 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatient-Centered Summarization Framework for AI Clinical Summarization: A Mixed-Methods Design
Oct 31, 2025Large Language Models (LLMs) are increasingly demonstrating the potential to reach human-level performance in generating clinical summaries from patient-clinician conversations. However, these summaries often focus on patients' biology rather than their preferences, values, wishes, and concerns. To achieve patient-centered care, we propose a new standard for Artificial Intelligence (AI) clinical summarization tasks: Patient-Centered Summaries (PCS). Our objective was to develop a framework to generate PCS that capture patient values and ensure clinical utility and to assess whether current open-source LLMs can achieve human-level performance in this task. We used a mixed-methods process. Two Patient and Public Involvement groups (10 patients and 8 clinicians) in the United Kingdom participated in semi-structured interviews exploring what personal and contextual information should be included in clinical summaries and how it should be structured for clinical use. Findings informed annotation guidelines used by eight clinicians to create gold-standard PCS from 88 atrial fibrillation consultations. Sixteen consultations were used to refine a prompt aligned with the guidelines. Five open-source LLMs (Llama-3.2-3B, Llama-3.1-8B, Mistral-8B, Gemma-3-4B, and Qwen3-8B) generated summaries for 72 consultations using zero-shot and few-shot prompting, evaluated with ROUGE-L, BERTScore, and qualitative metrics. Patients emphasized lifestyle routines, social support, recent stressors, and care values. Clinicians sought concise functional, psychosocial, and emotional context. The best zero-shot performance was achieved by Mistral-8B (ROUGE-L 0.189) and Llama-3.1-8B (BERTScore 0.673); the best few-shot by Llama-3.1-8B (ROUGE-L 0.206, BERTScore 0.683). Completeness and fluency were similar between experts and models, while correctness and patient-centeredness favored human PCS.
Connected Speech-Based Cognitive Assessment in Chinese and English
Jun 18, 2024



We present a novel benchmark dataset and prediction tasks for investigating approaches to assess cognitive function through analysis of connected speech. The dataset consists of speech samples and clinical information for speakers of Mandarin Chinese and English with different levels of cognitive impairment as well as individuals with normal cognition. These data have been carefully matched by age and sex by propensity score analysis to ensure balance and representativity in model training. The prediction tasks encompass mild cognitive impairment diagnosis and cognitive test score prediction. This framework was designed to encourage the development of approaches to speech-based cognitive assessment which generalise across languages. We illustrate it by presenting baseline prediction models that employ language-agnostic and comparable features for diagnosis and cognitive test score prediction. The models achieved unweighted average recall was 59.2% in diagnosis, and root mean squared error of 2.89 in score prediction.
A Frame-based Attention Interpretation Method for Relevant Acoustic Feature Extraction in Long Speech Depression Detection
Jun 07, 2024



