 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATology for Linguistics: What Syntactic Dependencies It Knows
Paper and Code
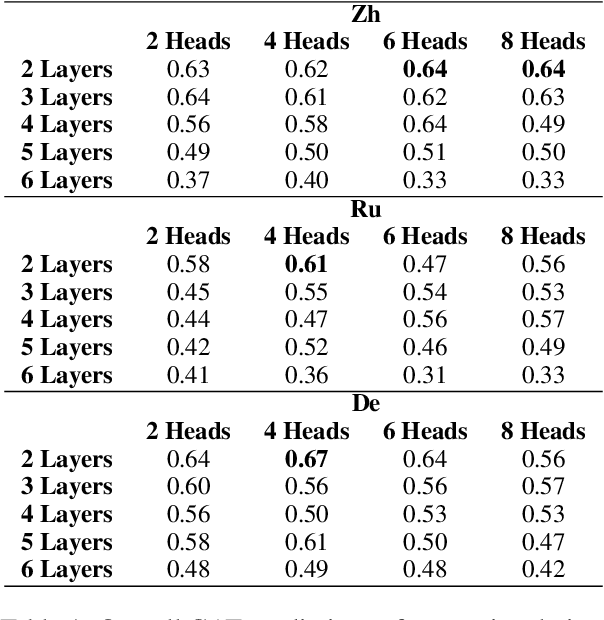
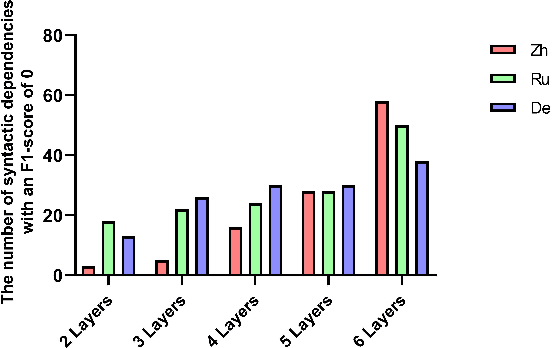
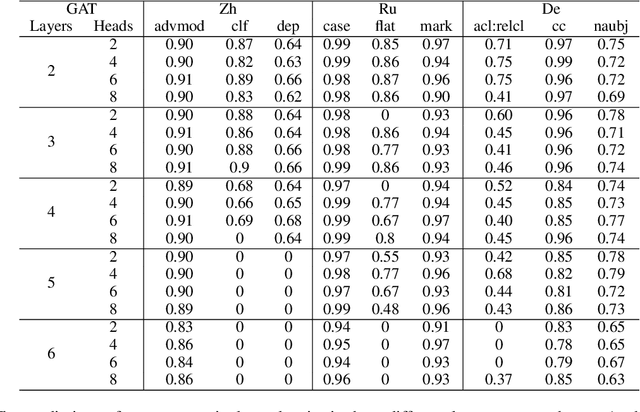
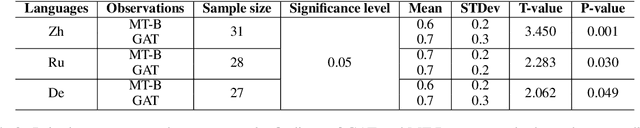
Graph Attention Network (GAT) is a graph neural network which is one of the strategies for modeling and representing explicit syntactic knowledge and can work with pre-trained models, such as BERT, in downstream tasks. Currently, there is still a lack of investigation into how GAT learns syntactic knowledge from the perspective of model structure. As one of the strategies for modeling explicit syntactic knowledge, GAT and BERT have never been applied and discussed in Machine Translation (MT) scenarios. We design a dependency relation prediction task to study how GAT learns syntactic knowledge of three languages as a function of the number of attention heads and layers. We also use a paired t-test and F1-score to clarify the differences in syntactic dependency prediction between GAT and BERT fine-tuned by the MT task (MT-B). The experiments show that better performance can be achieved by appropriately increasing the number of attention heads with two GAT layers. With more than two layers, learning suffers. Moreover, GAT is more competitive in training speed and syntactic dependency prediction than MT-B, which may reveal a better incorporation of modeling explicit syntactic knowledge and the possibility of combining GAT and BERT in the MT tasks.