 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Difficulty Classification of Arabic Sentences
Paper and Code
Mar 07, 2021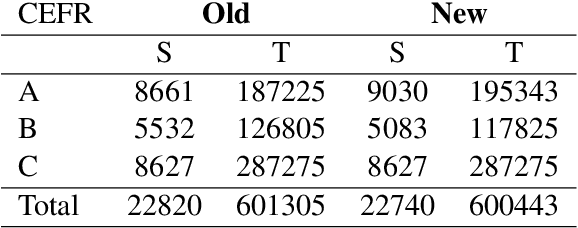
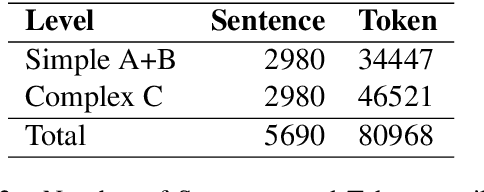

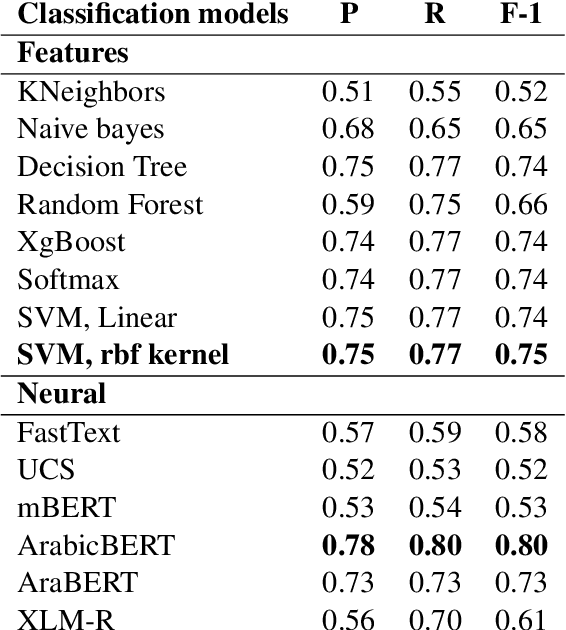
In this paper, we present a Modern Standard Arabic (MSA) Sentence difficulty classifier, which predicts the difficulty of sentences for language learners using either the CEFR proficiency levels or the binary classification as simple or complex. We compare the use of sentence embeddings of different kinds (fastText, mBERT , XLM-R and Arabic-BERT), as well as traditional language features such as POS tags, dependency trees, readability scores and frequency lists for language learners. Our best results have been achieved using fined-tuned Arabic-BERT. The accuracy of our 3-way CEFR classification is F-1 of 0.80 and 0.75 for Arabic-Bert and XLM-R classification respectively and 0.71 Spearman correlation for regression. Our binary difficulty classifier reaches F-1 0.94 and F-1 0.98 for sentence-pair semantic similarity classifier.