 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign and Shine: Building High-Quality Sentence-Aligned Corpora for Multilingual Text Simplification
May 10, 2026Text simplification plays a crucial role in improving the accessibility and comprehensibility of written information for diverse audiences, including language learners and readers with limited literacy. Despite its importance, large-scale, high-quality datasets for training and evaluating text simplification models remain scarce for languages other than English. This paper reports an experimental study on the collection and processing of crowd-sourced simplification data from comparable corpora to construct a corpus suitable for both training and testing text simplification systems across multiple languages (Catalan, English, French, Italian and Spanish). We report mechanisms for sentence-level alignment from document-level data. The resulting dataset of the aligned sentence pairs is publicly available.
A Multilingual Human Annotated Corpus of Original and Easy-to-Read Texts to Support Access to Democratic Participatory Processes
Mar 05, 2026Being able to understand information is a key factor for a self-determined life and society. It is also very important for participating in democratic processes. The study of automatic text simplification is often limited by the availability of high quality material for the training and evaluation on automatic simplifiers. This is true for English, but more so for less resourced languages like Spanish, Catalan and Italian. In order to fill this gap, we present a corpus of original texts for these 3 languages, with high quality simplification produced by human experts in text simplification. It was developed within the iDEM project to assess the impact of Easy-to-Read (E2R) language for democratic participation. The original texts were compiled from domains related to this topic. The corpus includes different text types, selected based on relevance, copyright availability, and ethical standards. All texts were simplified to E2R level. The corpus is particularity valuable because it includes the first annotated corpus of its kind for the Catalan language. It also represents a noteworthy contribution for Spanish and Italian, offering high-quality, human-annotated language resources that are rarely available in these domains. The corpus will be made freely accessible to the public.
Reading Between the Lines: A dataset and a study on why some texts are tougher than others
