 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Images: An Integrative Multi-modal Approach to Chest X-Ray Report Generation
Nov 18, 2023
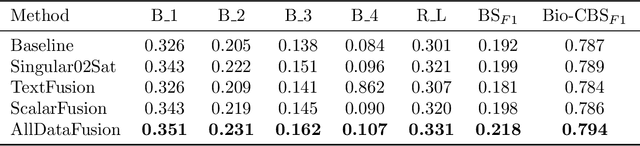
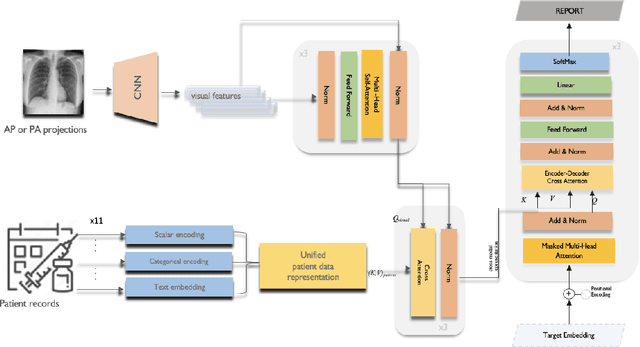
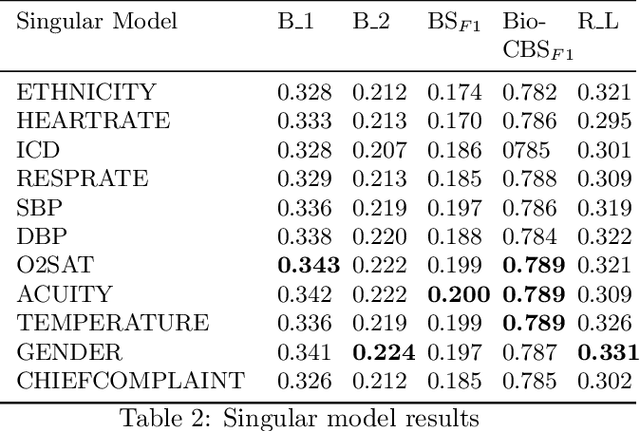
Image-to-text radiology report generation aims to automatically produce radiology reports that describe the findings in medical images. Most existing methods focus solely on the image data, disregarding the other patient information accessible to radiologists. In this paper, we present a novel multi-modal deep neural network framework for generating chest X-rays reports by integrating structured patient data, such as vital signs and symptoms, alongside unstructured clinical notes.We introduce a conditioned cross-multi-head attention module to fuse these heterogeneous data modalities, bridging the semantic gap between visual and textual data. Experiments demonstrate substantial improvements from using additional modalities compared to relying on images alone. Notably, our model achieves the highest reported performance on the ROUGE-L metric compared to relevant state-of-the-art models in the literature. Furthermore, we employed both human evaluation and clinical semantic similarity measurement alongside word-overlap metrics to improve the depth of quantitative analysis. A human evaluation, conducted by a board-certified radiologist, confirms the model's accuracy in identifying high-level findings, however, it also highlights that more improvement is needed to capture nuanced details and clinical context.
Radiology Report Generation Using Transformers Conditioned with Non-imaging Data
Nov 18, 2023Medical image interpretation is central to most clinical applications such as disease diagnosis, treatment planning, and prognostication. In clinical practice, radiologists examine medical images and manually compile their findings into reports, which can be a time-consuming process. Automated approaches to radiology report generation, therefore, can reduce radiologist workload and improve efficiency in the clinical pathway. While recent deep-learning approaches for automated report generation from medical images have seen some success, most studies have relied on image-derived features alone, ignoring non-imaging patient data. Although a few studies have included the word-level contexts along with the image, the use of patient demographics is still unexplored. This paper proposes a novel multi-modal transformer network that integrates chest x-ray (CXR) images and associated patient demographic information, to synthesise patient-specific radiology reports. The proposed network uses a convolutional neural network to extract visual features from CXRs and a transformer-based encoder-decoder network that combines the visual features with semantic text embeddings of patient demographic information, to synthesise full-text radiology reports. Data from two public databases were used to train and evaluate the proposed approach. CXRs and reports were extracted from the MIMIC-CXR database and combined with corresponding patients' data MIMIC-IV. Based on the evaluation metrics used including patient demographic information was found to improve the quality of reports generated using the proposed approach, relative to a baseline network trained using CXRs alone. The proposed approach shows potential for enhancing radiology report generation by leveraging rich patient metadata and combining semantic text embeddings derived thereof, with medical image-derived visual features.