 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-Granularity Contrastive Learning for Post-Training in Few-Shot Scene
Paper and Code
Jun 04, 2021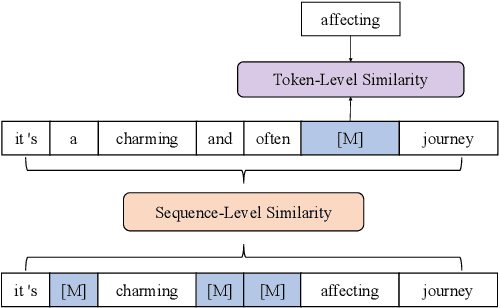
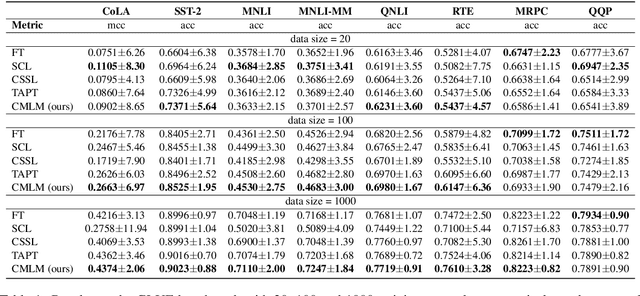
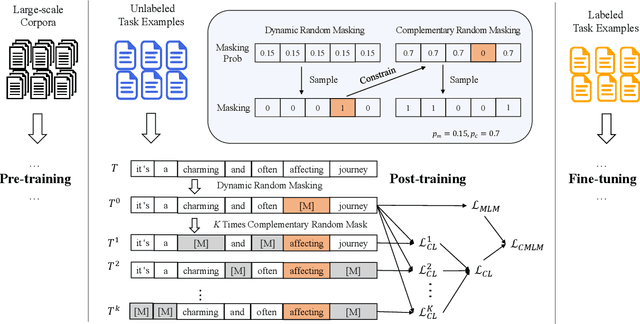
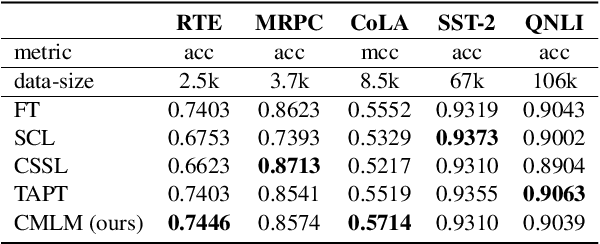
The major paradigm of applying a pre-trained language model to downstream tasks is to fine-tune it on labeled task data, which often suffers instability and low performance when the labeled examples are scarce.~One way to alleviate this problem is to apply post-training on unlabeled task data before fine-tuning, adapting the pre-trained model to target domains by contrastive learning that considers either token-level or sequence-level similarity. Inspired by the success of sequence masking, we argue that both token-level and sequence-level similarities can be captured with a pair of masked sequences.~Therefore, we propose complementary random masking (CRM) to generate a pair of masked sequences from an input sequence for sequence-level contrastive learning and then develop contrastive masked language modeling (CMLM) for post-training to integrate both token-level and sequence-level contrastive learnings.~Empirical results show that CMLM surpasses several recent post-training methods in few-shot settings without the need for data augmentation.