 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Aided Frame-Capture-Based CSI Recomposition for WiFi Sensing: A Multimodal Approach
Jun 03, 2022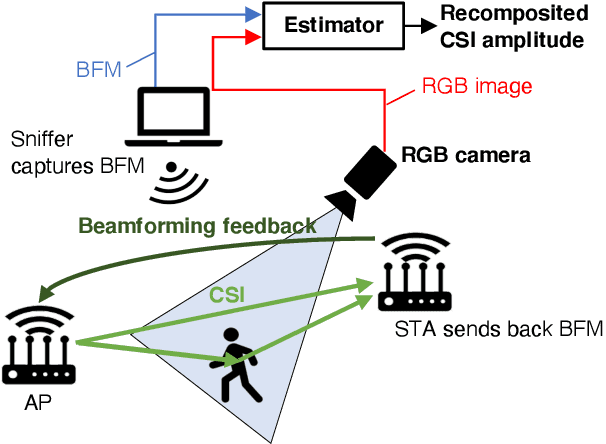
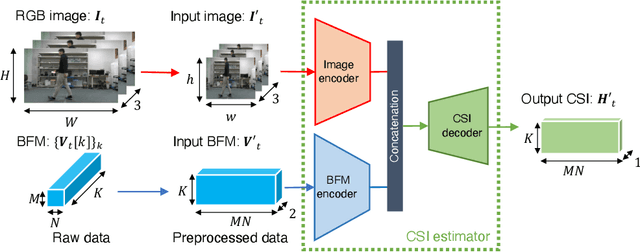
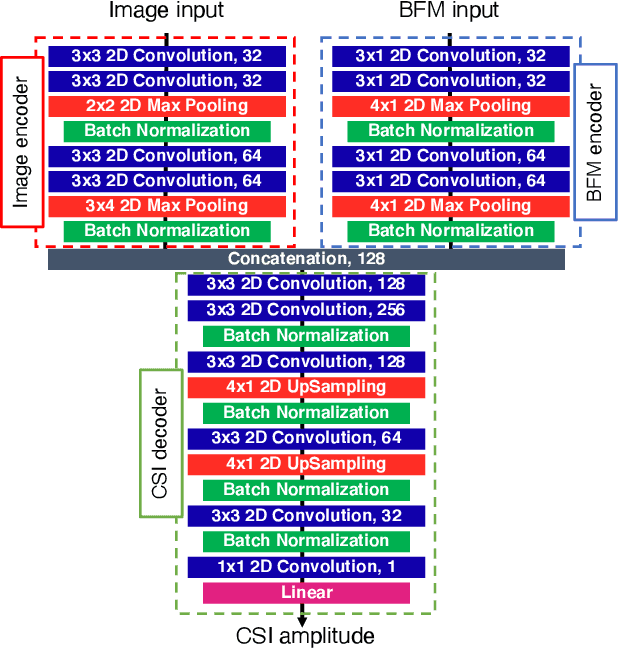

Recompositing channel state information (CSI) from the beamforming feedback matrix (BFM), which is a compressed version of CSI and can be captured because of its lack of encryption, is an alternative way of implementing firmware-agnostic WiFi sensing. In this study, we propose the use of camera images toward the accuracy enhancement of CSI recomposition from BFM. The key motivation for this vision-aided CSI recomposition is to draw a first-hand insight that the BFM does not fully involve spatial information to recomposite CSI and that this could be compensated by camera images. To leverage the camera images, we use multimodal deep learning, where the two modalities, i.e., images and BFMs, are integrated to recomposite the CSI. We conducted experiments using IEEE 802.11ac devices. The experimental results confirmed that the recomposition accuracy of the proposed multimodal framework is improved compared to the single-modal framework only using images or BFMs.
