 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFT-MoE: Sustainable-learning Mixture of Experts Model for Fault-Tolerant Computing with Multiple Tasks
Apr 29, 2025



Intelligent fault-tolerant (FT) computing has recently demonstrated significant advantages of predicting and diagnosing faults in advance, enabling reliable service delivery. However, due to heterogeneity of fault knowledge and complex dependence relationships of time series log data, existing deep learning-based FT algorithms further improve detection performance relying on single neural network model with difficulty. To this end, we propose FT-MoE, a sustainable-learning mixture-of-experts model for fault-tolerant computing with multiple tasks, which enables different parameters learning distinct fault knowledge to achieve high-reliability for service system. Firstly, we use decoder-based transformer models to obtain fault prototype vectors of decoupling long-distance dependencies. Followed by, we present a dual mixture of experts networks for high-accurate prediction for both fault detection and classification tasks. Then, we design a two-stage optimization scheme of offline training and online tuning, which allows that in operation FT-MoE can also keep learning to adapt to dynamic service environments. Finally, to verify the effectiveness of FT-MoE, we conduct extensive experiments on the FT benchmark. Experimental results show that FT-MoE achieves superior performance compared to the state-of-the-art methods. Code will be available upon publication.
Bi-Granularity Contrastive Learning for Post-Training in Few-Shot Scene
Jun 04, 2021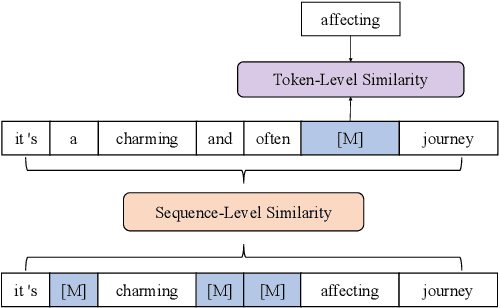
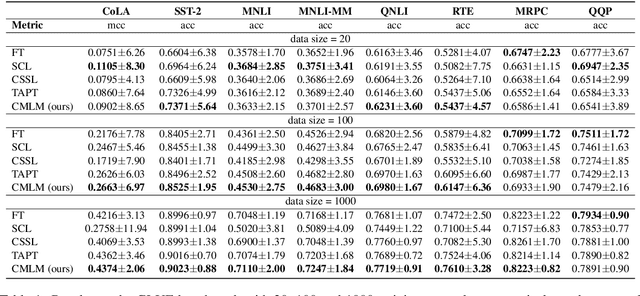
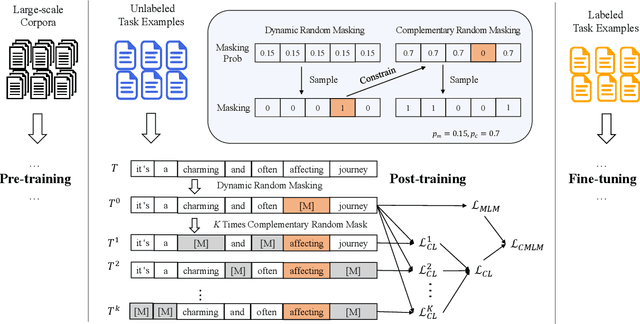
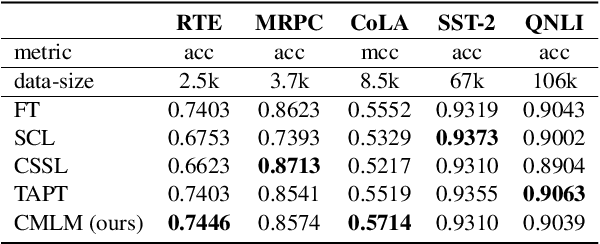
The major paradigm of applying a pre-trained language model to downstream tasks is to fine-tune it on labeled task data, which often suffers instability and low performance when the labeled examples are scarce.~One way to alleviate this problem is to apply post-training on unlabeled task data before fine-tuning, adapting the pre-trained model to target domains by contrastive learning that considers either token-level or sequence-level similarity. Inspired by the success of sequence masking, we argue that both token-level and sequence-level similarities can be captured with a pair of masked sequences.~Therefore, we propose complementary random masking (CRM) to generate a pair of masked sequences from an input sequence for sequence-level contrastive learning and then develop contrastive masked language modeling (CMLM) for post-training to integrate both token-level and sequence-level contrastive learnings.~Empirical results show that CMLM surpasses several recent post-training methods in few-shot settings without the need for data augmentation.
