 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClass-incremental Learning via Deep Model Consolidation
Mar 28, 2019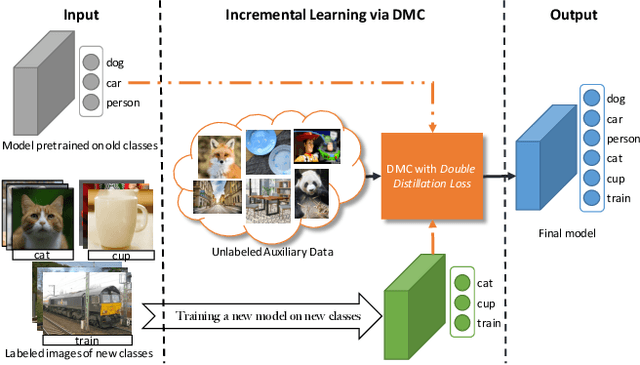

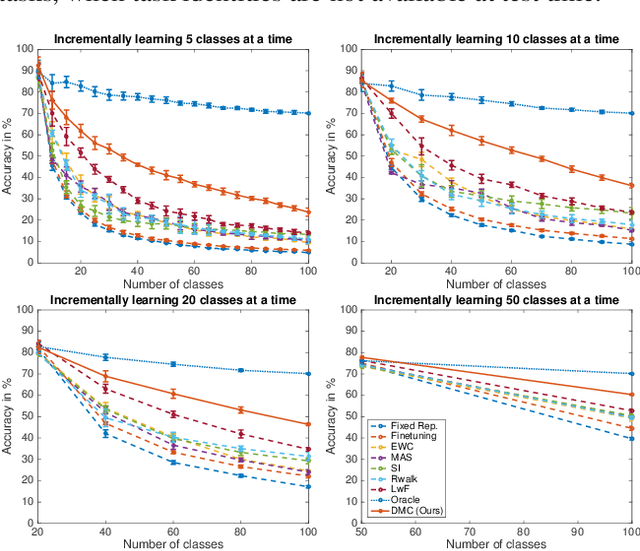
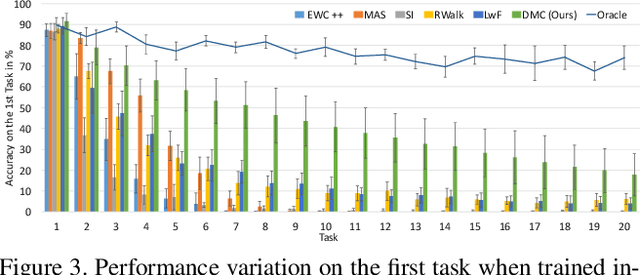
Deep neural networks (DNNs) often suffer from "catastrophic forgetting" during incremental learning (IL) --- an abrupt degradation of performance on the original set of classes when the training objective is adapted to a newly added set of classes. Existing IL approaches tend to produce a model that is biased towards either the old classes or new classes, unless with the help of exemplars of the old data. To address this issue, we propose a class-incremental learning paradigm called Deep Model Consolidation (DMC), which works well even when the original training data is not available. The idea is to first train a separate model only for the new classes, and then combine the two individual models trained on data of two distinct set of classes (old classes and new classes) via a novel dual distillation training objective. The two existing models are consolidated by exploiting publicly available unlabeled auxiliary data. This overcomes the potential difficulties due to unavailability of original training data. Compared to the state-of-the-art techniques, DMC demonstrates significantly better performance in CIFAR-100 image classification and PASCAL VOC 2007 object detection benchmarks in the single-headed IL setting.