Communication-oriented Model Fine-tuning for Packet-loss Resilient Distributed Inference under Highly Lossy IoT Networks
Dec 17, 2021
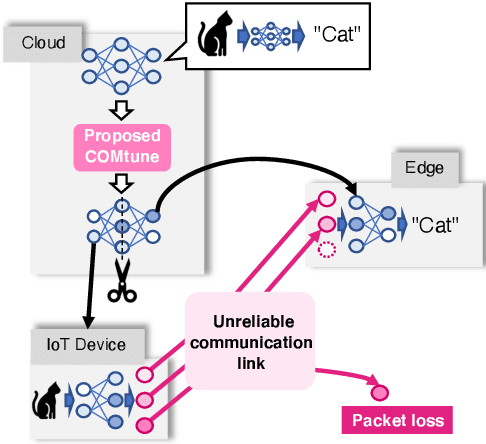
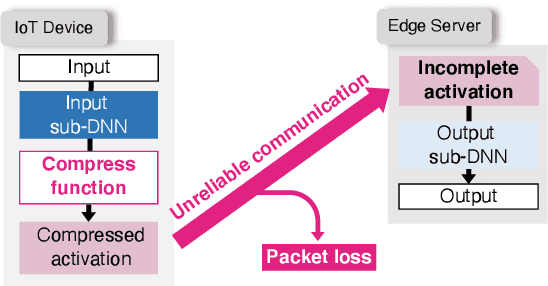
The distributed inference (DI) framework has gained traction as a technique for real-time applications empowered by cutting-edge deep machine learning (ML) on resource-constrained Internet of things (IoT) devices. In DI, computational tasks are offloaded from the IoT device to the edge server via lossy IoT networks. However, generally, there is a communication system-level trade-off between communication latency and reliability; thus, to provide accurate DI results, a reliable and high-latency communication system is required to be adapted, which results in non-negligible end-to-end latency of the DI. This motivated us to improve the trade-off between the communication latency and accuracy by efforts on ML techniques. Specifically, we have proposed a communication-oriented model tuning (COMtune), which aims to achieve highly accurate DI with low-latency but unreliable communication links. In COMtune, the key idea is to fine-tune the ML model by emulating the effect of unreliable communication links through the application of the dropout technique. This enables the DI system to obtain robustness against unreliable communication links. Our ML experiments revealed that COMtune enables accurate predictions with low latency and under lossy networks.
Frame-Capture-Based CSI Recomposition Pertaining to Firmware-Agnostic WiFi Sensing
Oct 29, 2021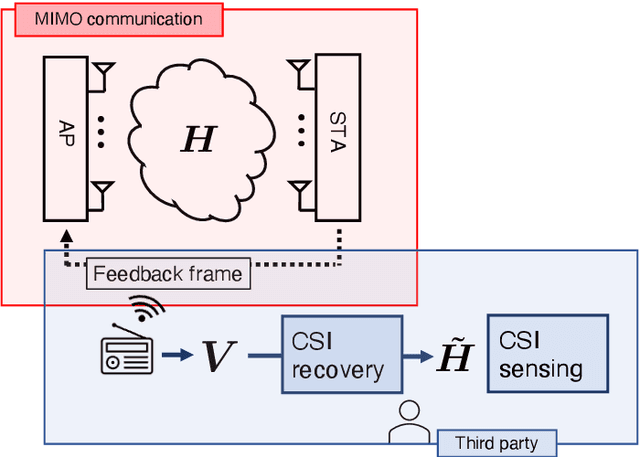
