 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperiments with adversarial attacks on text genres
Paper and Code
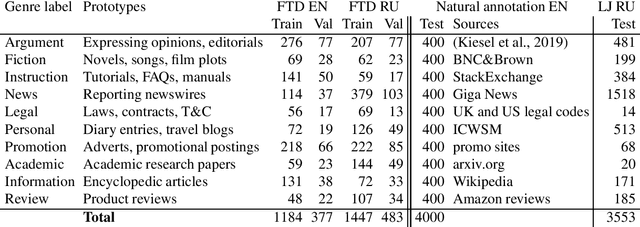



Neural models based on pre-trained transformers, such as BERT or XLM-RoBERTa, demonstrate SOTA results in many NLP tasks, including non-topical classification, such as genre identification. However, often these approaches exhibit low reliability to minor alterations of the test texts. A related probelm concerns topical biases in the training corpus, for example, the prevalence of words on a specific topic in a specific genre can trick the genre classifier to recognise any text on this topic in this genre. In order to mitigate the reliability problem, this paper investigates techniques for attacking genre classifiers to understand the limitations of the transformer models and to improve their performance. While simple text attacks, such as those based on word replacement using keywords extracted by tf-idf, are not capable of deceiving powerful models like XLM-RoBERTa, we show that embedding-based algorithms which can replace some of the most ``significant'' words with words similar to them, for example, TextFooler, have the ability to influence model predictions in a significant proportion of cases.