Efficient Incremental Learning for Mobile Object Detection
Mar 26, 2019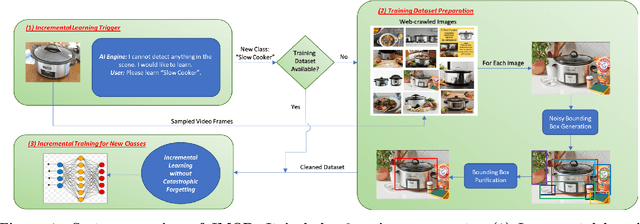
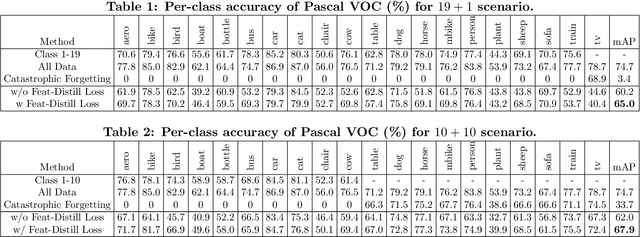
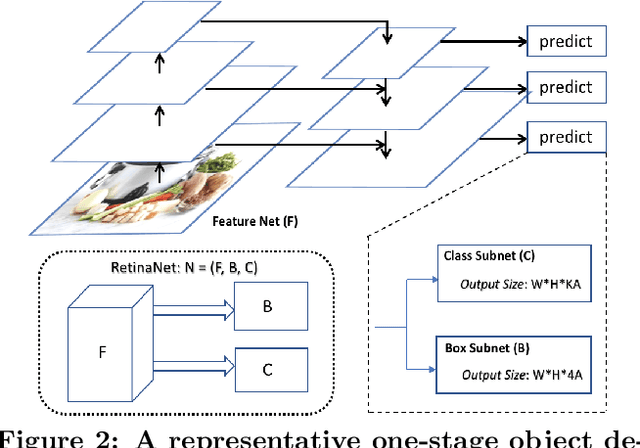
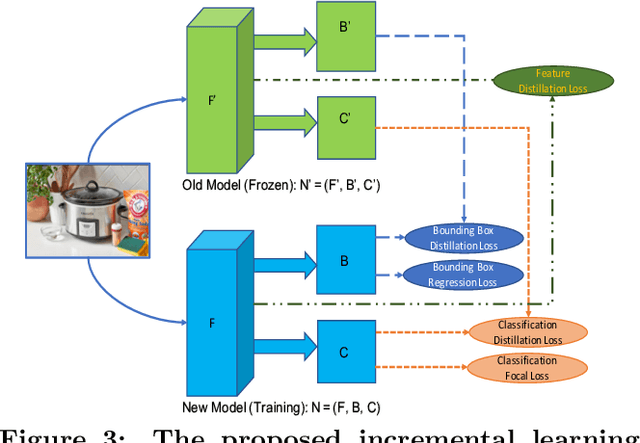
Object detection models shipped with camera-equipped mobile devices cannot cover the objects of interest for every user. Therefore, the incremental learning capability is a critical feature for a robust and personalized mobile object detection system that many applications would rely on. In this paper, we present an efficient yet practical system, IMOD, to incrementally train an existing object detection model such that it can detect new object classes without losing its capability to detect old classes. The key component of IMOD is a novel incremental learning algorithm that trains end-to-end for one-stage object detection deep models only using training data of new object classes. Specifically, to avoid catastrophic forgetting, the algorithm distills three types of knowledge from the old model to mimic the old model's behavior on object classification, bounding box regression and feature extraction. In addition, since the training data for the new classes may not be available, a real-time dataset construction pipeline is designed to collect training images on-the-fly and automatically label the images with both category and bounding box annotations. We have implemented IMOD under both mobile-cloud and mobile-only setups. Experiment results show that the proposed system can learn to detect a new object class in just a few minutes, including both dataset construction and model training. In comparison, traditional fine-tuning based method may take a few hours for training, and in most cases would also need a tedious and costly manual dataset labeling step.