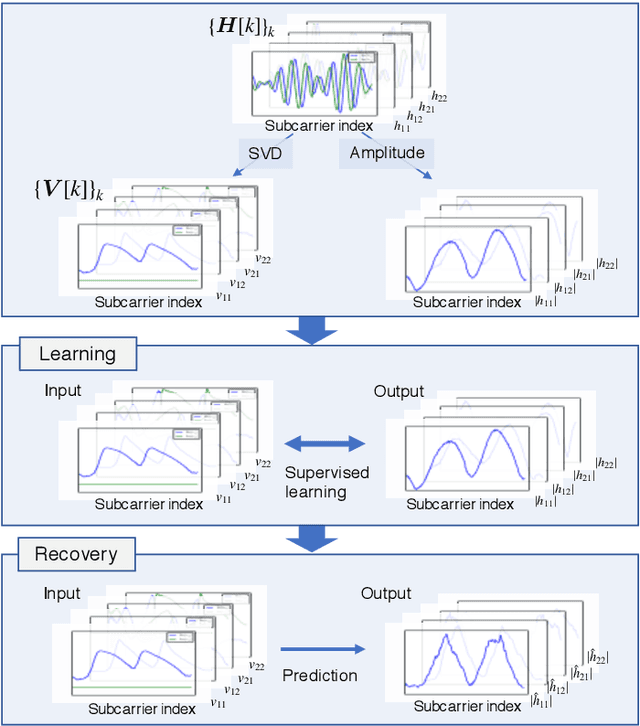
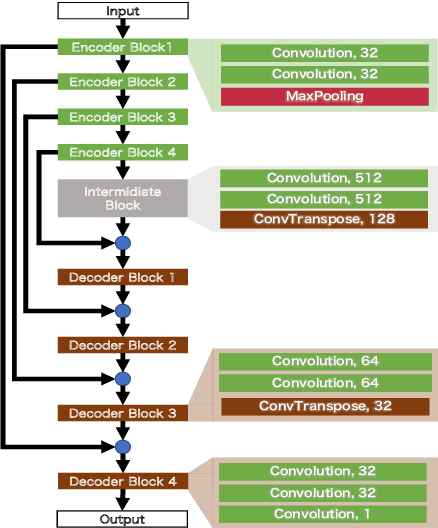
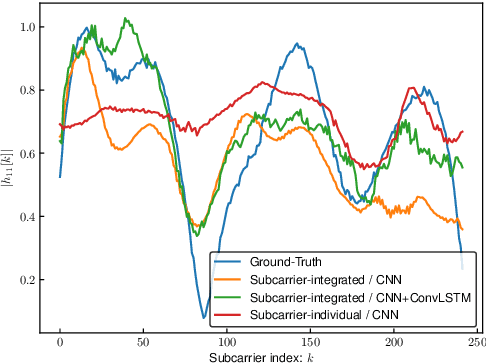
With regard to the implementation of WiFi sensing agnostic according to the availability of channel state information (CSI), we investigate the possibility of estimating a CSI matrix based on its compressed version, which is known as beamforming feedback matrix (BFM). Being different from the CSI matrix that is processed and discarded in physical layer components, the BFM can be captured using a medium-access-layer frame-capturing technique because this is exchanged among an access point (AP) and stations (STAs) over the air. This indicates that WiFi sensing that leverages the BFM matrix is more practical to implement using the pre-installed APs. However, the ability of BFM-based sensing has been evaluated in a few tasks, and more general insights into its performance should be provided. To fill this gap, we propose a CSI estimation method based on BFM, approximating the estimation function with a machine learning model. In addition, to improve the estimation accuracy, we leverage the inter-subcarrier dependency using the BFMs at multiple subcarriers in orthogonal frequency division multiplexing transmissions. Our simulation evaluation reveals that the estimated CSI matches the ground-truth amplitude. Moreover, compared to CSI estimation at each individual subcarrier, the effect of the BFMs at multiple subcarriers on the CSI estimation accuracy is validated.
AirMixML: Over-the-Air Data Mixup for Inherently Privacy-Preserving Edge Machine Learning
May 02, 2021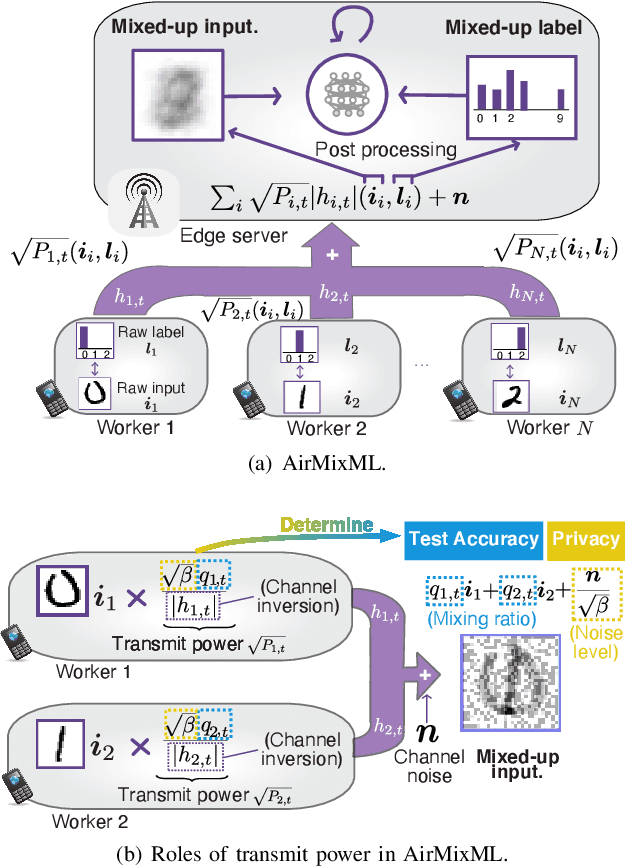


