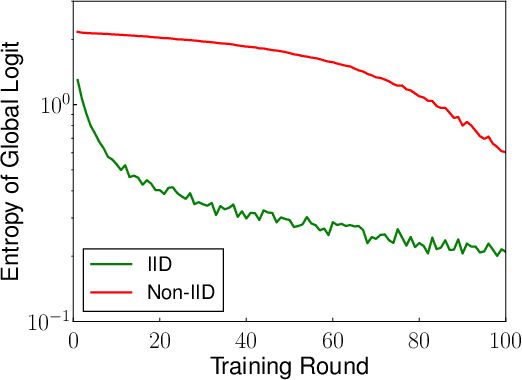
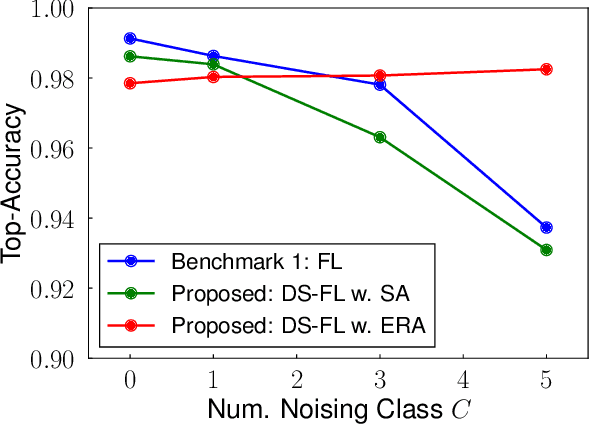
This study develops a federated learning (FL) framework overcoming largely incremental communication costs due to model sizes in typical frameworks without compromising model performance. To this end, based on the idea of leveraging an unlabeled open dataset, we propose a distillation-based semi-supervised FL (DS-FL) algorithm that exchanges the outputs of local models among mobile devices, instead of model parameter exchange employed by the typical frameworks. In DS-FL, the communication cost depends only on the output dimensions of the models and does not scale up according to the model size. The exchanged model outputs are used to label each sample of the open dataset, which creates an additionally labeled dataset. Based on the new dataset, local models are further trained, and model performance is enhanced owing to the data augmentation effect. We further highlight that in DS-FL, the heterogeneity of the devices' dataset leads to ambiguous of each data sample and lowing of the training convergence. To prevent this, we propose entropy reduction averaging, where the aggregated model outputs are intentionally sharpened. Moreover, extensive experiments show that DS-FL reduces communication costs up to 99% relative to those of the FL benchmark while achieving similar or higher classification accuracy.