 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign and Shine: Building High-Quality Sentence-Aligned Corpora for Multilingual Text Simplification
May 10, 2026Text simplification plays a crucial role in improving the accessibility and comprehensibility of written information for diverse audiences, including language learners and readers with limited literacy. Despite its importance, large-scale, high-quality datasets for training and evaluating text simplification models remain scarce for languages other than English. This paper reports an experimental study on the collection and processing of crowd-sourced simplification data from comparable corpora to construct a corpus suitable for both training and testing text simplification systems across multiple languages (Catalan, English, French, Italian and Spanish). We report mechanisms for sentence-level alignment from document-level data. The resulting dataset of the aligned sentence pairs is publicly available.
Can LLM Reasoning Be Trusted? A Comparative Study: Using Human Benchmarking on Statistical Tasks
Jan 20, 2026This paper investigates the ability of large language models (LLMs) to solve statistical tasks, as well as their capacity to assess the quality of reasoning. While state-of-the-art LLMs have demonstrated remarkable performance in a range of NLP tasks, their competence in addressing even moderately complex statistical challenges is not well understood. We have fine-tuned selected open-source LLMs on a specially developed dataset to enhance their statistical reasoning capabilities, and compared their performance with the human scores used as a benchmark. Our results show that the fine-tuned models achieve better performance on advanced statistical tasks on the level comparable to a statistics student. Fine-tuning demonstrates architecture-dependent improvements, with some models showing significant performance gains, indicating clear potential for deployment in educational technology and statistical analysis assistance systems. We also show that LLMs themselves can be far better judges of the answers quality (including explanation and reasoning assessment) in comparison to traditional metrics, such as BLEU or BertScore. This self-evaluation capability enables scalable automated assessment for statistical education platforms and quality assurance in automated analysis tools. Potential applications also include validation tools for research methodology in academic and industry settings, and quality control mechanisms for data analysis workflows.
Almost Clinical: Linguistic properties of synthetic electronic health records
Jan 03, 2026This study evaluates the linguistic and clinical suitability of synthetic electronic health records (EHRs) in the field of mental health. First, we describe the rationale and the methodology for creating the synthetic corpus. Second, we assess agency, modality, and information flow across four clinical genres (Assessments, Correspondence, Referrals and Care plans) to understand how LLMs grammatically construct medical authority and patient agency through linguistic choices. While LLMs produce coherent, terminology-appropriate texts that approximate clinical practice, systematic divergences remain, including registerial shifts, insufficient clinical specificity, and inaccuracies in medication use and diagnostic procedures.
Reading Between the Lines: A dataset and a study on why some texts are tougher than others
Jan 03, 2025Our research aims at better understanding what makes a text difficult to read for specific audiences with intellectual disabilities, more specifically, people who have limitations in cognitive functioning, such as reading and understanding skills, an IQ below 70, and challenges in conceptual domains. We introduce a scheme for the annotation of difficulties which is based on empirical research in psychology as well as on research in translation studies. The paper describes the annotated dataset, primarily derived from the parallel texts (standard English and Easy to Read English translations) made available online. we fine-tuned four different pre-trained transformer models to perform the task of multiclass classification to predict the strategies required for simplification. We also investigate the possibility to interpret the decisions of this language model when it is aimed at predicting the difficulty of sentences. The resources are available from https://github.com/Nouran-Khallaf/why-tough
Controlling Out-of-Domain Gaps in LLMs for Genre Classification and Generated Text Detection
Dec 29, 2024



This study demonstrates that the modern generation of Large Language Models (LLMs, such as GPT-4) suffers from the same out-of-domain (OOD) performance gap observed in prior research on pre-trained Language Models (PLMs, such as BERT). We demonstrate this across two non-topical classification tasks: 1) genre classification and 2) generated text detection. Our results show that when demonstration examples for In-Context Learning (ICL) come from one domain (e.g., travel) and the system is tested on another domain (e.g., history), classification performance declines significantly. To address this, we introduce a method that controls which predictive indicators are used and which are excluded during classification. For the two tasks studied here, this ensures that topical features are omitted, while the model is guided to focus on stylistic rather than content-based attributes. This approach reduces the OOD gap by up to 20 percentage points in a few-shot setup. Straightforward Chain-of-Thought (CoT) methods, used as the baseline, prove insufficient, while our approach consistently enhances domain transfer performance.