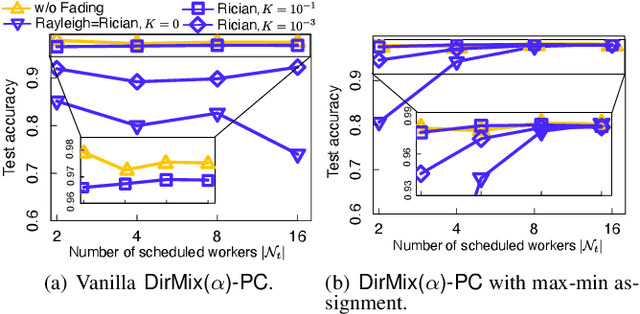
Wireless channels can be inherently privacy-preserving by distorting the received signals due to channel noise, and superpositioning multiple signals over-the-air. By harnessing these natural distortions and superpositions by wireless channels, we propose a novel privacy-preserving machine learning (ML) framework at the network edge, coined over-the-air mixup ML (AirMixML). In AirMixML, multiple workers transmit analog-modulated signals of their private data samples to an edge server who trains an ML model using the received noisy-and superpositioned samples. AirMixML coincides with model training using mixup data augmentation achieving comparable accuracy to that with raw data samples. From a privacy perspective, AirMixML is a differentially private (DP) mechanism limiting the disclosure of each worker's private sample information at the server, while the worker's transmit power determines the privacy disclosure level. To this end, we develop a fractional channel-inversion power control (PC) method, {\alpha}-Dirichlet mixup PC (DirMix({\alpha})-PC), wherein for a given global power scaling factor after channel inversion, each worker's local power contribution to the superpositioned signal is controlled by the Dirichlet dispersion ratio {\alpha}. Mathematically, we derive a closed-form expression clarifying the relationship between the local and global PC factors to guarantee a target DP level. By simulations, we provide DirMix({\alpha})-PC design guidelines to improve accuracy, privacy, and energy-efficiency. Finally, AirMixML with DirMix({\alpha})-PC is shown to achieve reasonable accuracy compared to a privacy-violating baseline with neither superposition nor PC.
