 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
A Constrained Coupled Matrix-Tensor Factorization for Learning Time-evolving and Emerging Topics
Jun 30, 2018
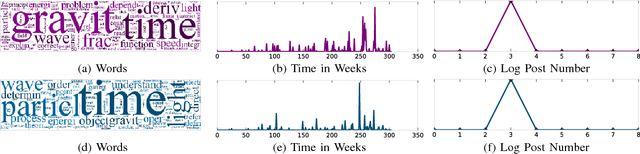
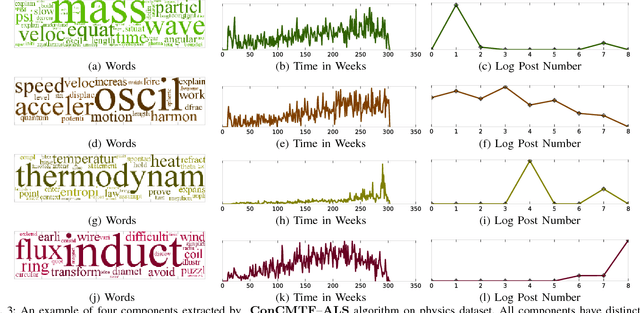
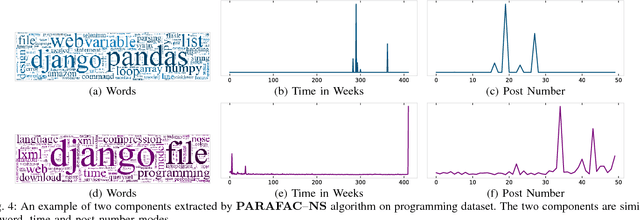
Topic discovery has witnessed a significant growth as a field of data mining at large. In particular, time-evolving topic discovery, where the evolution of a topic is taken into account has been instrumental in understanding the historical context of an emerging topic in a dynamic corpus. Traditionally, time-evolving topic discovery has focused on this notion of time. However, especially in settings where content is contributed by a community or a crowd, an orthogonal notion of time is the one that pertains to the level of expertise of the content creator: the more experienced the creator, the more advanced the topic. In this paper, we propose a novel time-evolving topic discovery method which, in addition to the extracted topics, is able to identify the evolution of that topic over time, as well as the level of difficulty of that topic, as it is inferred by the level of expertise of its main contributors. Our method is based on a novel formulation of Constrained Coupled Matrix-Tensor Factorization, which adopts constraints well-motivated for, and, as we demonstrate, are essential for high-quality topic discovery. We qualitatively evaluate our approach using real data from the Physics and also Programming Stack Exchange forum, and we were able to identify topics of varying levels of difficulty which can be linked to external events, such as the announcement of gravitational waves by the LIGO lab in Physics forum. We provide a quantitative evaluation of our method by conducting a user study where experts were asked to judge the coherence and quality of the extracted topics. Finally, our proposed method has implications for automatic curriculum design using the extracted topics, where the notion of the level of difficulty is necessary for the proper modeling of prerequisites and advanced concepts.
Team Formation for Scheduling Educational Material in Massive Online Classes
Mar 26, 2017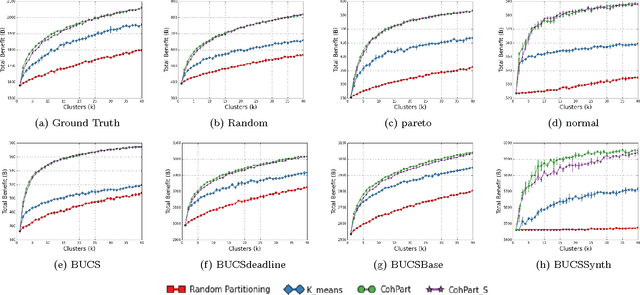
Whether teaching in a classroom or a Massive Online Open Course it is crucial to present the material in a way that benefits the audience as a whole. We identify two important tasks to solve towards this objective, 1 group students so that they can maximally benefit from peer interaction and 2 find an optimal schedule of the educational material for each group. Thus, in this paper, we solve the problem of team formation and content scheduling for education. Given a time frame d, a set of students S with their required need to learn different activities T and given k as the number of desired groups, we study the problem of finding k group of students. The goal is to teach students within time frame d such that their potential for learning is maximized and find the best schedule for each group. We show this problem to be NP-hard and develop a polynomial algorithm for it. We show our algorithm to be effective both on synthetic as well as a real data set. For our experiments, we use real data on students' grades in a Computer Science department. As part of our contribution, we release a semi-synthetic dataset that mimics the properties of the real data.