Jan 03, 2025Our research aims at better understanding what makes a text difficult to read for specific audiences with intellectual disabilities, more specifically, people who have limitations in cognitive functioning, such as reading and understanding skills, an IQ below 70, and challenges in conceptual domains. We introduce a scheme for the annotation of difficulties which is based on empirical research in psychology as well as on research in translation studies. The paper describes the annotated dataset, primarily derived from the parallel texts (standard English and Easy to Read English translations) made available online. we fine-tuned four different pre-trained transformer models to perform the task of multiclass classification to predict the strategies required for simplification. We also investigate the possibility to interpret the decisions of this language model when it is aimed at predicting the difficulty of sentences. The resources are available from https://github.com/Nouran-Khallaf/why-tough
Towards Arabic Sentence Simplification via Classification and Generative Approaches
Apr 20, 2022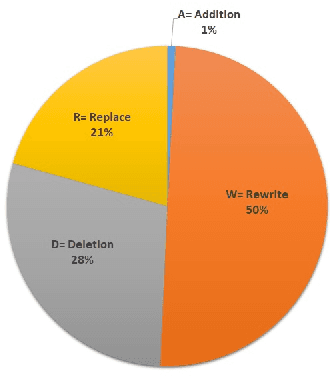

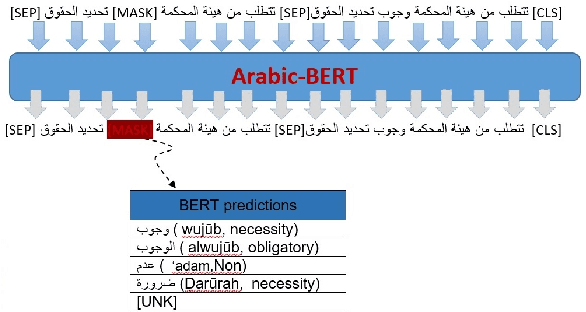
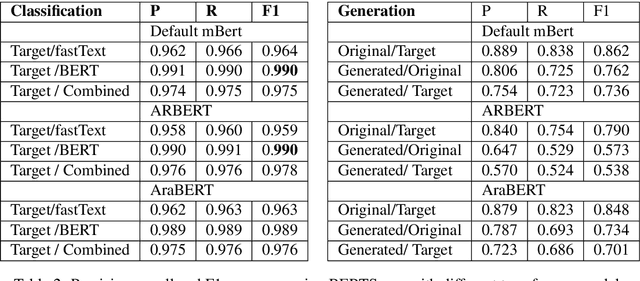
This paper presents an attempt to build a Modern Standard Arabic (MSA) sentence-level simplification system. We experimented with sentence simplification using two approaches: (i) a classification approach leading to lexical simplification pipelines which use Arabic-BERT, a pre-trained contextualised model, as well as a model of fastText word embeddings; and (ii) a generative approach, a Seq2Seq technique by applying a multilingual Text-to-Text Transfer Transformer mT5. We developed our training corpus by aligning the original and simplified sentences from the internationally acclaimed Arabic novel "Saaq al-Bambuu". We evaluate effectiveness of these methods by comparing the generated simple sentences to the target simple sentences using the BERTScore evaluation metric. The simple sentences produced by the mT5 model achieve P 0.72, R 0.68 and F-1 0.70 via BERTScore, while, combining Arabic-BERT and fastText achieves P 0.97, R 0.97 and F-1 0.97. In addition, we report a manual error analysis for these experiments. \url{https://github.com/Nouran-Khallaf/Lexical_Simplification}
Automatic Difficulty Classification of Arabic Sentences
Mar 07, 2021
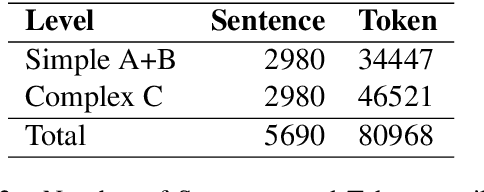

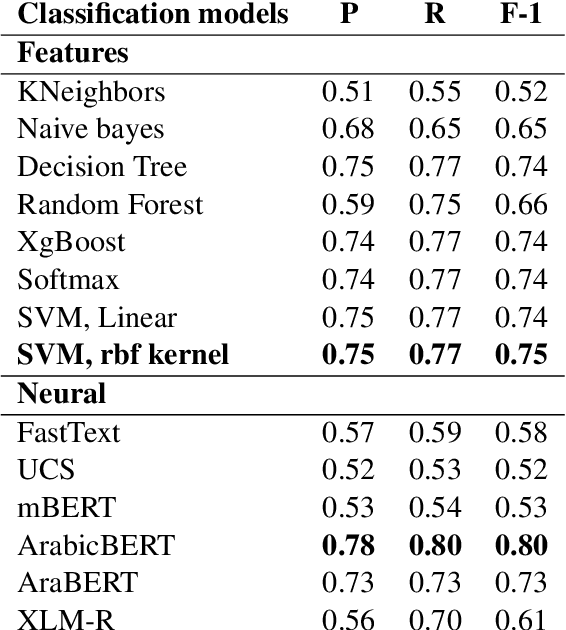
In this paper, we present a Modern Standard Arabic (MSA) Sentence difficulty classifier, which predicts the difficulty of sentences for language learners using either the CEFR proficiency levels or the binary classification as simple or complex. We compare the use of sentence embeddings of different kinds (fastText, mBERT , XLM-R and Arabic-BERT), as well as traditional language features such as POS tags, dependency trees, readability scores and frequency lists for language learners. Our best results have been achieved using fined-tuned Arabic-BERT. The accuracy of our 3-way CEFR classification is F-1 of 0.80 and 0.75 for Arabic-Bert and XLM-R classification respectively and 0.71 Spearman correlation for regression. Our binary difficulty classifier reaches F-1 0.94 and F-1 0.98 for sentence-pair semantic similarity classifier.
* Accepted at WANLP 2021