Zero-Shot Adaptation for mmWave Beam-Tracking on Overhead Messenger Wires through Robust Adversarial Reinforcement Learning
Feb 16, 2021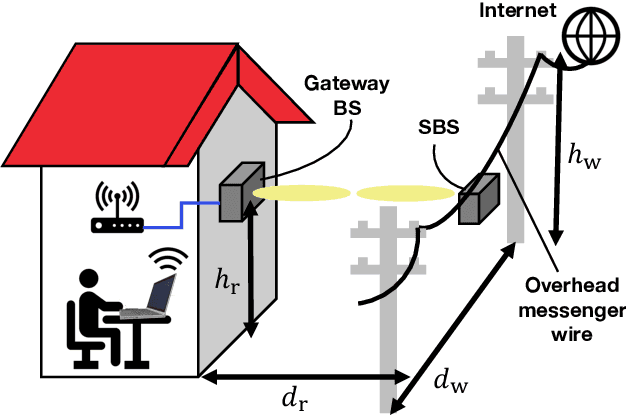
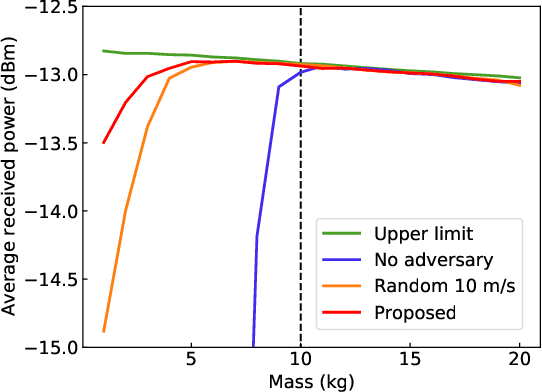
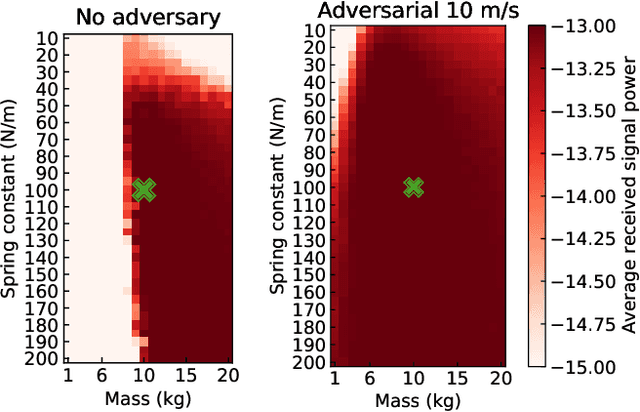
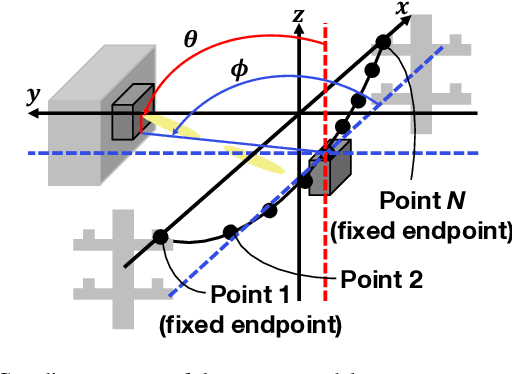
This paper discusses the opportunity of bringing the concept of zero-shot adaptation into learning-based millimeter-wave (mmWave) communication systems, particularly in environments with unstable urban infrastructures. Here, zero-shot adaptation implies that a learning agent adapts to unseen scenarios during training without any adaptive fine-tuning. By considering learning-based beam-tracking of a mmWave node placed on an overhead messenger wire, we first discuss the importance of zero-shot adaptation. More specifically, we confirm that the gap between the values of wire tension and total wire mass in training and test scenarios deteriorates the beam-tracking performance in terms of the received power. Motivated by this discussion, we propose a robust beam-tracking method to adapt to a broad range of test scenarios in a zero-shot manner, i.e., without requiring any retraining to adapt the scenarios. The key idea is to leverage a recent, robust adversarial reinforcement learning technique, where such training and test gaps are regarded as disturbances from adversaries. In our case, a beam-tracking agent performs training competitively bases on an intelligent adversary who causes beam misalignments. Numerical evaluations confirm the feasibility of zero-shot adaptation by showing that the on-wire node achieves feasible beam-tracking performance without any adaptive fine-tuning in unseen scenarios.
