 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Entity Generation for End-to-End Task-Oriented Dialog
Sep 19, 2022
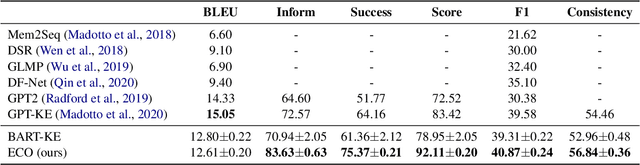
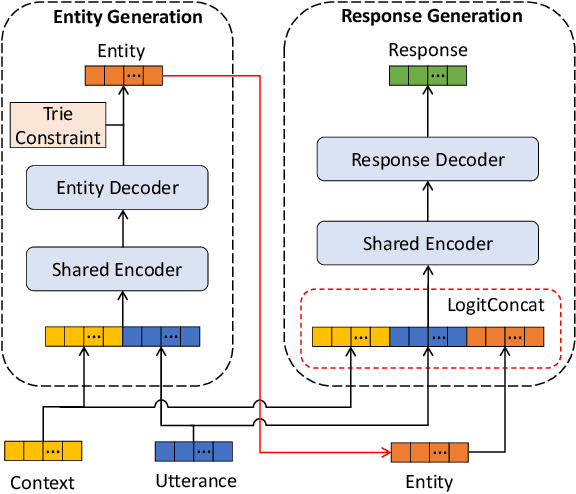
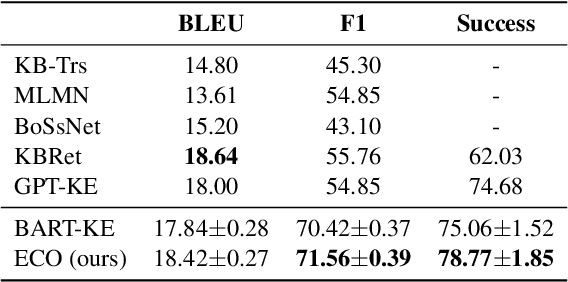
Task-oriented dialog (TOD) systems often require interaction with an external knowledge base to retrieve necessary entity (e.g., restaurant) information to support the response generation. Most current end-to-end TOD systems either retrieve the KB information explicitly or embed it into model parameters for implicit access.~While the former approach demands scanning the KB at each turn of response generation, which is inefficient when the KB scales up, the latter approach shows higher flexibility and efficiency. In either approach, the systems may generate a response with conflicting entity information. To address this issue, we propose to generate the entity autoregressively first and leverage it to guide the response generation in an end-to-end system. To ensure entity consistency, we impose a trie constraint on entity generation. We also introduce a logit concatenation strategy to facilitate gradient backpropagation for end-to-end training. Experiments on MultiWOZ 2.1 single and CAMREST show that our system can generate more high-quality and entity-consistent responses.
Bi-Granularity Contrastive Learning for Post-Training in Few-Shot Scene
Jun 04, 2021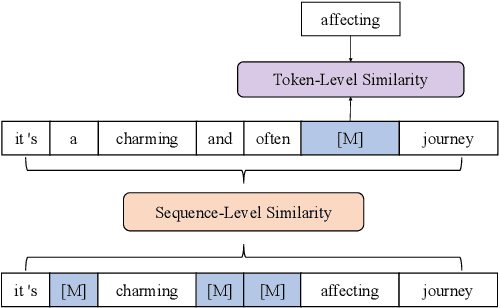
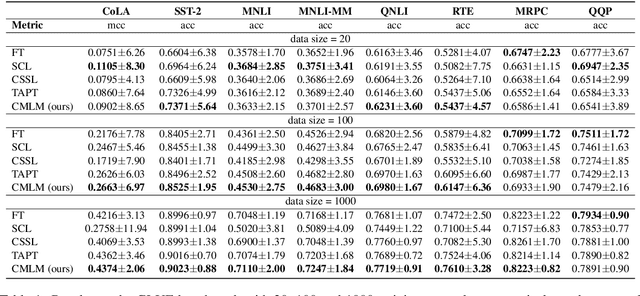
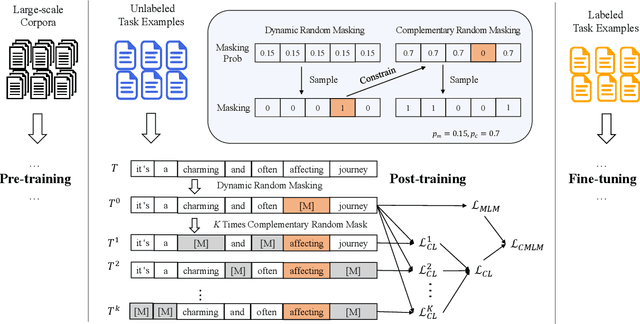
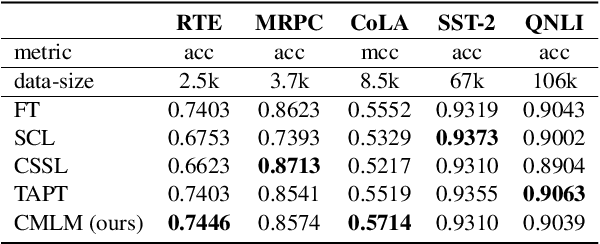
The major paradigm of applying a pre-trained language model to downstream tasks is to fine-tune it on labeled task data, which often suffers instability and low performance when the labeled examples are scarce.~One way to alleviate this problem is to apply post-training on unlabeled task data before fine-tuning, adapting the pre-trained model to target domains by contrastive learning that considers either token-level or sequence-level similarity. Inspired by the success of sequence masking, we argue that both token-level and sequence-level similarities can be captured with a pair of masked sequences.~Therefore, we propose complementary random masking (CRM) to generate a pair of masked sequences from an input sequence for sequence-level contrastive learning and then develop contrastive masked language modeling (CMLM) for post-training to integrate both token-level and sequence-level contrastive learnings.~Empirical results show that CMLM surpasses several recent post-training methods in few-shot settings without the need for data augmentation.