 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManipulation-Oriented Object Perception in Clutter through Affordance Coordinate Frames
Oct 16, 2020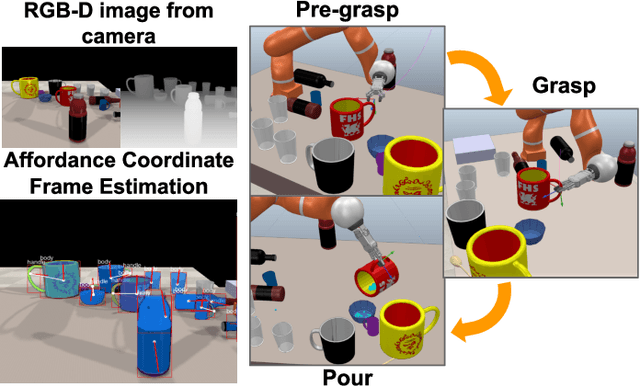
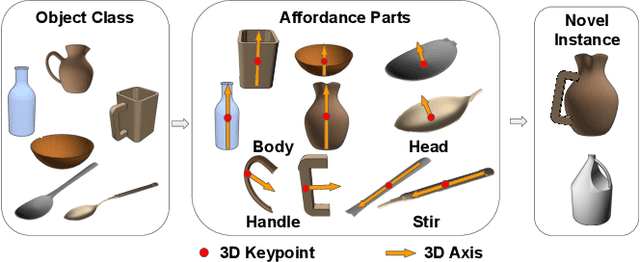
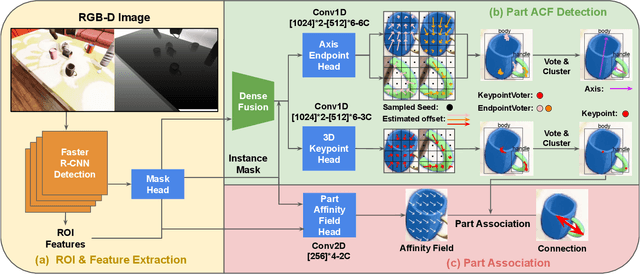
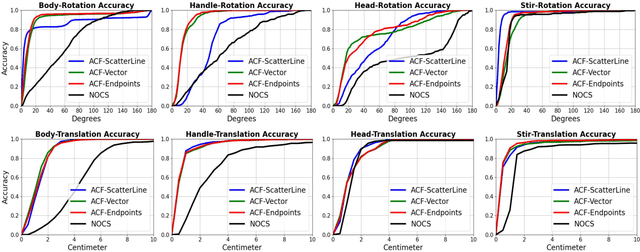
In order to enable robust operation in unstructured environments, robots should be able to generalize manipulation actions to novel object instances. For example, to pour and serve a drink, a robot should be able to recognize novel containers which afford the task. Most importantly, robots should be able to manipulate these novel containers to fulfill the task. To achieve this, we aim to provide robust and generalized perception of object affordances and their associated manipulation poses for reliable manipulation. In this work, we combine the notions of affordance and category-level pose, and introduce the Affordance Coordinate Frame (ACF). With ACF, we represent each object class in terms of individual affordance parts and the compatibility between them, where each part is associated with a part category-level pose for robot manipulation. In our experiments, we demonstrate that ACF outperforms state-of-the-art methods for object detection, as well as category-level pose estimation for object parts. We further demonstrate the applicability of ACF to robot manipulation tasks through experiments in a simulated environment.