When Wireless Communications Meet Computer Vision in Beyond 5G
Oct 13, 2020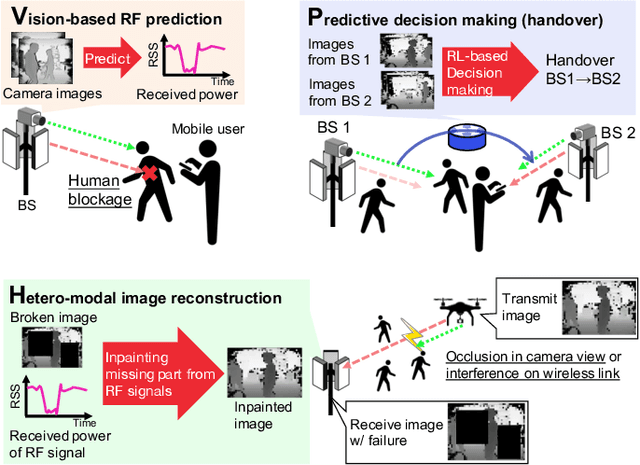
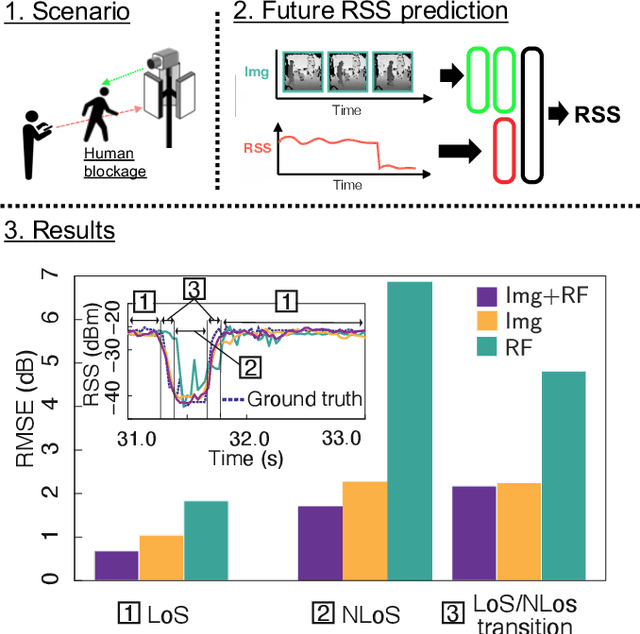
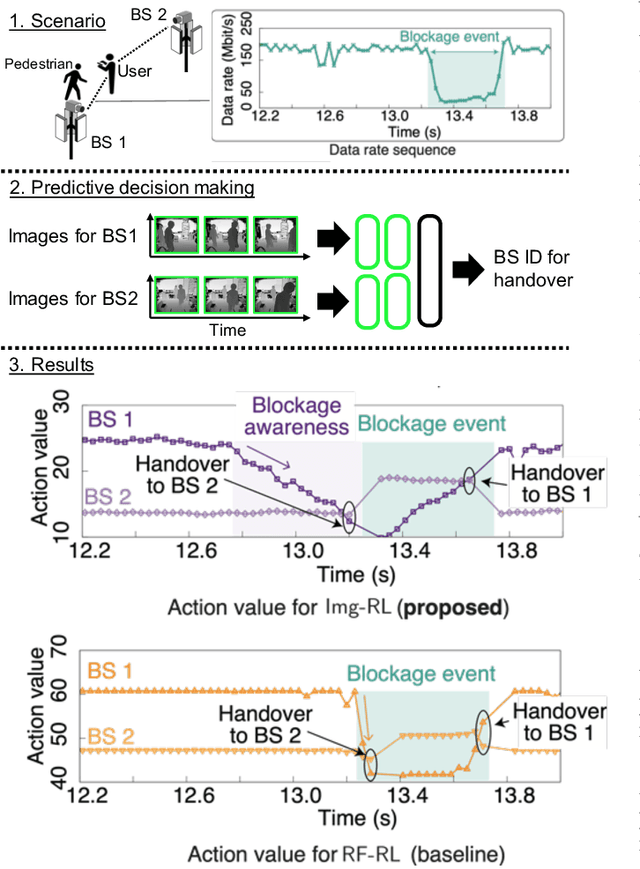
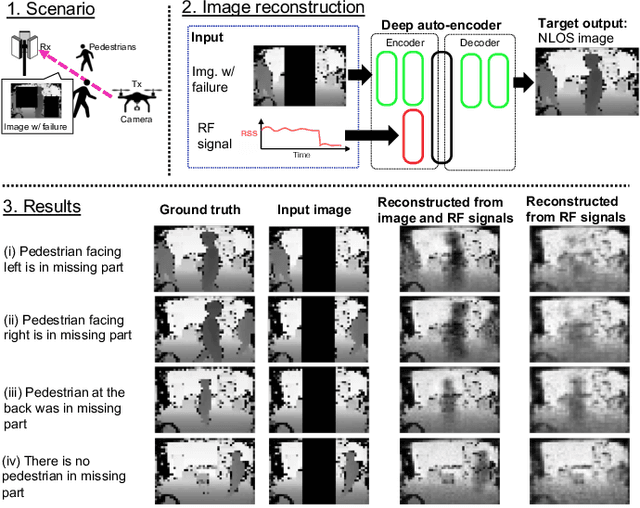
This article articulates the emerging paradigm, sitting at the confluence of computer vision and wireless communication, to enable beyond-5G/6G mission-critical applications (autonomous/remote-controlled vehicles, visuo-haptic VR, and other cyber-physical applications). First, drawing on recent advances in machine learning and the availability of non-RF data, vision-aided wireless networks are shown to significantly enhance the reliability of wireless communication without sacrificing spectral efficiency. In particular, we demonstrate how computer vision enables {look-ahead} prediction in a millimeter-wave channel blockage scenario, before the blockage actually happens. From a computer vision perspective, we highlight how radio frequency (RF) based sensing and imaging are instrumental in robustifying computer vision applications against occlusion and failure. This is corroborated via an RF-based image reconstruction use case, showcasing a receiver-side image failure correction resulting in reduced retransmission and latency. Taken together, this article sheds light on the much-needed convergence of RF and non-RF modalities to enable ultra-reliable communication and truly intelligent 6G networks.
