 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Discovery with Stage Variables for Health Time Series
May 05, 2023Using observational data to learn causal relationships is essential when randomized experiments are not possible, such as in healthcare. Discovering causal relationships in time-series health data is even more challenging when relationships change over the course of a disease, such as medications that are most effective early on or for individuals with severe disease. Stage variables such as weeks of pregnancy, disease stages, or biomarkers like HbA1c, can influence what causal relationships are true for a patient. However, causal inference within each stage is often not possible due to limited amounts of data, and combining all data risks incorrect or missed inferences. To address this, we propose Causal Discovery with Stage Variables (CDSV), which uses stage variables to reweight data from multiple time-series while accounting for different causal relationships in each stage. In simulated data, CDSV discovers more causes with fewer false discoveries compared to baselines, in eICU it has a lower FDR than baselines, and in MIMIC-III it discovers more clinically relevant causes of high blood pressure.
Collaborative Graph Learning with Auxiliary Text for Temporal Event Prediction in Healthcare
May 16, 2021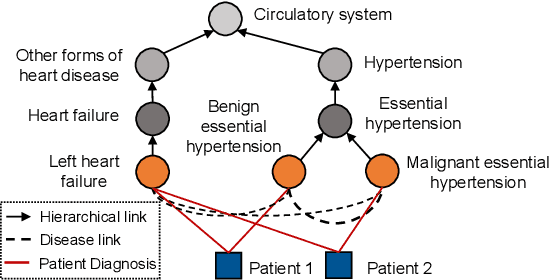

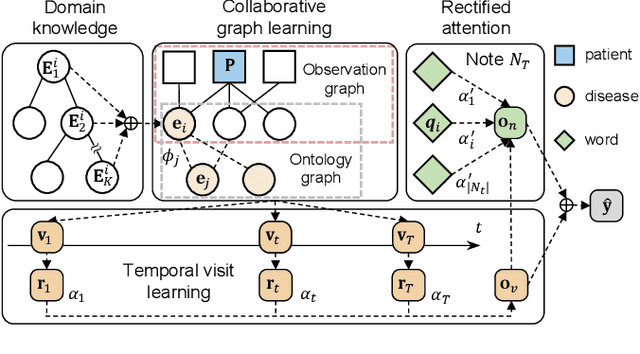
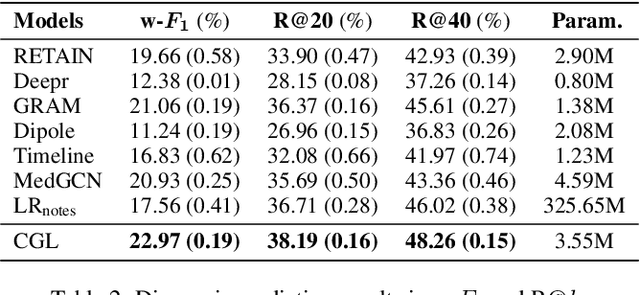
Accurate and explainable health event predictions are becoming crucial for healthcare providers to develop care plans for patients. The availability of electronic health records (EHR) has enabled machine learning advances in providing these predictions. However, many deep learning based methods are not satisfactory in solving several key challenges: 1) effectively utilizing disease domain knowledge; 2) collaboratively learning representations of patients and diseases; and 3) incorporating unstructured text. To address these issues, we propose a collaborative graph learning model to explore patient-disease interactions and medical domain knowledge. Our solution is able to capture structural features of both patients and diseases. The proposed model also utilizes unstructured text data by employing an attention regulation strategy and then integrates attentive text features into a sequential learning process. We conduct extensive experiments on two important healthcare problems to show the competitive prediction performance of the proposed method compared with various state-of-the-art models. We also confirm the effectiveness of learned representations and model interpretability by a set of ablation and case studies.
Deep Learning for Multi-Scale Changepoint Detection in Multivariate Time Series
May 16, 2019
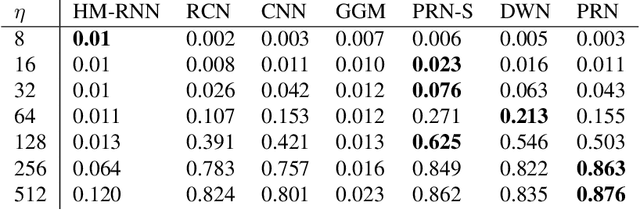
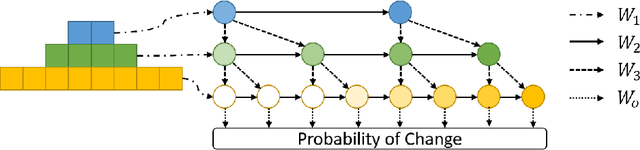
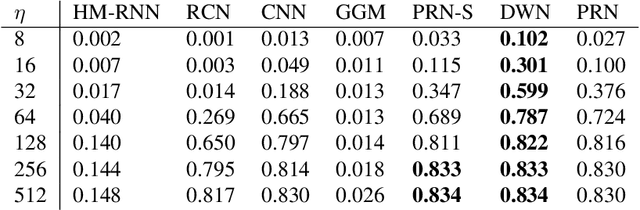
Many real-world time series, such as in health, have changepoints where the system's structure or parameters change. Since changepoints can indicate critical events such as onset of illness, it is highly important to detect them. However, existing methods for changepoint detection (CPD) often require user-specified models and cannot recognize changes that occur gradually or at multiple time-scales. To address both, we show how CPD can be treated as a supervised learning problem, and propose a new deep neural network architecture to efficiently identify both abrupt and gradual changes at multiple timescales from multivariate data. Our proposed pyramid recurrent neural network (PRN) provides scale-invariance using wavelets and pyramid analysis techniques from multi-scale signal processing. Through experiments on synthetic and real-world datasets, we show that PRN can detect abrupt and gradual changes with higher accuracy than the state of the art and can extrapolate to detect changepoints at novel scales not seen in training.