Regularize, Expand and Compress: Multi-task based Lifelong Learning via NonExpansive AutoML
Mar 20, 2019

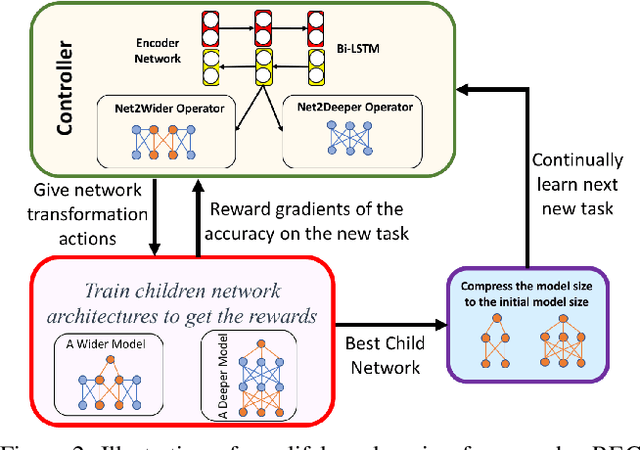
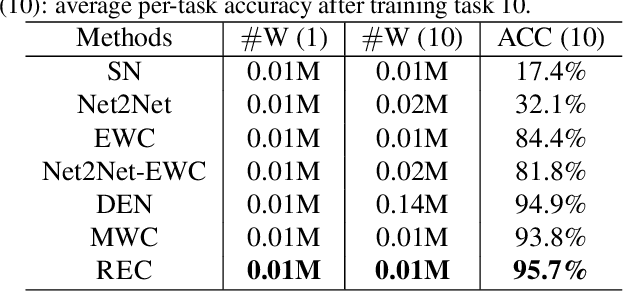
Lifelong learning, the problem of continual learning where tasks arrive in sequence, has been lately attracting more attention in the computer vision community. The aim of lifelong learning is to develop a system that can learn new tasks while maintaining the performance on the previously learned tasks. However, there are two obstacles for lifelong learning of deep neural networks: catastrophic forgetting and capacity limitation. To solve the above issues, inspired by the recent breakthroughs in automatically learning good neural network architectures, we develop a Multi-task based lifelong learning via nonexpansive AutoML framework termed Regularize, Expand and Compress (REC). REC is composed of three stages: 1) continually learns the sequential tasks without the learned tasks' data via a newly proposed multi-task weight consolidation (MWC) algorithm; 2) expands the network to help the lifelong learning with potentially improved model capability and performance by network-transformation based AutoML; 3) compresses the expanded model after learning every new task to maintain model efficiency and performance. The proposed MWC and REC algorithms achieve superior performance over other lifelong learning algorithms on four different datasets.
Generative Visual Dialogue System via Adaptive Reasoning and Weighted Likelihood Estimation
Feb 26, 2019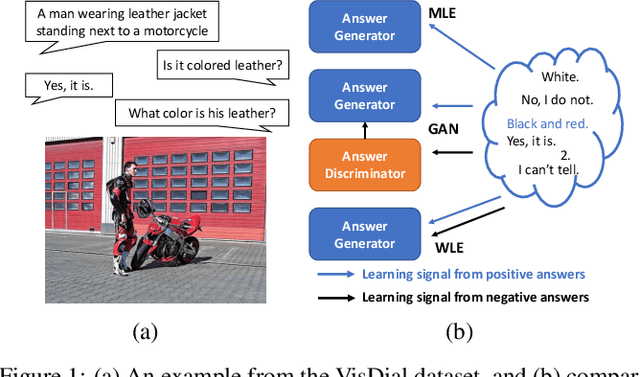
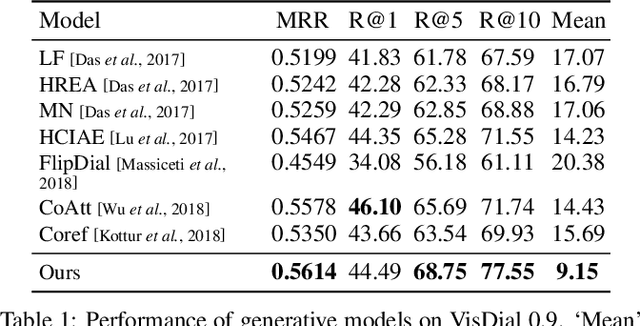
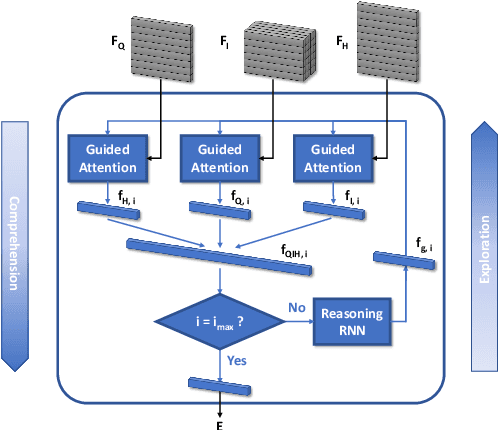
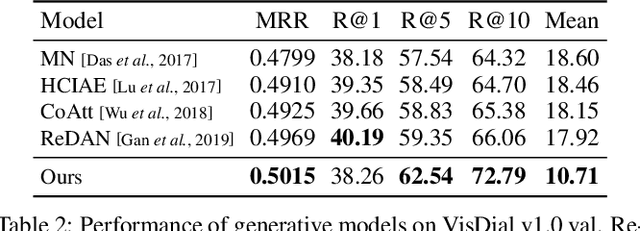