Distillation-Based Semi-Supervised Federated Learning for Communication-Efficient Collaborative Training with Non-IID Private Data
Aug 14, 2020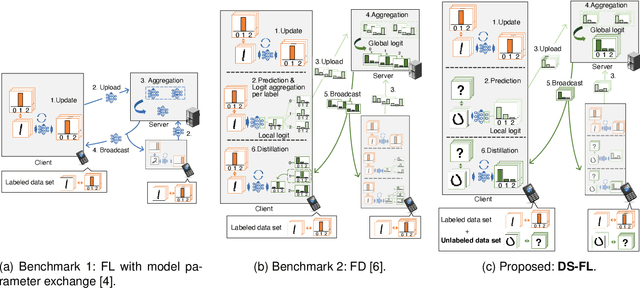

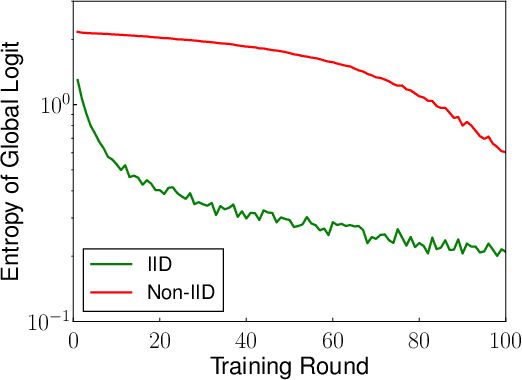
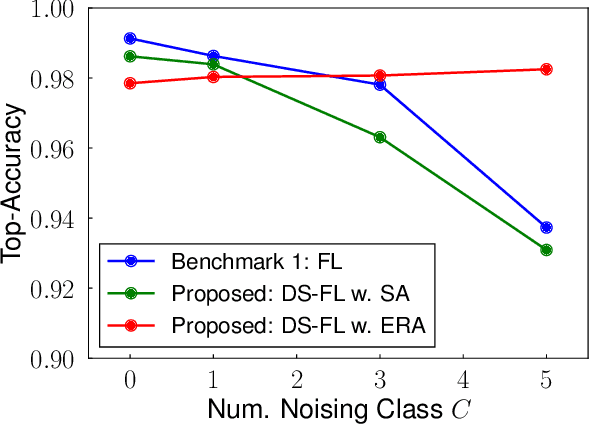
This study develops a federated learning (FL) framework overcoming largely incremental communication costs due to model sizes in typical frameworks without compromising model performance. To this end, based on the idea of leveraging an unlabeled open dataset, we propose a distillation-based semi-supervised FL (DS-FL) algorithm that exchanges the outputs of local models among mobile devices, instead of model parameter exchange employed by the typical frameworks. In DS-FL, the communication cost depends only on the output dimensions of the models and does not scale up according to the model size. The exchanged model outputs are used to label each sample of the open dataset, which creates an additionally labeled dataset. Based on the new dataset, local models are further trained, and model performance is enhanced owing to the data augmentation effect. We further highlight that in DS-FL, the heterogeneity of the devices' dataset leads to ambiguous of each data sample and lowing of the training convergence. To prevent this, we propose entropy reduction averaging, where the aggregated model outputs are intentionally sharpened. Moreover, extensive experiments show that DS-FL reduces communication costs up to 99% relative to those of the FL benchmark while achieving similar or higher classification accuracy.