 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Images: An Integrative Multi-modal Approach to Chest X-Ray Report Generation
Paper and Code
Nov 18, 2023
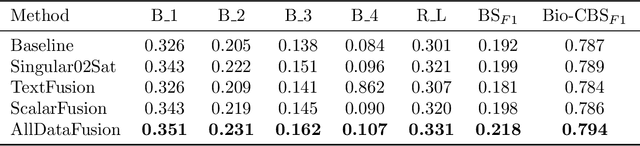
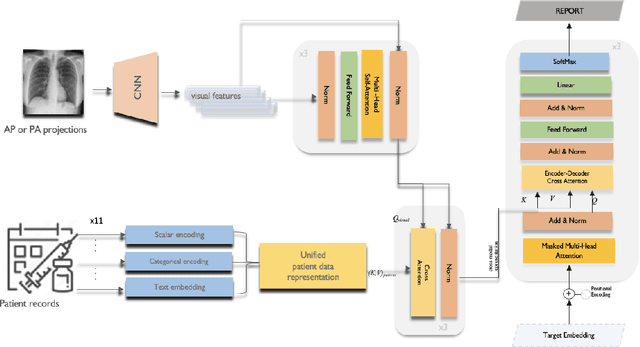
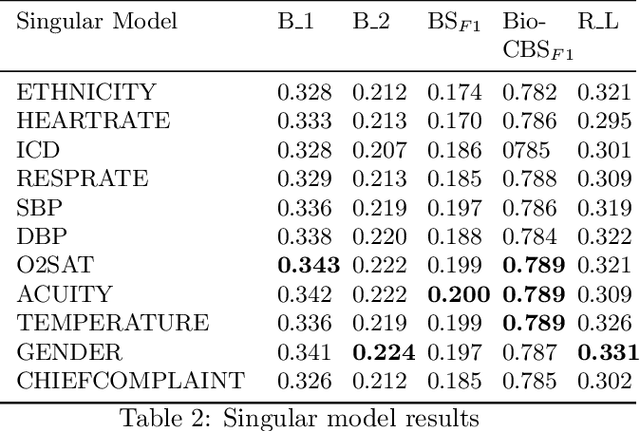
Image-to-text radiology report generation aims to automatically produce radiology reports that describe the findings in medical images. Most existing methods focus solely on the image data, disregarding the other patient information accessible to radiologists. In this paper, we present a novel multi-modal deep neural network framework for generating chest X-rays reports by integrating structured patient data, such as vital signs and symptoms, alongside unstructured clinical notes.We introduce a conditioned cross-multi-head attention module to fuse these heterogeneous data modalities, bridging the semantic gap between visual and textual data. Experiments demonstrate substantial improvements from using additional modalities compared to relying on images alone. Notably, our model achieves the highest reported performance on the ROUGE-L metric compared to relevant state-of-the-art models in the literature. Furthermore, we employed both human evaluation and clinical semantic similarity measurement alongside word-overlap metrics to improve the depth of quantitative analysis. A human evaluation, conducted by a board-certified radiologist, confirms the model's accuracy in identifying high-level findings, however, it also highlights that more improvement is needed to capture nuanced details and clinical context.