BERT Goes Off-Topic: Investigating the Domain Transfer Challenge using Genre Classification
Nov 27, 2023While performance of many text classification tasks has been recently improved due to Pre-trained Language Models (PLMs), in this paper we show that they still suffer from a performance gap when the underlying distribution of topics changes. For example, a genre classifier trained on \textit{political} topics often fails when tested on documents about \textit{sport} or \textit{medicine}. In this work, we quantify this phenomenon empirically with a large corpus and a large set of topics. Consequently, we verify that domain transfer remains challenging both for classic PLMs, such as BERT, and for modern large models, such as GPT-3. We also suggest and successfully test a possible remedy: after augmenting the training dataset with topically-controlled synthetic texts, the F1 score improves by up to 50\% for some topics, nearing on-topic training results, while others show little to no improvement. While our empirical results focus on genre classification, our methodology is applicable to other classification tasks such as gender, authorship, or sentiment classification. The code and data to replicate the experiments are available at https://github.com/dminus1/genre
Beyond Images: An Integrative Multi-modal Approach to Chest X-Ray Report Generation
Nov 18, 2023
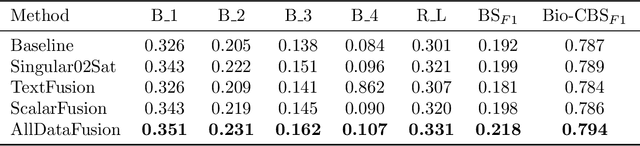
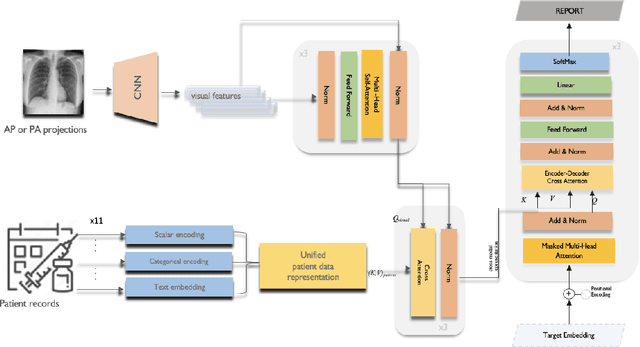
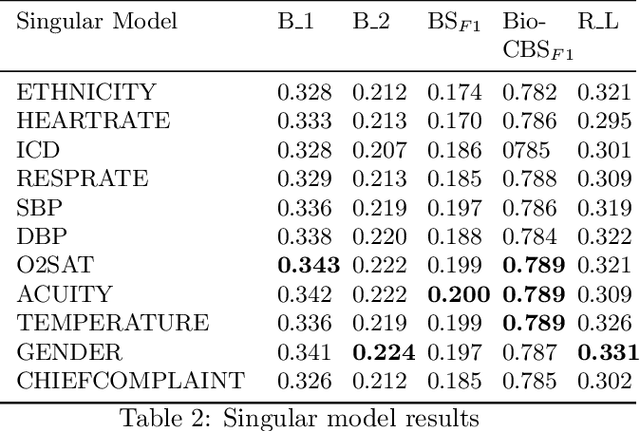
Image-to-text radiology report generation aims to automatically produce radiology reports that describe the findings in medical images. Most existing methods focus solely on the image data, disregarding the other patient information accessible to radiologists. In this paper, we present a novel multi-modal deep neural network framework for generating chest X-rays reports by integrating structured patient data, such as vital signs and symptoms, alongside unstructured clinical notes.We introduce a conditioned cross-multi-head attention module to fuse these heterogeneous data modalities, bridging the semantic gap between visual and textual data. Experiments demonstrate substantial improvements from using additional modalities compared to relying on images alone. Notably, our model achieves the highest reported performance on the ROUGE-L metric compared to relevant state-of-the-art models in the literature. Furthermore, we employed both human evaluation and clinical semantic similarity measurement alongside word-overlap metrics to improve the depth of quantitative analysis. A human evaluation, conducted by a board-certified radiologist, confirms the model's accuracy in identifying high-level findings, however, it also highlights that more improvement is needed to capture nuanced details and clinical context.
Syntactic Knowledge via Graph Attention with BERT in Machine Translation
May 22, 2023Although the Transformer model can effectively acquire context features via a self-attention mechanism, deeper syntactic knowledge is still not effectively modeled. To alleviate the above problem, we propose Syntactic knowledge via Graph attention with BERT (SGB) in Machine Translation (MT) scenarios. Graph Attention Network (GAT) and BERT jointly represent syntactic dependency feature as explicit knowledge of the source language to enrich source language representations and guide target language generation. Our experiments use gold syntax-annotation sentences and Quality Estimation (QE) model to obtain interpretability of translation quality improvement regarding syntactic knowledge without being limited to a BLEU score. Experiments show that the proposed SGB engines improve translation quality across the three MT tasks without sacrificing BLEU scores. We investigate what length of source sentences benefits the most and what dependencies are better identified by the SGB engines. We also find that learning of specific dependency relations by GAT can be reflected in the translation quality containing such relations and that syntax on the graph leads to new modeling of syntactic aspects of source sentences in the middle and bottom layers of BERT.
