 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFire Together Wire Together: A Dynamic Pruning Approach with Self-Supervised Mask Prediction
Nov 05, 2021

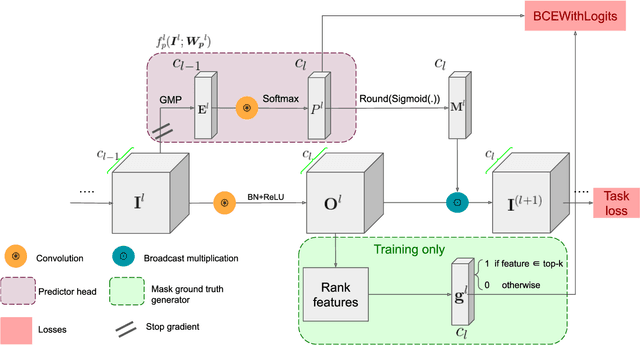

Dynamic model pruning is a recent direction that allows for the inference of a different sub-network for each input sample during deployment. However, current dynamic methods rely on learning a continuous channel gating through regularization by inducing sparsity loss. This formulation introduces complexity in balancing different losses (e.g task loss, regularization loss). In addition, regularization based methods lack transparent tradeoff hyperparameter selection to realize computational budget. Our contribution is two-fold: 1) decoupled task and pruning training. 2) Simple hyperparameter selection that enables FLOPs reduction estimation before training. Inspired by the Hebbian theory in Neuroscience: "neurons that fire together wire together", we propose to predict a mask to process k filters in a layer based on the activation of its previous layer. We pose the problem as a self-supervised binary classification problem. Each mask predictor module is trained to predict if the log-likelihood for each filter in the current layer belongs to the top-k activated filters. The value k is dynamically estimated for each input based on a novel criterion using the mass of heatmaps. We show experiments on several neural architectures, such as VGG, ResNet and MobileNet on CIFAR and ImageNet datasets. On CIFAR, we reach similar accuracy to SOTA methods with 15% and 24% higher FLOPs reduction. Similarly in ImageNet, we achieve lower drop in accuracy with up to 13% improvement in FLOPs reduction.
To filter prune, or to layer prune, that is the question
Jul 11, 2020

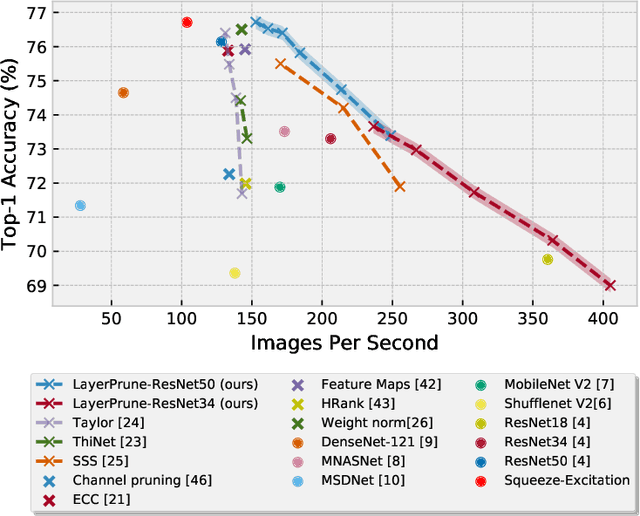
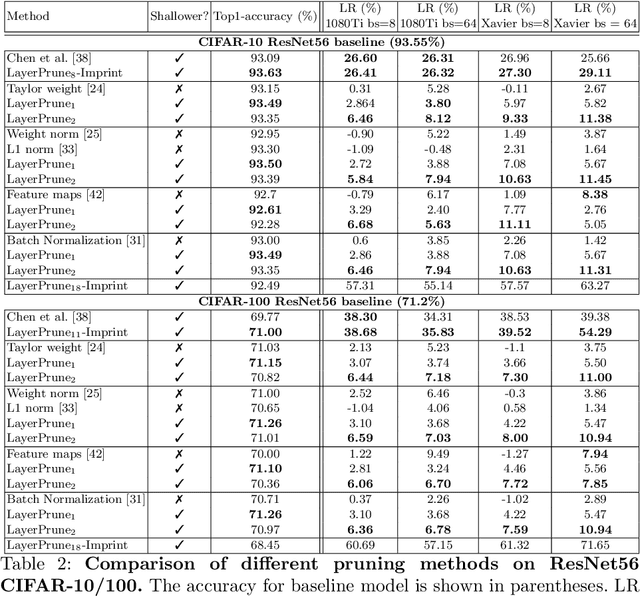
Recent advances in pruning of neural networks have made it possible to remove a large number of filters or weights without any perceptible drop in accuracy. The number of parameters and that of FLOPs are usually the reported metrics to measure the quality of the pruned models. However, the gain in speed for these pruned methods is often overlooked in the literature due to the complex nature of latency measurements. In this paper, we show the limitation of filter pruning methods in terms of latency reduction and propose LayerPrune framework. LayerPrune presents set of layer pruning methods based on different criteria that achieve higher latency reduction than filter pruning methods on similar accuracy. The advantage of layer pruning over filter pruning in terms of latency reduction is a result of the fact that the former is not constrained by the original model's depth and thus allows for a larger range of latency reduction. For each filter pruning method we examined, we use the same filter importance criterion to calculate a per-layer importance score in one-shot. We then prune the least important layers and fine-tune the shallower model which obtains comparable or better accuracy than its filter-based pruning counterpart. This one-shot process allows to remove layers from single path networks like VGG before fine-tuning, unlike in iterative filter pruning, a minimum number of filters per layer is required to allow for data flow which constraint the search space. To the best of our knowledge, we are the first to examine the effect of pruning methods on latency metric instead of FLOPs for multiple networks, datasets and hardware targets. LayerPrune also outperforms handcrafted architectures such as Shufflenet, MobileNet, MNASNet and ResNet18 by 7.3%, 4.6%, 2.8% and 0.5% respectively on similar latency budget on ImageNet dataset.
Lightweight Monocular Depth Estimation Model by Joint End-to-End Filter pruning
May 13, 2019
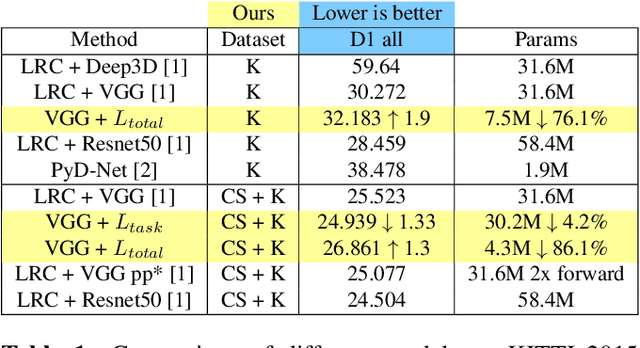

