 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-incremental Learning via Deep Model Consolidation
Mar 28, 2019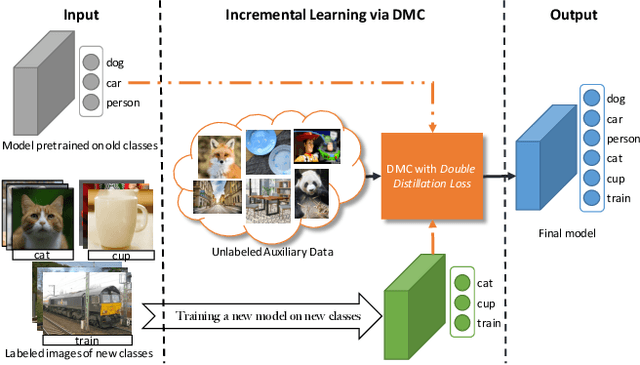

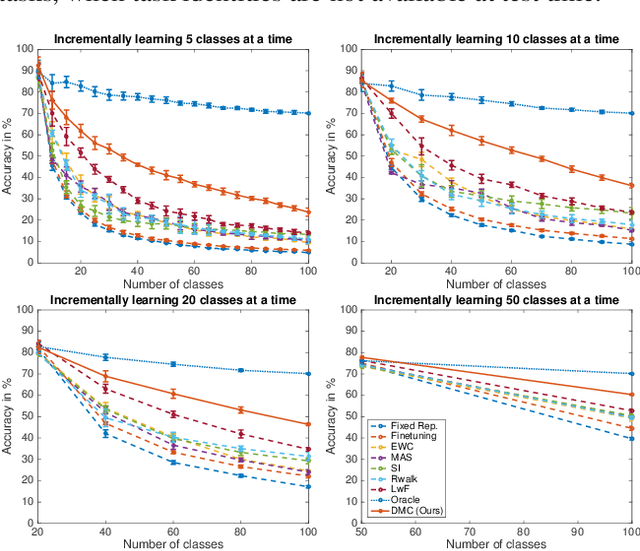
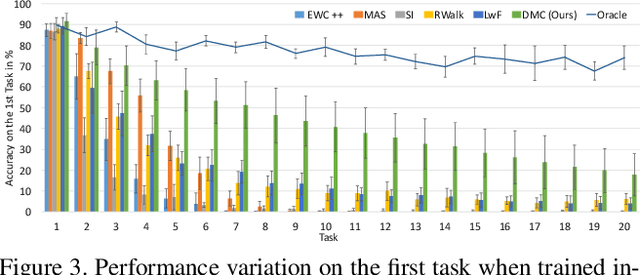
Deep neural networks (DNNs) often suffer from "catastrophic forgetting" during incremental learning (IL) --- an abrupt degradation of performance on the original set of classes when the training objective is adapted to a newly added set of classes. Existing IL approaches tend to produce a model that is biased towards either the old classes or new classes, unless with the help of exemplars of the old data. To address this issue, we propose a class-incremental learning paradigm called Deep Model Consolidation (DMC), which works well even when the original training data is not available. The idea is to first train a separate model only for the new classes, and then combine the two individual models trained on data of two distinct set of classes (old classes and new classes) via a novel dual distillation training objective. The two existing models are consolidated by exploiting publicly available unlabeled auxiliary data. This overcomes the potential difficulties due to unavailability of original training data. Compared to the state-of-the-art techniques, DMC demonstrates significantly better performance in CIFAR-100 image classification and PASCAL VOC 2007 object detection benchmarks in the single-headed IL setting.
