 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Confidence of Predictions of Individual Classifiers and Their Ensembles for the Genre Classification Task
Paper and Code
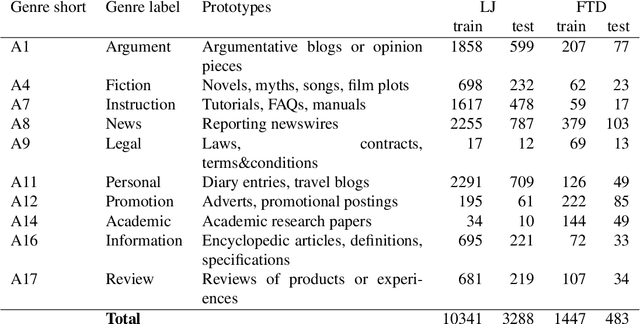
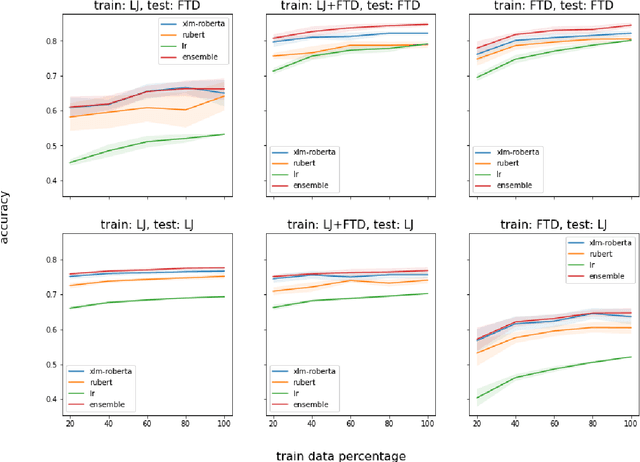
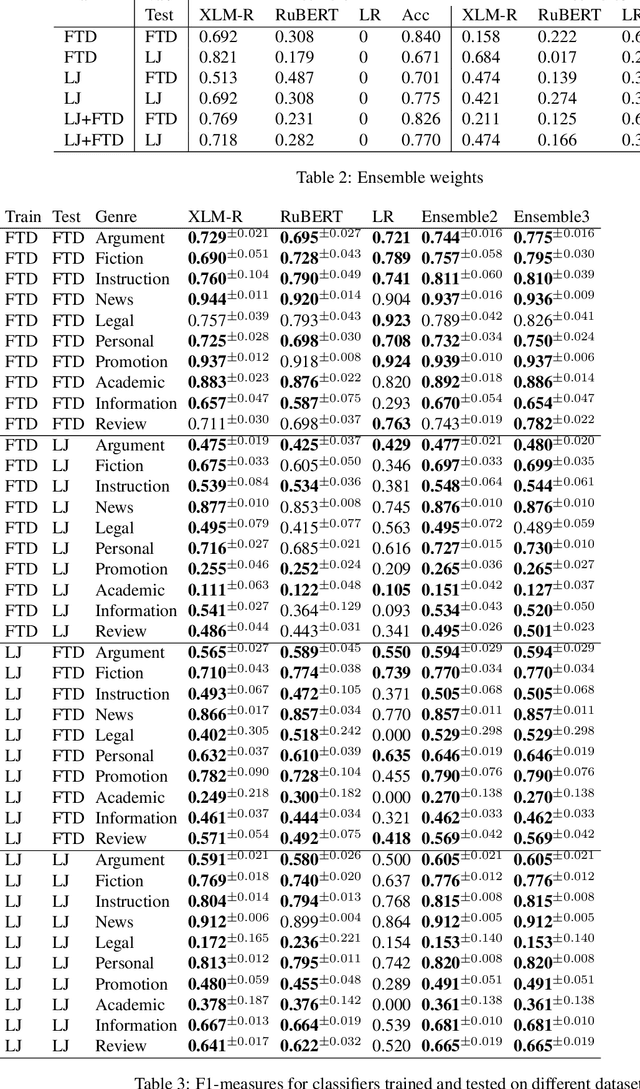
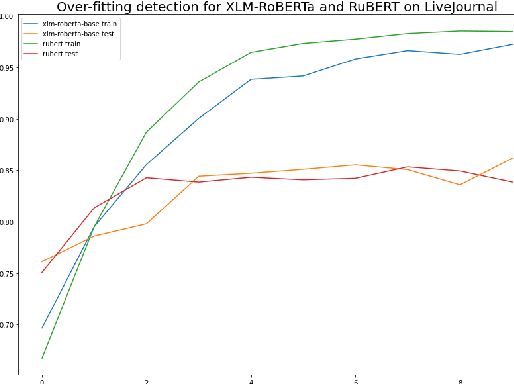
Genre identification is a subclass of non-topical text classification. The main difference between this task and topical classification is that genres, unlike topics, usually do not correspond to simple keywords, and thus they need to be defined in terms of their functions in communication. Neural models based on pre-trained transformers, such as BERT or XLM-RoBERTa, demonstrate SOTA results in many NLP tasks, including non-topical classification. However, in many cases, their downstream application to very large corpora, such as those extracted from social media, can lead to unreliable results because of dataset shifts, when some raw texts do not match the profile of the training set. To mitigate this problem, we experiment with individual models as well as with their ensembles. To evaluate the robustness of all models we use a prediction confidence metric, which estimates the reliability of a prediction in the absence of a gold standard label. We can evaluate robustness via the confidence gap between the correctly classified texts and the misclassified ones on a labeled test corpus, higher gaps make it easier to improve our confidence that our classifier made the right decision. Our results show that for all of the classifiers tested in this study, there is a confidence gap, but for the ensembles, the gap is bigger, meaning that ensembles are more robust than their individual models.