Deepfake Detection using Spatiotemporal Convolutional Networks
Jun 26, 2020
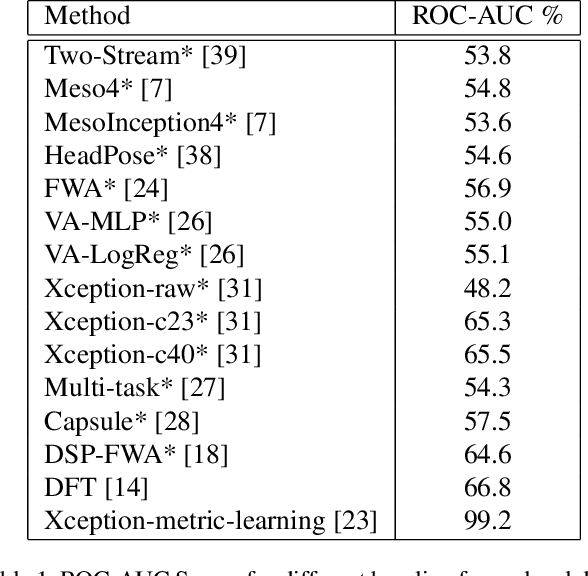
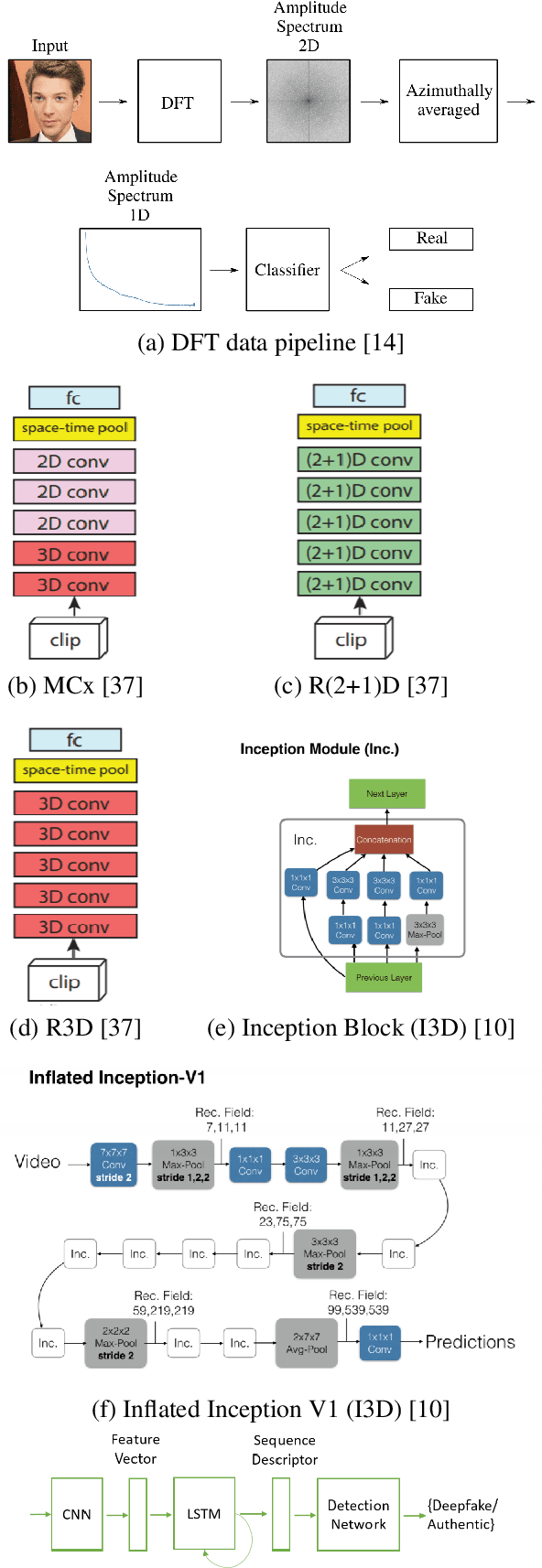
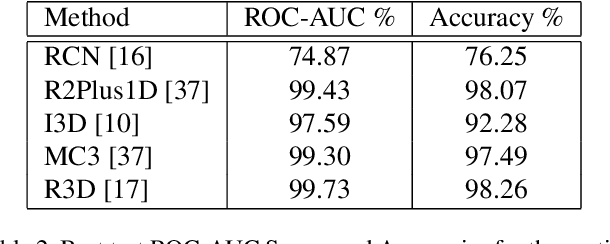
Better generative models and larger datasets have led to more realistic fake videos that can fool the human eye but produce temporal and spatial artifacts that deep learning approaches can detect. Most current Deepfake detection methods only use individual video frames and therefore fail to learn from temporal information. We created a benchmark of the performance of spatiotemporal convolutional methods using the Celeb-DF dataset. Our methods outperformed state-of-the-art frame-based detection methods. Code for our paper is publicly available at https://github.com/oidelima/Deepfake-Detection.