 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoundary-sensitive Network for Portrait Segmentation
Apr 09, 2018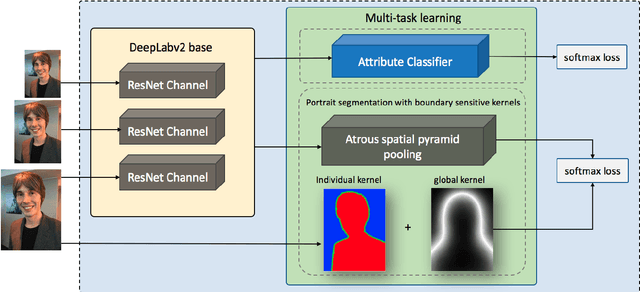



Compared to the general semantic segmentation problem, portrait segmentation has higher precision requirement on boundary area. However, this problem has not been well studied in previous works. In this paper, we propose a boundary-sensitive deep neural network (BSN) for portrait segmentation. BSN introduces three novel techniques. First, an individual boundary-sensitive kernel is proposed by dilating the contour line and assigning the boundary pixels with multi-class labels. Second, a global boundary-sensitive kernel is employed as a position sensitive prior to further constrain the overall shape of the segmentation map. Third, we train a boundary-sensitive attribute classifier jointly with the segmentation network to reinforce the network with semantic boundary shape information. We have evaluated BSN on the current largest public portrait segmentation dataset, i.e, the PFCN dataset, as well as the portrait images collected from other three popular image segmentation datasets: COCO, COCO-Stuff, and PASCAL VOC. Our method achieves the superior quantitative and qualitative performance over state-of-the-arts on all the datasets, especially on the boundary area.
dMath: Distributed Linear Algebra for DL
Nov 19, 2016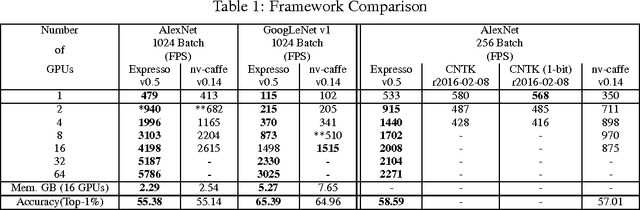
The paper presents a parallel math library, dMath, that demonstrates leading scaling when using intranode, internode, and hybrid-parallelism for deep learning (DL). dMath provides easy-to-use distributed primitives and a variety of domain-specific algorithms including matrix multiplication, convolutions, and others allowing for rapid development of scalable applications like deep neural networks (DNNs). Persistent data stored in GPU memory and advanced memory management techniques avoid costly transfers between host and device. dMath delivers performance, portability, and productivity to its specific domain of support.
dMath: A Scalable Linear Algebra and Math Library for Heterogeneous GP-GPU Architectures
Apr 05, 2016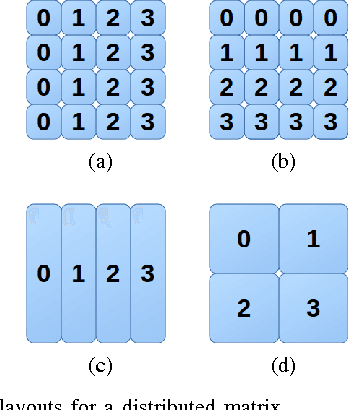
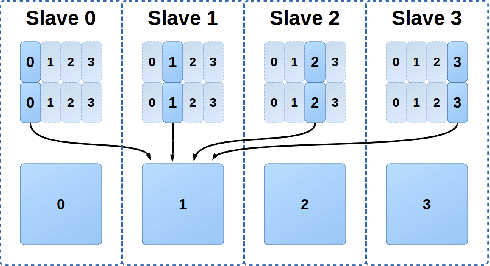
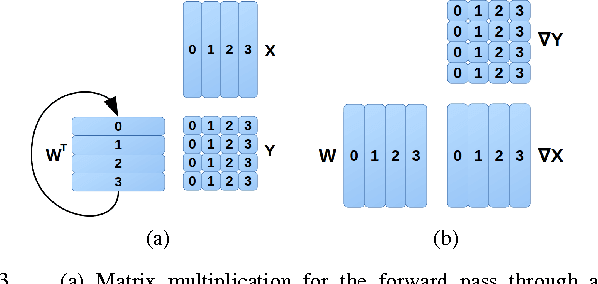
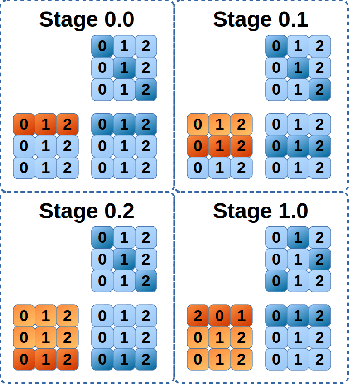
A new scalable parallel math library, dMath, is presented in this paper that demonstrates leading scaling when using intranode, or internode, hybrid-parallelism for deep-learning. dMath provides easy-to-use distributed base primitives and a variety of domain-specific algorithms. These include matrix multiplication, convolutions, and others allowing for rapid development of highly scalable applications, including Deep Neural Networks (DNN), whereas previously one was restricted to libraries that provided effective primitives for only a single GPU, like Nvidia cublas and cudnn or DNN primitives from Nervana neon framework. Development of HPC software is difficult, labor-intensive work, requiring a unique skill set. dMath allows a wide range of developers to utilize parallel and distributed hardware easily. One contribution of this approach is that data is stored persistently on the GPU hardware, avoiding costly transfers between host and device. Advanced memory management techniques are utilized, including caching of transferred data and memory reuse through pooling. A key contribution of dMath is that it delivers performance, portability, and productivity to its specific domain of support. It enables algorithm and application programmers to quickly solve problems without managing the significant complexity associated with multi-level parallelism.