Speech-based depression detection tools could help early screening of depression. Here, we address two issues that may hinder the clinical practicality of such tools: segment-level labelling noise and a lack of model interpretability. We propose a speech-level Audio Spectrogram Transformer to avoid segment-level labelling. We observe that the proposed model significantly outperforms a segment-level model, providing evidence for the presence of segment-level labelling noise in audio modality and the advantage of longer-duration speech analysis for depression detection. We introduce a frame-based attention interpretation method to extract acoustic features from prediction-relevant waveform signals for interpretation by clinicians. Through interpretation, we observe that the proposed model identifies reduced loudness and F0 as relevant signals of depression, which aligns with the speech characteristics of depressed patients documented in clinical studies.
Hierarchical attention interpretation: an interpretable speech-level transformer for bi-modal depression detection
Sep 23, 2023Depression is a common mental disorder. Automatic depression detection tools using speech, enabled by machine learning, help early screening of depression. This paper addresses two limitations that may hinder the clinical implementations of such tools: noise resulting from segment-level labelling and a lack of model interpretability. We propose a bi-modal speech-level transformer to avoid segment-level labelling and introduce a hierarchical interpretation approach to provide both speech-level and sentence-level interpretations, based on gradient-weighted attention maps derived from all attention layers to track interactions between input features. We show that the proposed model outperforms a model that learns at a segment level ($p$=0.854, $r$=0.947, $F1$=0.947 compared to $p$=0.732, $r$=0.808, $F1$=0.768). For model interpretation, using one true positive sample, we show which sentences within a given speech are most relevant to depression detection; and which text tokens and Mel-spectrogram regions within these sentences are most relevant to depression detection. These interpretations allow clinicians to verify the validity of predictions made by depression detection tools, promoting their clinical implementations.
Causally Linking Health Application Data and Personal Information Management Tools
Aug 11, 2023
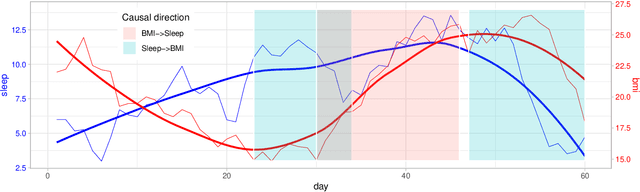

The proliferation of consumer health devices such as smart watches, sleep monitors, smart scales, etc, in many countries, has not only led to growing interest in health monitoring, but also to the development of a countless number of ``smart'' applications to support the exploration of such data by members of the general public, sometimes with integration into professional health services. While a variety of health data streams has been made available by such devices to users, these streams are often presented as separate time-series visualizations, in which the potential relationships between health variables are not explicitly made visible. Furthermore, despite the fact that other aspects of life, such as work and social connectivity, have become increasingly digitised, health and well-being applications make little use of the potentially useful contextual information provided by widely used personal information management tools, such as shared calendar and email systems. This paper presents a framework for the integration of these diverse data sources, analytic and visualization tools, with inference methods and graphical user interfaces to help users by highlighting causal connections among such time-series.
Multilingual Alzheimer's Dementia Recognition through Spontaneous Speech: a Signal Processing Grand Challenge
Jan 13, 2023This Signal Processing Grand Challenge (SPGC) targets a difficult automatic prediction problem of societal and medical relevance, namely, the detection of Alzheimer's Dementia (AD). Participants were invited to employ signal processing and machine learning methods to create predictive models based on spontaneous speech data. The Challenge has been designed to assess the extent to which predictive models built based on speech in one language (English) generalise to another language (Greek). To the best of our knowledge no work has investigated acoustic features of the speech signal in multilingual AD detection. Our baseline system used conventional machine learning algorithms with Active Data Representation of acoustic features, achieving accuracy of 73.91% on AD detection, and 4.95 root mean squared error on cognitive score prediction.
Computational linguistics and Natural Language Processing
Jun 14, 2022
This chapter provides an introduction to computational linguistics methods, with focus on their applications to the practice and study of translation. It covers computational models, methods and tools for collection, storage, indexing and analysis of linguistic data in the context of translation, and discusses the main methodological issues and challenges in this field. While an exhaustive review of existing computational linguistics methods and tools is beyond the scope of this chapter, we describe the most representative approaches, and illustrate them with descriptions of typical applications.
* This is the unedited author's copy of a text which appeared as a chapter in "The Routledge Handbook of Translation and Methodology'', edited by F Zanettin and C Rundle (2022)
Detecting cognitive decline using speech only: The ADReSSo Challenge
Mar 23, 2021Building on the success of the ADReSS Challenge at Interspeech 2020, which attracted the participation of 34 teams from across the world, the ADReSSo Challenge targets three difficult automatic prediction problems of societal and medical relevance, namely: detection of Alzheimer's Dementia, inference of cognitive testing scores, and prediction of cognitive decline. This paper presents these prediction tasks in detail, describes the datasets used, and reports the results of the baseline classification and regression models we developed for each task. A combination of acoustic and linguistic features extracted directly from audio recordings, without human intervention, yielded a baseline accuracy of 78.87% for the AD classification task, an MMSE prediction root mean squared (RMSE) error of 5.28, and 68.75% accuracy for the cognitive decline prediction task.
Artificial Intelligence, speech and language processing approaches to monitoring Alzheimer's Disease: a systematic review
Oct 12, 2020



