 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-incremental Learning via Deep Model Consolidation
Paper and Code
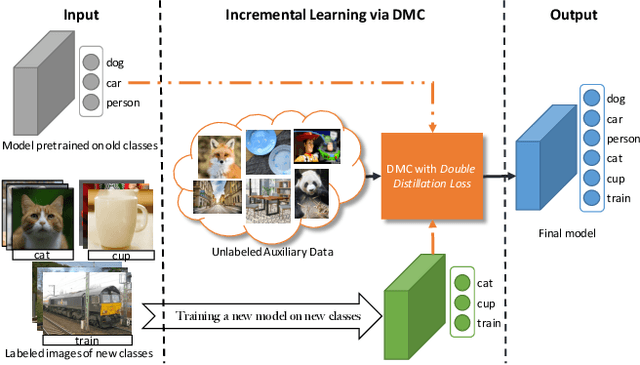

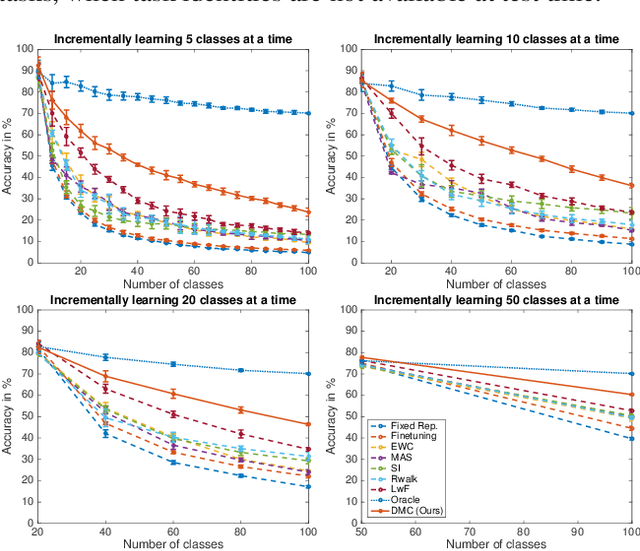
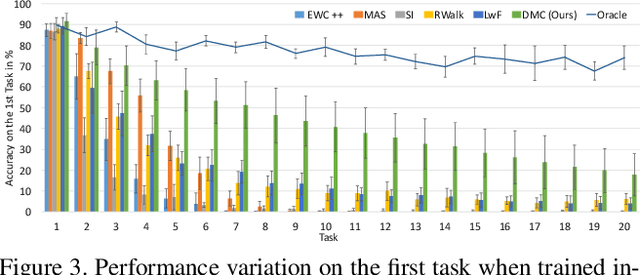
Deep neural networks (DNNs) often suffer from "catastrophic forgetting" during incremental learning (IL) --- an abrupt degradation of performance on the original set of classes when the training objective is adapted to a newly added set of classes. Existing IL approaches tend to produce a model that is biased towards either the old classes or new classes, unless with the help of exemplars of the old data. To address this issue, we propose a class-incremental learning paradigm called Deep Model Consolidation (DMC), which works well even when the original training data is not available. The idea is to first train a separate model only for the new classes, and then combine the two individual models trained on data of two distinct set of classes (old classes and new classes) via a novel dual distillation training objective. The two existing models are consolidated by exploiting publicly available unlabeled auxiliary data. This overcomes the potential difficulties due to unavailability of original training data. Compared to the state-of-the-art techniques, DMC demonstrates significantly better performance in CIFAR-100 image classification and PASCAL VOC 2007 object detection benchmarks in the single-headed IL setting.