 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Temporal Logic of Causal Structures
Paper and Code
May 09, 2012
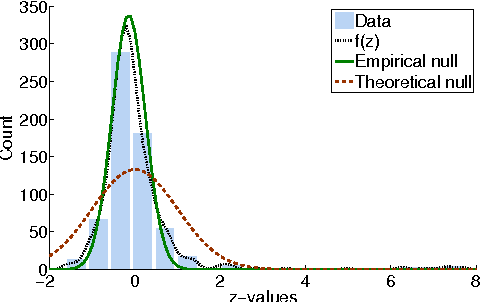
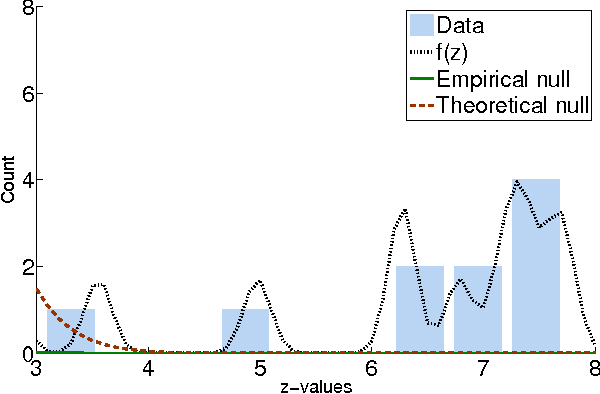
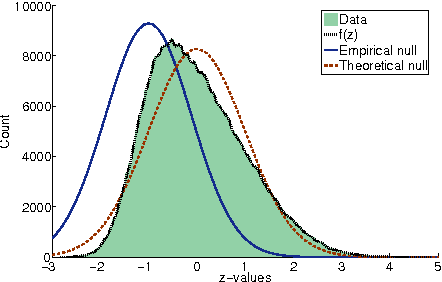
Computational analysis of time-course data with an underlying causal structure is needed in a variety of domains, including neural spike trains, stock price movements, and gene expression levels. However, it can be challenging to determine from just the numerical time course data alone what is coordinating the visible processes, to separate the underlying prima facie causes into genuine and spurious causes and to do so with a feasible computational complexity. For this purpose, we have been developing a novel algorithm based on a framework that combines notions of causality in philosophy with algorithmic approaches built on model checking and statistical techniques for multiple hypotheses testing. The causal relationships are described in terms of temporal logic formulae, reframing the inference problem in terms of model checking. The logic used, PCTL, allows description of both the time between cause and effect and the probability of this relationship being observed. We show that equipped with these causal formulae with their associated probabilities we may compute the average impact a cause makes to its effect and then discover statistically significant causes through the concepts of multiple hypothesis testing (treating each causal relationship as a hypothesis), and false discovery control. By exploring a well-chosen family of potentially all significant hypotheses with reasonably minimal description length, it is possible to tame the algorithm's computational complexity while exploring the nearly complete search-space of all prima facie causes. We have tested these ideas in a number of domains and illustrate them here with two examples.