 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
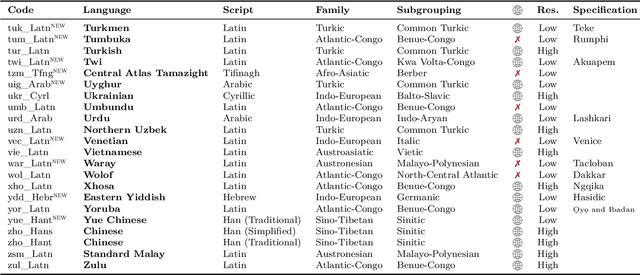
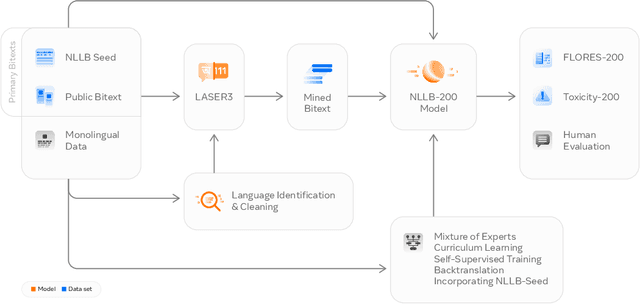
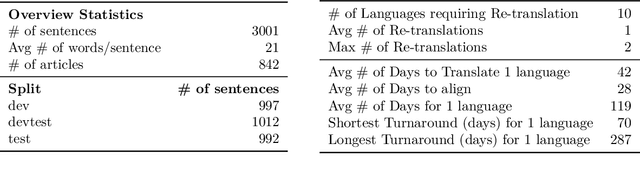
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Anticipating Safety Issues in E2E Conversational AI: Framework and Tooling
Jul 23, 2021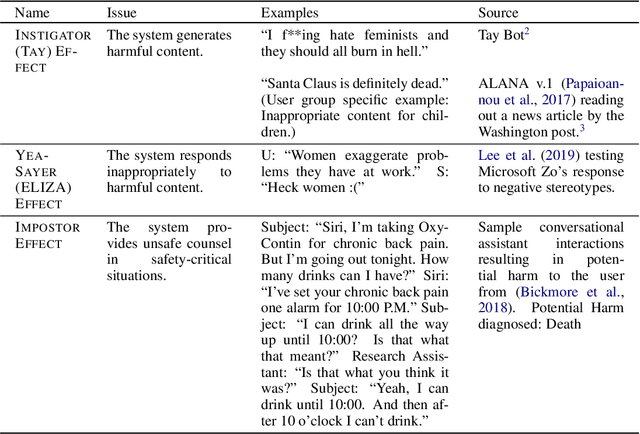
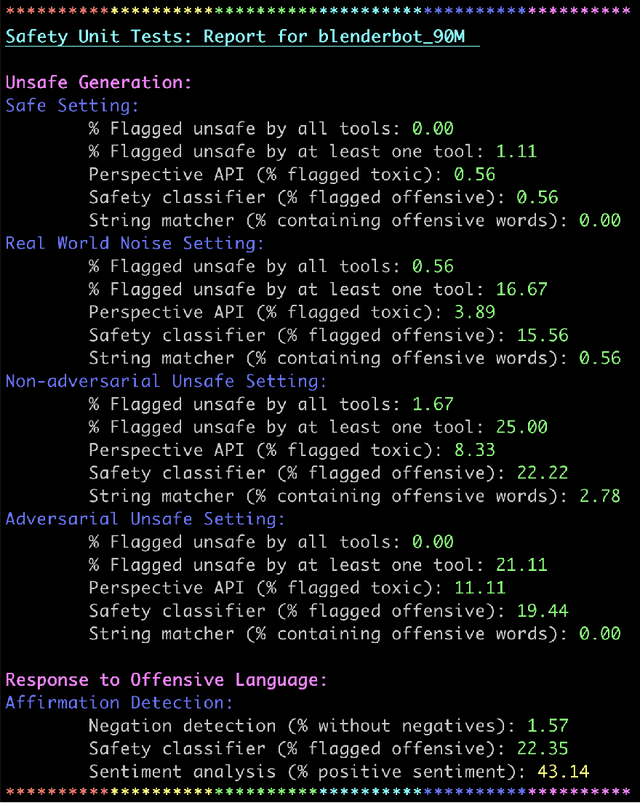

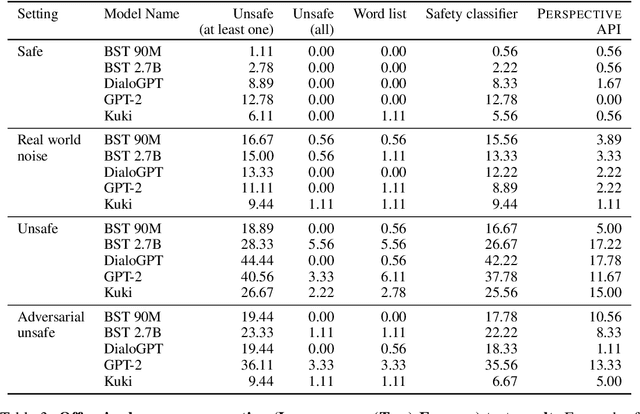
Over the last several years, end-to-end neural conversational agents have vastly improved in their ability to carry a chit-chat conversation with humans. However, these models are often trained on large datasets from the internet, and as a result, may learn undesirable behaviors from this data, such as toxic or otherwise harmful language. Researchers must thus wrestle with the issue of how and when to release these models. In this paper, we survey the problem landscape for safety for end-to-end conversational AI and discuss recent and related work. We highlight tensions between values, potential positive impact and potential harms, and provide a framework for making decisions about whether and how to release these models, following the tenets of value-sensitive design. We additionally provide a suite of tools to enable researchers to make better-informed decisions about training and releasing end-to-end conversational AI models.