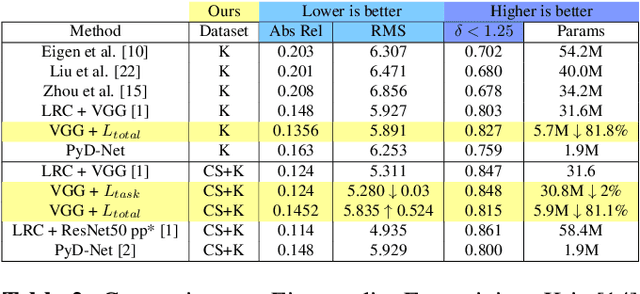
Convolutional neural networks (CNNs) have emerged as the state-of-the-art in multiple vision tasks including depth estimation. However, memory and computing power requirements remain as challenges to be tackled in these models. Monocular depth estimation has significant use in robotics and virtual reality that requires deployment on low-end devices. Training a small model from scratch results in a significant drop in accuracy and it does not benefit from pre-trained large models. Motivated by the literature of model pruning, we propose a lightweight monocular depth model obtained from a large trained model. This is achieved by removing the least important features with a novel joint end-to-end filter pruning. We propose to learn a binary mask for each filter to decide whether to drop the filter or not. These masks are trained jointly to exploit relations between filters at different layers as well as redundancy within the same layer. We show that we can achieve around 5x compression rate with small drop in accuracy on the KITTI driving dataset. We also show that masking can improve accuracy over the baseline with fewer parameters, even without enforcing compression loss.
Deep Semantic Segmentation for Automated Driving: Taxonomy, Roadmap and Challenges
Aug 03, 2017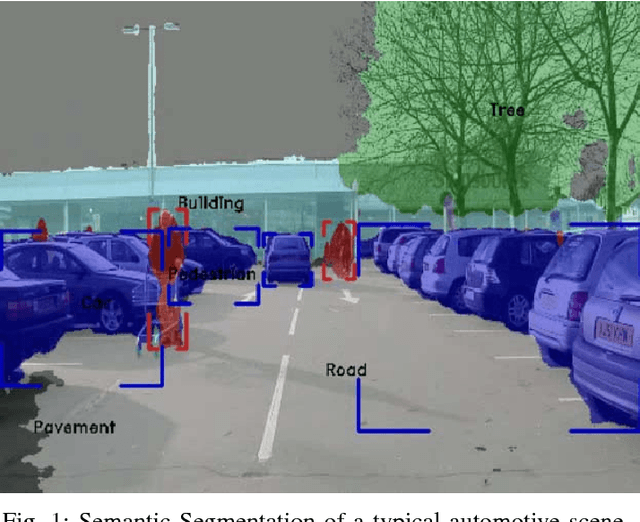



Semantic segmentation was seen as a challenging computer vision problem few years ago. Due to recent advancements in deep learning, relatively accurate solutions are now possible for its use in automated driving. In this paper, the semantic segmentation problem is explored from the perspective of automated driving. Most of the current semantic segmentation algorithms are designed for generic images and do not incorporate prior structure and end goal for automated driving. First, the paper begins with a generic taxonomic survey of semantic segmentation algorithms and then discusses how it fits in the context of automated driving. Second, the particular challenges of deploying it into a safety system which needs high level of accuracy and robustness are listed. Third, different alternatives instead of using an independent semantic segmentation module are explored. Finally, an empirical evaluation of various semantic segmentation architectures was performed on CamVid dataset in terms of accuracy and speed. This paper is a preliminary shorter version of a more detailed survey which is work in progress.