The key challenge of generative Visual Dialogue (VD) systems is to respond to human queries with informative answers in natural and contiguous conversation flow. Traditional Maximum Likelihood Estimation (MLE)-based methods only learn from positive responses but ignore the negative responses, and consequently tend to yield safe or generic responses. To address this issue, we propose a novel training scheme in conjunction with weighted likelihood estimation (WLE) method. Furthermore, an adaptive multi-modal reasoning module is designed, to accommodate various dialogue scenarios automatically and select relevant information accordingly. The experimental results on the VisDial benchmark demonstrate the superiority of our proposed algorithm over other state-of-the-art approaches, with an improvement of 5.81% on recall@10.
A Fully Convolutional Tri-branch Network for Domain Adaptation
Feb 27, 2018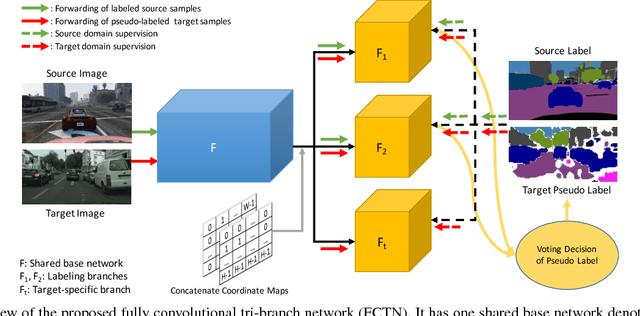
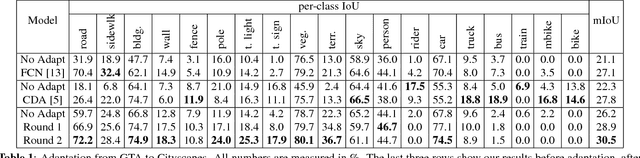


A domain adaptation method for urban scene segmentation is proposed in this work. We develop a fully convolutional tri-branch network, where two branches assign pseudo labels to images in the unlabeled target domain while the third branch is trained with supervision based on images in the pseudo-labeled target domain. The re-labeling and re-training processes alternate. With this design, the tri-branch network learns target-specific discriminative representations progressively and, as a result, the cross-domain capability of the segmenter improves. We evaluate the proposed network on large-scale domain adaptation experiments using both synthetic (GTA) and real (Cityscapes) images. It is shown that our solution achieves the state-of-the-art performance and it outperforms previous methods by a significant margin.