 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFire Together Wire Together: A Dynamic Pruning Approach with Self-Supervised Mask Prediction
Paper and Code


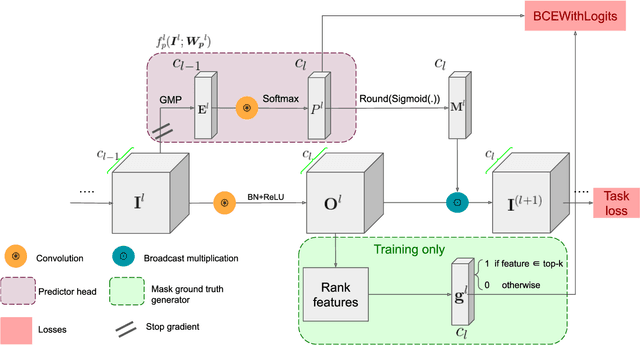

Dynamic model pruning is a recent direction that allows for the inference of a different sub-network for each input sample during deployment. However, current dynamic methods rely on learning a continuous channel gating through regularization by inducing sparsity loss. This formulation introduces complexity in balancing different losses (e.g task loss, regularization loss). In addition, regularization based methods lack transparent tradeoff hyperparameter selection to realize computational budget. Our contribution is two-fold: 1) decoupled task and pruning training. 2) Simple hyperparameter selection that enables FLOPs reduction estimation before training. Inspired by the Hebbian theory in Neuroscience: "neurons that fire together wire together", we propose to predict a mask to process k filters in a layer based on the activation of its previous layer. We pose the problem as a self-supervised binary classification problem. Each mask predictor module is trained to predict if the log-likelihood for each filter in the current layer belongs to the top-k activated filters. The value k is dynamically estimated for each input based on a novel criterion using the mass of heatmaps. We show experiments on several neural architectures, such as VGG, ResNet and MobileNet on CIFAR and ImageNet datasets. On CIFAR, we reach similar accuracy to SOTA methods with 15% and 24% higher FLOPs reduction. Similarly in ImageNet, we achieve lower drop in accuracy with up to 13% improvement in FLOPs reduction.