GATology for Linguistics: What Syntactic Dependencies It Knows
May 22, 2023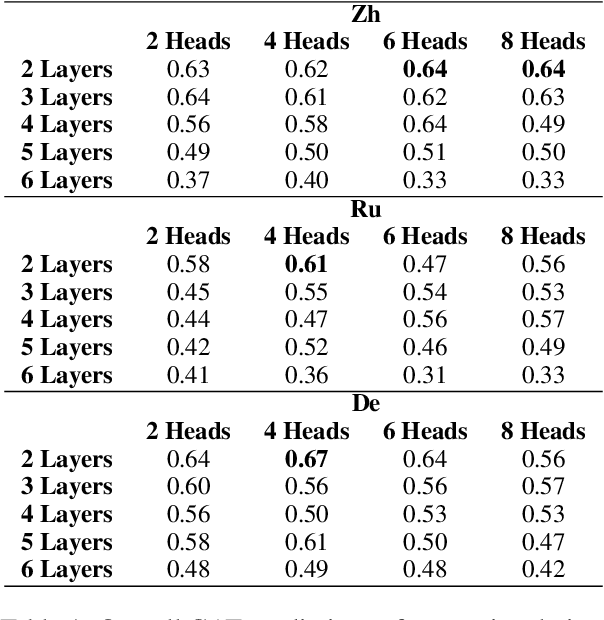
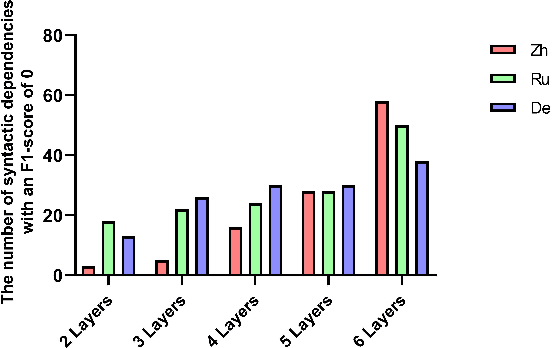
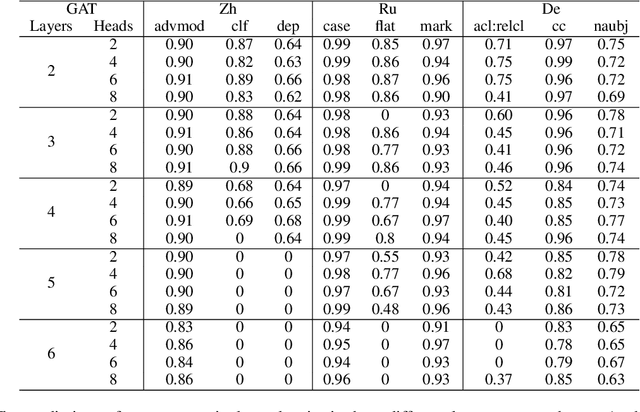
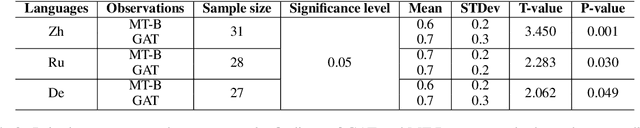
Graph Attention Network (GAT) is a graph neural network which is one of the strategies for modeling and representing explicit syntactic knowledge and can work with pre-trained models, such as BERT, in downstream tasks. Currently, there is still a lack of investigation into how GAT learns syntactic knowledge from the perspective of model structure. As one of the strategies for modeling explicit syntactic knowledge, GAT and BERT have never been applied and discussed in Machine Translation (MT) scenarios. We design a dependency relation prediction task to study how GAT learns syntactic knowledge of three languages as a function of the number of attention heads and layers. We also use a paired t-test and F1-score to clarify the differences in syntactic dependency prediction between GAT and BERT fine-tuned by the MT task (MT-B). The experiments show that better performance can be achieved by appropriately increasing the number of attention heads with two GAT layers. With more than two layers, learning suffers. Moreover, GAT is more competitive in training speed and syntactic dependency prediction than MT-B, which may reveal a better incorporation of modeling explicit syntactic knowledge and the possibility of combining GAT and BERT in the MT tasks.
