 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"One-Shot" Reduction of Additive Artifacts in Medical Images
Oct 23, 2021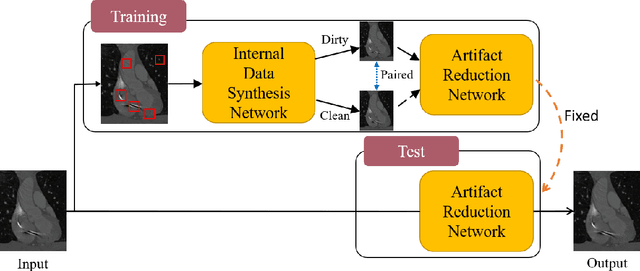
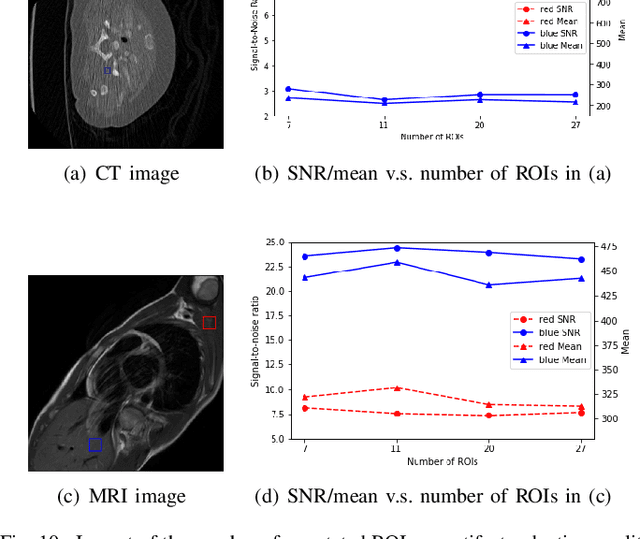
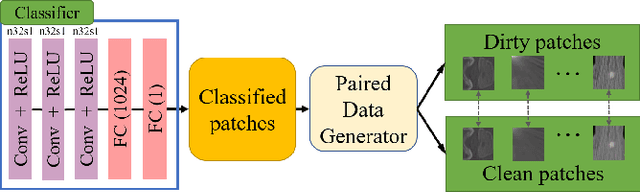

Medical images may contain various types of artifacts with different patterns and mixtures, which depend on many factors such as scan setting, machine condition, patients' characteristics, surrounding environment, etc. However, existing deep-learning-based artifact reduction methods are restricted by their training set with specific predetermined artifact types and patterns. As such, they have limited clinical adoption. In this paper, we introduce One-Shot medical image Artifact Reduction (OSAR), which exploits the power of deep learning but without using pre-trained general networks. Specifically, we train a light-weight image-specific artifact reduction network using data synthesized from the input image at test-time. Without requiring any prior large training data set, OSAR can work with almost any medical images that contain varying additive artifacts which are not in any existing data sets. In addition, Computed Tomography (CT) and Magnetic Resonance Imaging (MRI) are used as vehicles and show that the proposed method can reduce artifacts better than state-of-the-art both qualitatively and quantitatively using shorter test time.
Do Noises Bother Human and Neural Networks In the Same Way? A Medical Image Analysis Perspective
Nov 04, 2020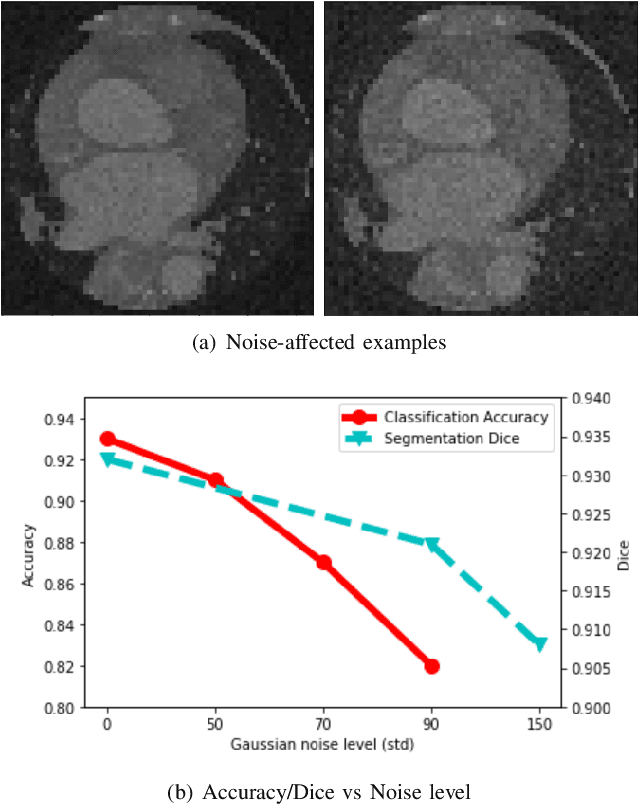
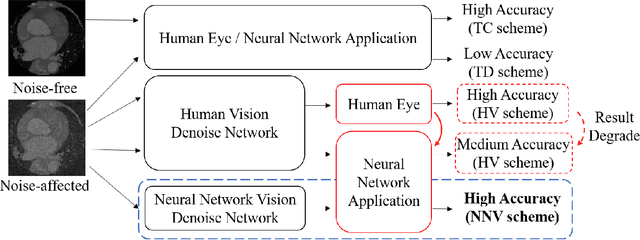
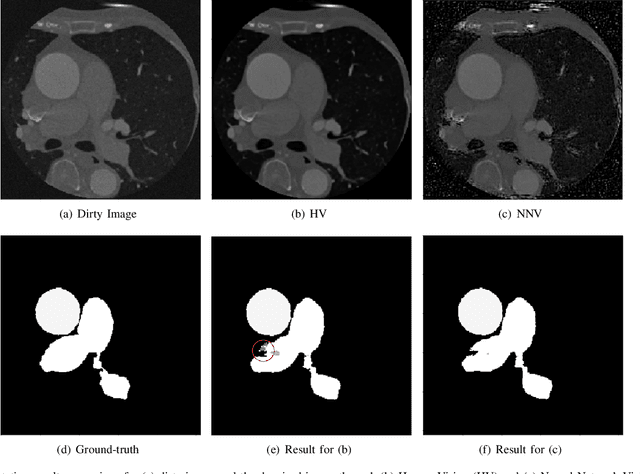
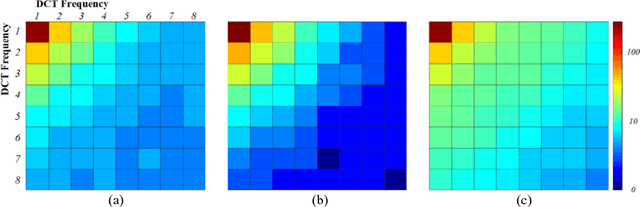
Deep learning had already demonstrated its power in medical images, including denoising, classification, segmentation, etc. All these applications are proposed to automatically analyze medical images beforehand, which brings more information to radiologists during clinical assessment for accuracy improvement. Recently, many medical denoising methods had shown their significant artifact reduction result and noise removal both quantitatively and qualitatively. However, those existing methods are developed around human-vision, i.e., they are designed to minimize the noise effect that can be perceived by human eyes. In this paper, we introduce an application-guided denoising framework, which focuses on denoising for the following neural networks. In our experiments, we apply the proposed framework to different datasets, models, and use cases. Experimental results show that our proposed framework can achieve a better result than human-vision denoising network.