Efficient Incremental Learning for Mobile Object Detection
Mar 26, 2019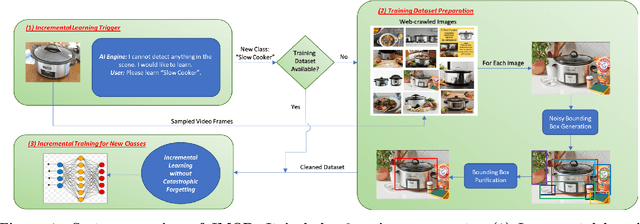
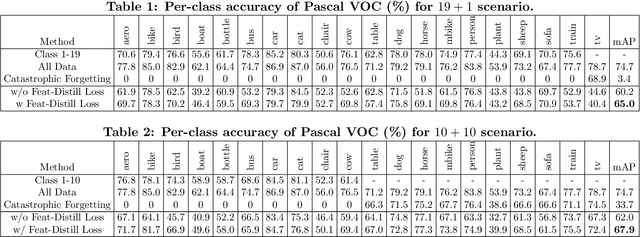
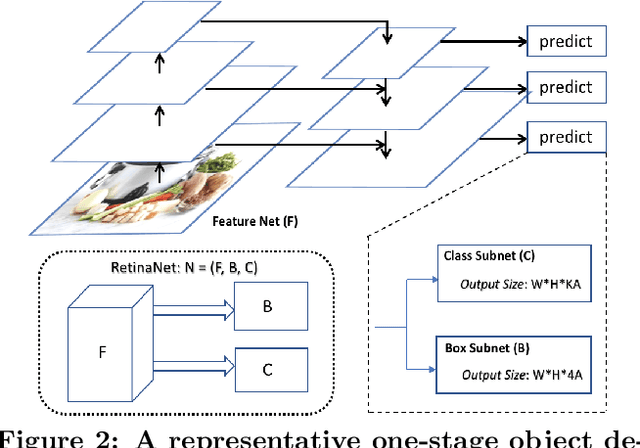
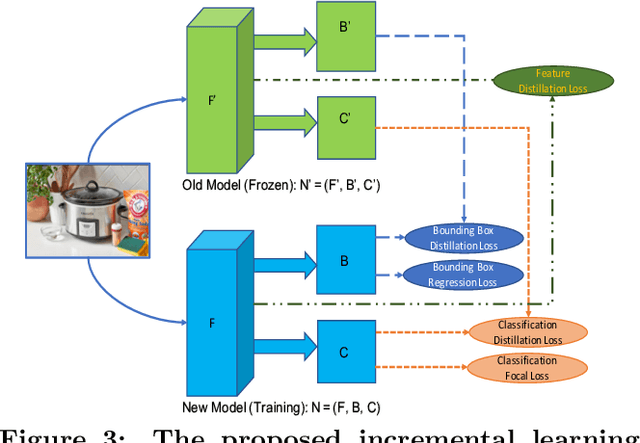
Object detection models shipped with camera-equipped mobile devices cannot cover the objects of interest for every user. Therefore, the incremental learning capability is a critical feature for a robust and personalized mobile object detection system that many applications would rely on. In this paper, we present an efficient yet practical system, IMOD, to incrementally train an existing object detection model such that it can detect new object classes without losing its capability to detect old classes. The key component of IMOD is a novel incremental learning algorithm that trains end-to-end for one-stage object detection deep models only using training data of new object classes. Specifically, to avoid catastrophic forgetting, the algorithm distills three types of knowledge from the old model to mimic the old model's behavior on object classification, bounding box regression and feature extraction. In addition, since the training data for the new classes may not be available, a real-time dataset construction pipeline is designed to collect training images on-the-fly and automatically label the images with both category and bounding box annotations. We have implemented IMOD under both mobile-cloud and mobile-only setups. Experiment results show that the proposed system can learn to detect a new object class in just a few minutes, including both dataset construction and model training. In comparison, traditional fine-tuning based method may take a few hours for training, and in most cases would also need a tedious and costly manual dataset labeling step.
Boundary-sensitive Network for Portrait Segmentation
Apr 09, 2018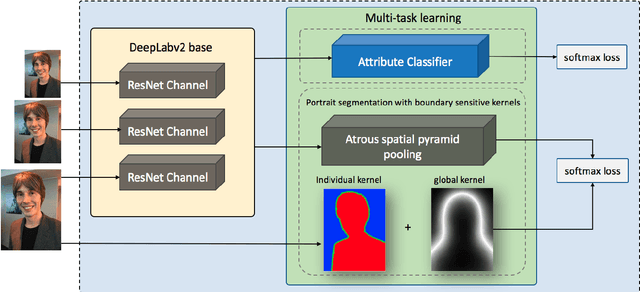



Compared to the general semantic segmentation problem, portrait segmentation has higher precision requirement on boundary area. However, this problem has not been well studied in previous works. In this paper, we propose a boundary-sensitive deep neural network (BSN) for portrait segmentation. BSN introduces three novel techniques. First, an individual boundary-sensitive kernel is proposed by dilating the contour line and assigning the boundary pixels with multi-class labels. Second, a global boundary-sensitive kernel is employed as a position sensitive prior to further constrain the overall shape of the segmentation map. Third, we train a boundary-sensitive attribute classifier jointly with the segmentation network to reinforce the network with semantic boundary shape information. We have evaluated BSN on the current largest public portrait segmentation dataset, i.e, the PFCN dataset, as well as the portrait images collected from other three popular image segmentation datasets: COCO, COCO-Stuff, and PASCAL VOC. Our method achieves the superior quantitative and qualitative performance over state-of-the-arts on all the datasets, especially on the boundary area.