Language is a valuable source of clinical information in Alzheimer's Disease, as it declines concurrently with neurodegeneration. Consequently, speech and language data have been extensively studied in connection with its diagnosis. This paper summarises current findings on the use of artificial intelligence, speech and language processing to predict cognitive decline in the context of Alzheimer's Disease, detailing current research procedures, highlighting their limitations and suggesting strategies to address them. We conducted a systematic review of original research between 2000 and 2019, registered in PROSPERO (reference CRD42018116606). An interdisciplinary search covered six databases on engineering (ACM and IEEE), psychology (PsycINFO), medicine (PubMed and Embase) and Web of Science. Bibliographies of relevant papers were screened until December 2019. From 3,654 search results 51 articles were selected against the eligibility criteria. Four tables summarise their findings: study details (aim, population, interventions, comparisons, methods and outcomes), data details (size, type, modalities, annotation, balance, availability and language of study), methodology (pre-processing, feature generation, machine learning, evaluation and results) and clinical applicability (research implications, clinical potential, risk of bias and strengths/limitations). While promising results are reported across nearly all 51 studies, very few have been implemented in clinical research or practice. We concluded that the main limitations of the field are poor standardisation, limited comparability of results, and a degree of disconnect between study aims and clinical applications. Attempts to close these gaps should support translation of future research into clinical practice.
AttViz: Online exploration of self-attention for transparent neural language modeling
May 12, 2020
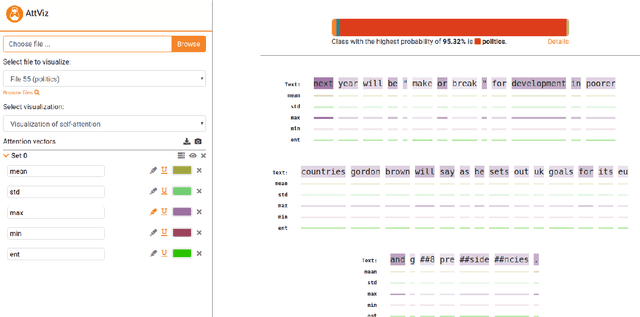

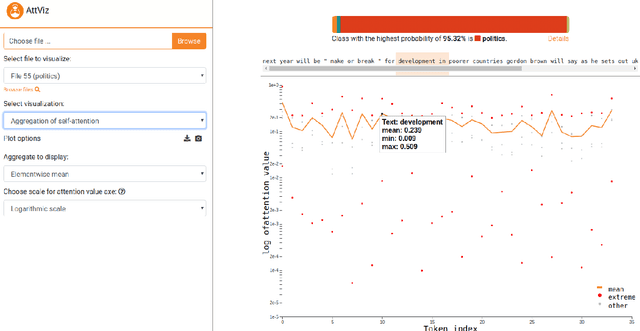
Neural language models are becoming the prevailing methodology for the tasks of query answering, text classification, disambiguation, completion and translation. Commonly comprised of hundreds of millions of parameters, these neural network models offer state-of-the-art performance at the cost of interpretability; humans are no longer capable of tracing and understanding how decisions are being made. The attention mechanism, introduced initially for the task of translation, has been successfully adopted for other language-related tasks. We propose AttViz, an online toolkit for exploration of self-attention---real values associated with individual text tokens. We show how existing deep learning pipelines can produce outputs suitable for AttViz, offering novel visualizations of the attention heads and their aggregations with minimal effort, online. We show on examples of news segments how the proposed system can be used to inspect and potentially better understand what a model has learned (or emphasized).