Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Detection using Spatiotemporal Convolutional Networks
Jun 26, 2020
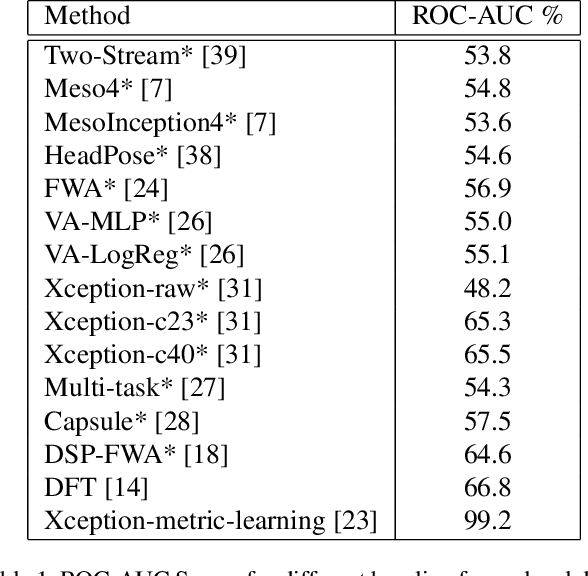
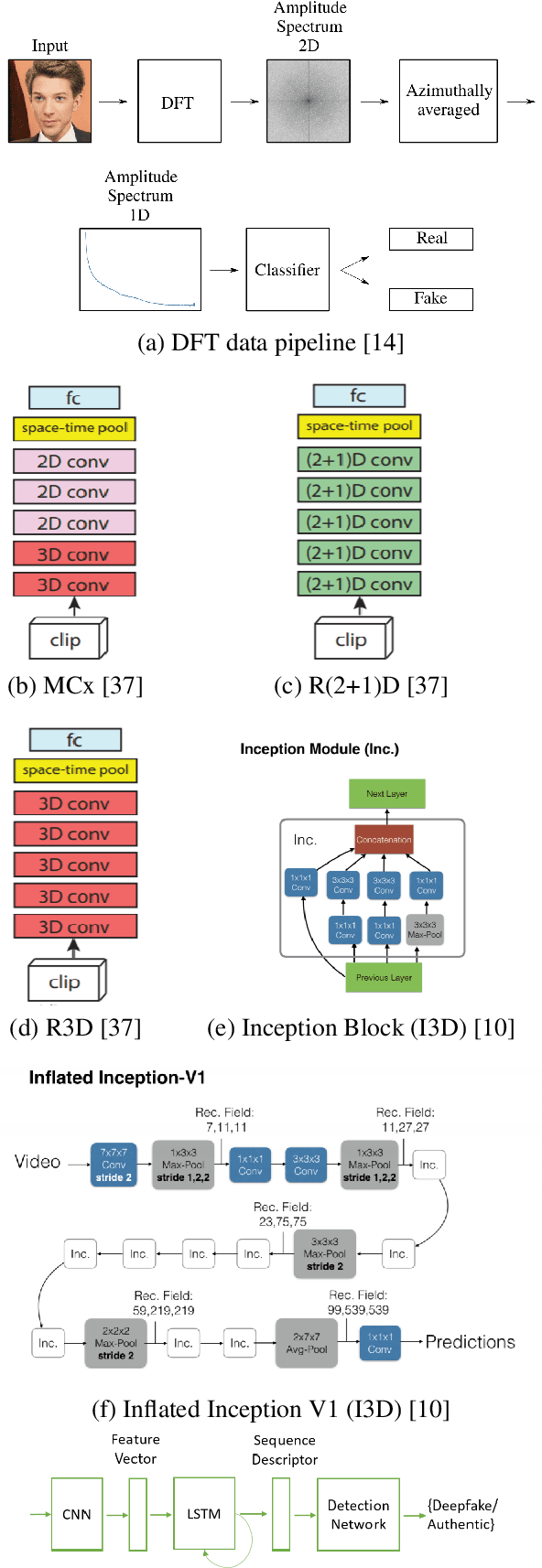
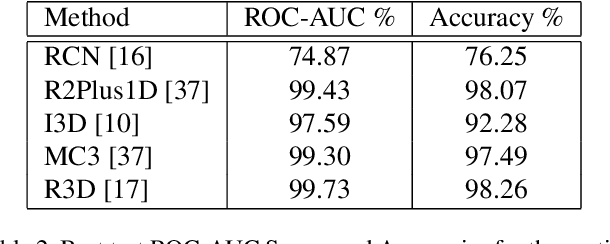
Better generative models and larger datasets have led to more realistic fake videos that can fool the human eye but produce temporal and spatial artifacts that deep learning approaches can detect. Most current Deepfake detection methods only use individual video frames and therefore fail to learn from temporal information. We created a benchmark of the performance of spatiotemporal convolutional methods using the Celeb-DF dataset. Our methods outperformed state-of-the-art frame-based detection methods. Code for our paper is publicly available at https://github.com/oidelima/Deepfake-Detection.
Via