A Workload Adaptive Haptic Shared Control Scheme for Semi-Autonomous Driving
Mar 31, 2020
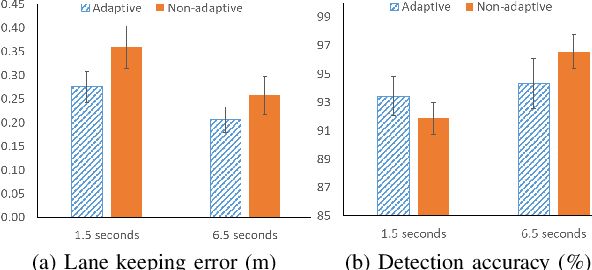
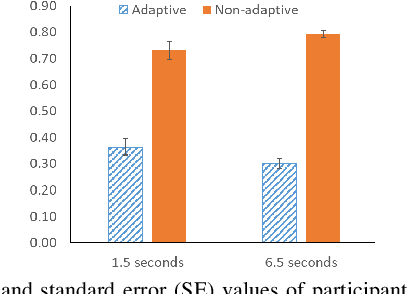
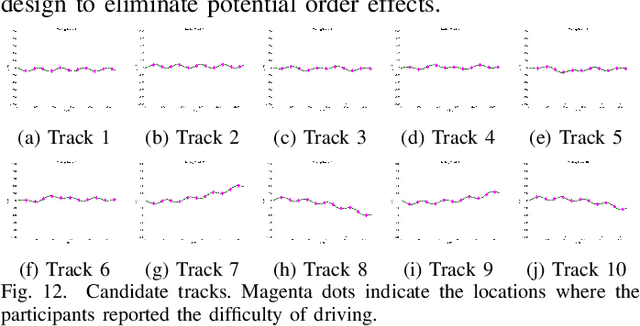
Haptic shared control is used to manage the control authority allocation between a human and an autonomous agent in semi-autonomous driving. Existing haptic shared control schemes, however, do not take full consideration of the human agent. To fill this research gap, this study presents a haptic shared control scheme that adapts to a human operator's workload, eyes on road and input torque in real-time. We conducted human-in-the-loop experiments with 24 participants. In the experiment, a human operator and an autonomy module for navigation shared the control of a simulated notional High Mobility Multipurpose Wheeled Vehicle (HMMWV) at a fixed speed. At the same time, the human operator performed a target detection task for surveillance. The autonomy could be either adaptive or non-adaptive to the above-mentioned human factors. Results indicate that the adaptive haptic control scheme resulted in significantly lower workload, higher trust in autonomy, better driving task performance and smaller control effort.
Multi-Task Regularization with Covariance Dictionary for Linear Classifiers
Oct 21, 2013
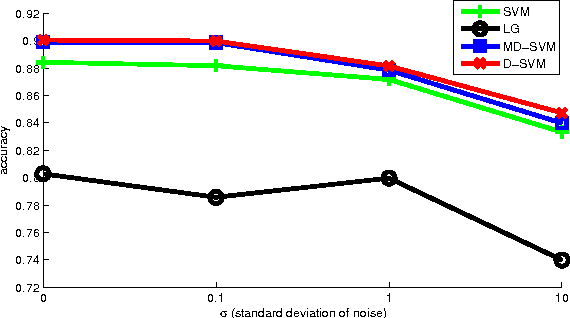


In this paper we propose a multi-task linear classifier learning problem called D-SVM (Dictionary SVM). D-SVM uses a dictionary of parameter covariance shared by all tasks to do multi-task knowledge transfer among different tasks. We formally define the learning problem of D-SVM and show two interpretations of this problem, from both the probabilistic and kernel perspectives. From the probabilistic perspective, we show that our learning formulation is actually a MAP estimation on all optimization variables. We also show its equivalence to a multiple kernel learning problem in which one is trying to find a re-weighting kernel for features from a dictionary of basis (despite the fact that only linear classifiers are learned). Finally, we describe an alternative optimization scheme to minimize the objective function and present empirical studies to valid our algorithm.