Estimating Confidence of Predictions of Individual Classifiers and Their Ensembles for the Genre Classification Task
Jun 15, 2022
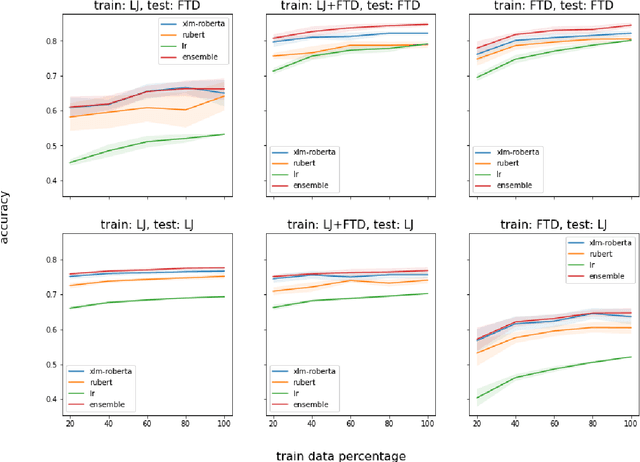
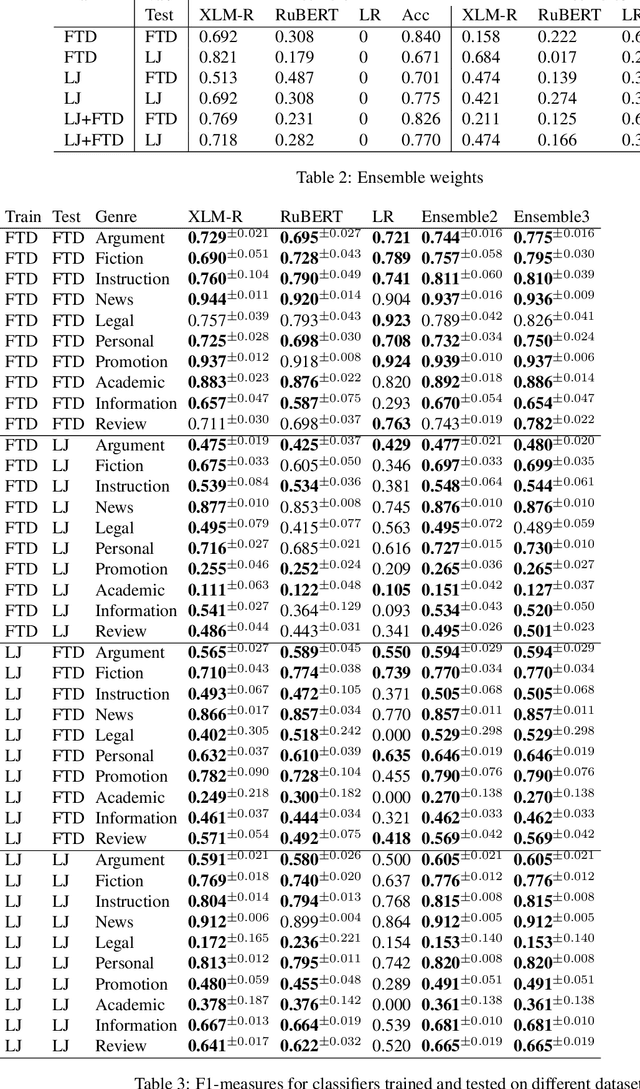
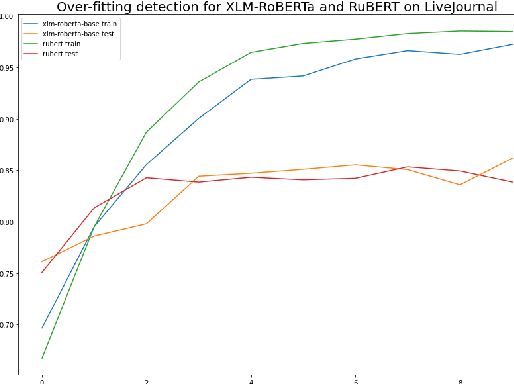
Genre identification is a subclass of non-topical text classification. The main difference between this task and topical classification is that genres, unlike topics, usually do not correspond to simple keywords, and thus they need to be defined in terms of their functions in communication. Neural models based on pre-trained transformers, such as BERT or XLM-RoBERTa, demonstrate SOTA results in many NLP tasks, including non-topical classification. However, in many cases, their downstream application to very large corpora, such as those extracted from social media, can lead to unreliable results because of dataset shifts, when some raw texts do not match the profile of the training set. To mitigate this problem, we experiment with individual models as well as with their ensembles. To evaluate the robustness of all models we use a prediction confidence metric, which estimates the reliability of a prediction in the absence of a gold standard label. We can evaluate robustness via the confidence gap between the correctly classified texts and the misclassified ones on a labeled test corpus, higher gaps make it easier to improve our confidence that our classifier made the right decision. Our results show that for all of the classifiers tested in this study, there is a confidence gap, but for the ensembles, the gap is bigger, meaning that ensembles are more robust than their individual models.