Proceedings 3rd Workshop on formal reasoning about Causation, Responsibility, and Explanations in Science and Technology
Jan 01, 2019The CREST 2018 workshop is the third in a series of workshops addressing formal approaches to reasoning about causation in systems engineering. The topic of formally identifying the cause(s) of specific events - usually some form of failures -, and explaining why they occurred, are increasingly in the focus of several, disjoint communities. The main objective of CREST is to bring together researchers and practitioners from industry and academia in order to enable discussions how explicit and implicit reasoning about causation is performed. A further objective is to link to the foundations of causal reasoning in the philosophy of sciences and to causal reasoning performed in other areas of computer science, engineering, and beyond.
The Temporal Logic of Causal Structures
May 09, 2012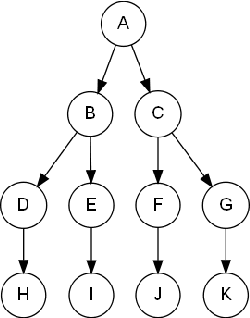
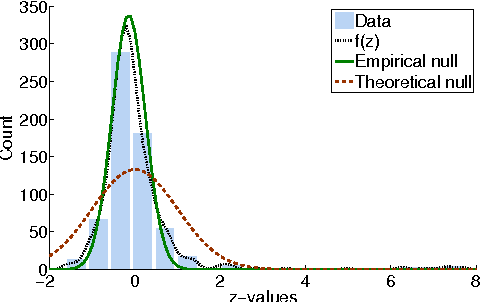
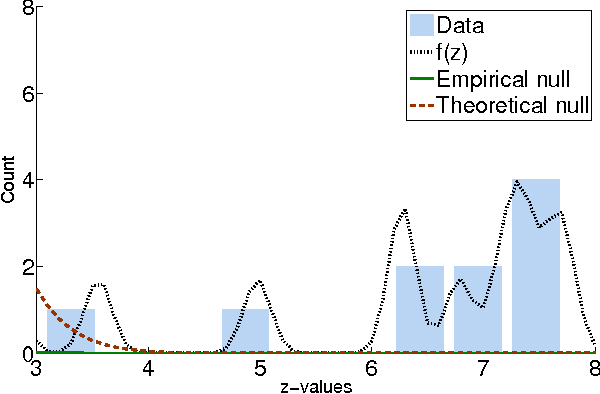
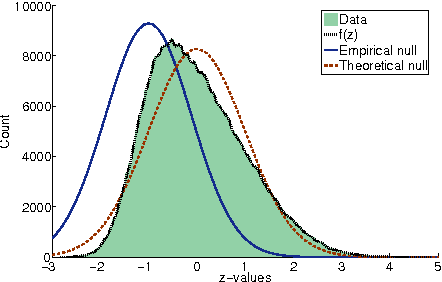
Computational analysis of time-course data with an underlying causal structure is needed in a variety of domains, including neural spike trains, stock price movements, and gene expression levels. However, it can be challenging to determine from just the numerical time course data alone what is coordinating the visible processes, to separate the underlying prima facie causes into genuine and spurious causes and to do so with a feasible computational complexity. For this purpose, we have been developing a novel algorithm based on a framework that combines notions of causality in philosophy with algorithmic approaches built on model checking and statistical techniques for multiple hypotheses testing. The causal relationships are described in terms of temporal logic formulae, reframing the inference problem in terms of model checking. The logic used, PCTL, allows description of both the time between cause and effect and the probability of this relationship being observed. We show that equipped with these causal formulae with their associated probabilities we may compute the average impact a cause makes to its effect and then discover statistically significant causes through the concepts of multiple hypothesis testing (treating each causal relationship as a hypothesis), and false discovery control. By exploring a well-chosen family of potentially all significant hypotheses with reasonably minimal description length, it is possible to tame the algorithm's computational complexity while exploring the nearly complete search-space of all prima facie causes. We have tested these ideas in a number of domains and illustrate them here with two examples.